
HBase是一个分布式的、可扩展的、基于列的数据库系统。在Hadoop生态系统中,它属于NoSQL数据库的一类,类似于Google的Bigtable。HBase是基于Hadoop的HDFS存储系统构建的,具有高可用、高可靠性和高可扩展性等特点。
HBase数据库架构
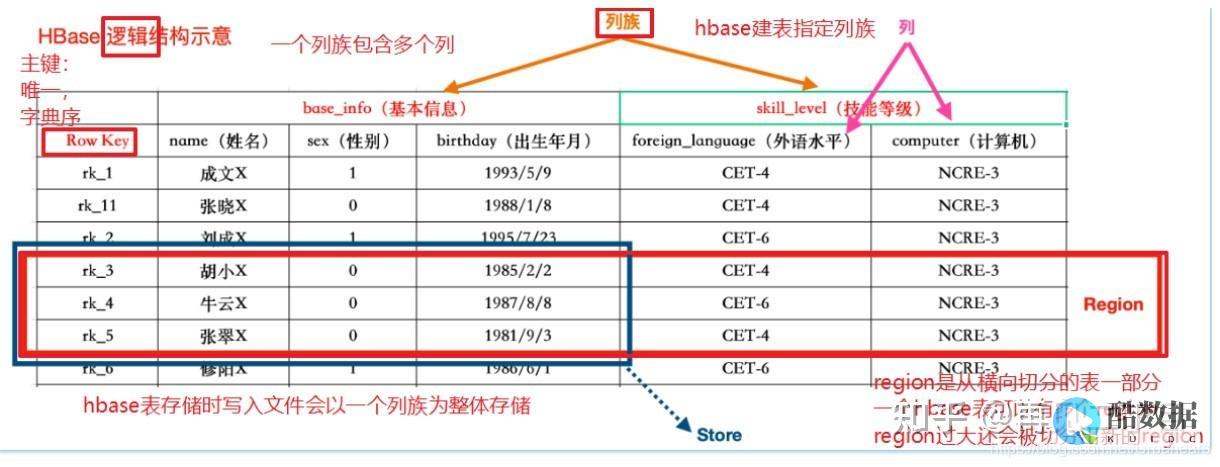
HBase数据库使用的是基于键值对的数据库结构,它的基本单元是一个表格。表格包含多个行和多个列,每一行有一个唯一的行键(rowkey),每个列都有一个独特的列标识符(column family:column qualifier)。在HBase中,列标识符也称为列限定符(column qualifier),它们一起构成了逻辑上的单元。逻辑单元可以使数据的存储和访问更加的简便和高效。在这个架构中,每一行都包含了所有的列的版本信息,这些版本根据时间戳来排序。
HBase与传统数据库的差异
传统的关系型数据库主要使用SQL作为查询语言,以及存储数据的表具有预定义的列和数据类型。而HBase是基于列的数据库技术,它不仅支持随机的数据插入和随机查询,还具有高度的可扩展性和灵活性。HBase使用java api进行操作,它支持多种数据类型,而且每个数据类型的数据存储形式可以自定义。这意味着,HBase可以轻松处理大量、短生命周期的数据。
HBase存储数据的方式
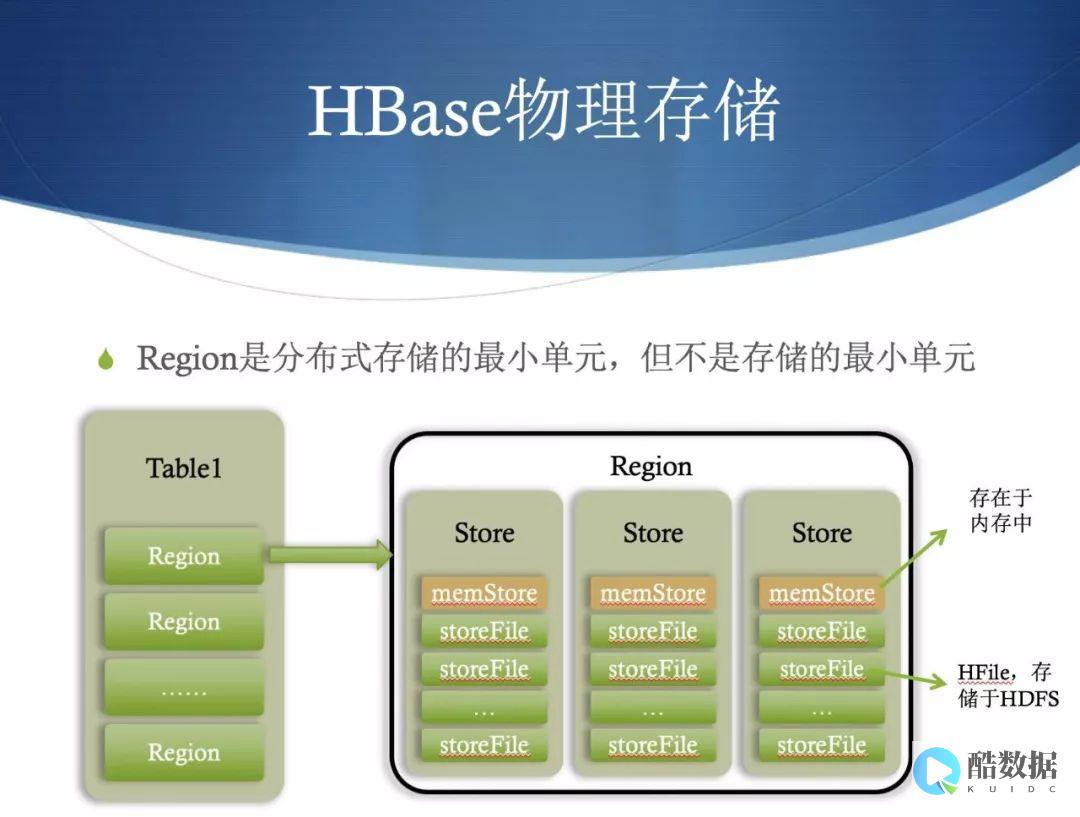
HBase将所有的数据存储在分布式文件系统HDFS中,其中HBase的数据是通过分布在不同 服务器 节点上的Region Server来负责的。一般来说,每个Region Server负责管理一个或多个HBase数据库的Region。HBase的数据被拆分为多个Region,每一个Region只能被一个Region Server管理。这个Region是通过行键范围进行划分的,确保了每个Region的行键连续。
HBase性能优化
当处理大规模的数据时,HBase往往会面临性能方面的挑战。为了使其能够更高效地工作,需要对性能进行优化。以下是一些重要的优化技术:
1. 预分区(Pre-Splitting)
预分区是一种预先将HBase的数据进行分片的优化技巧,可以将数据均匀地分布在集群中的所有节点上。
2. 常量时间访问(Constant Time Access)
HBase使用B树和堆结构来管理数据,这种数据结构能够保持常量时间的访问速度,因此在存储和访问数据时都非常快速。
3. 读写缓存(Read/Write Caching)
HBase支持读写缓存,这可以有效减少读写操作的延迟,并且可以提高HBase集群的读写性能。HBase的读写缓存分别由Region Server负责管理,每个Region都可以有自己的缓存。
HBase数据库是一个分布式、可扩展、基于列的数据库系统。由于其高可用、高可靠性和高可扩展性等特点,HBase越来越受到业界的关注。通过理解HBase的基本结构、与传统数据库的差异,我们可以更好地优化其性能。
相关问题拓展阅读:
HBase是什么?为什么要使用HBase?
HBase在产品中还包含了Jetty,在HBase启动时采用嵌入式的方式来启动Jetty,因此可以通过web界面对HBase进行管理和查看当前运行的一些状态,非常轻巧。为什么采用HBase?HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库.所谓非结构化数据存储就是说HBase是基于列的而不是基于行的模式,这样方面读写你的大数据内容。HBase是介于Map Entry(key & value)和DB Row之间的一种数据存储方式。就点有点类似于现在流行的Memcache,但不仅仅是简单的一个key对应一个 value,你很可能需要存储多个属性的数据结构,但没有传统数据库表中那么多的关联关系,这饥绝就是所谓的松散数据。简单来说,你在HBase中的表创建的可以看做是一张很大的表,而这个表的属性可以根据需求去动态增加,在HBase中没有表与表之间关联查询。你只需要 告诉你的数据存储到Hbase的那个column families 就可以了,不需要指定它的具体类型烂唯姿:char,varchar,int,tinyint,text等等。但是你需要注意HBase中不包含事务此类的功 能。Apache HBase 和Google Bigtable 有非常相似的地方,一个数据行拥有一个可选择的键和任意数量的列。表是疏松的存储的,因此用户可以给行定义各种不同的列,对山山于这样的功能在大项目中非常实用,可以简化设计和升级的成本。
hbase数据库结构的介绍就聊到这里吧,感谢你花时间阅读本站内容,更多关于hbase数据库结构,HBase数据库结构简介,HBase是什么?为什么要使用HBase?的信息别忘了在本站进行查找喔。
香港服务器首选树叶云,2H2G首月10元开通。树叶云(www.IDC.Net)提供简单好用,价格厚道的香港/美国云服务器和独立服务器。IDC+ISP+ICP资质。ARIN和APNIC会员。成熟技术团队15年行业经验。
什么是sql注入?
SQL是Structured Quevy Language(结构化查询语言)的缩写。 SQL是专为数据库而建立的操作命令集,是一种功能齐全的数据库语言。 在使用它时,只需要发出“做什么”的命令,“怎么做”是不用使用者考虑的。 SQL功能强大、简单易学、使用方便,已经成为了数据库操作的基础,并且现在几乎所有的数据库均支持SQL。 ##1 二、SQL数据库数据体系结构 SQL数据库的数据体系结构基本上是三级结构,但使用术语与传统关系模型术语不同。 在SQL中,关系模式(模式)称为“基本表”(base table);存储模式(内模式)称为“存储文件”(stored file);子模式(外模式)称为“视图”(view);元组称为“行”(row);属性称为“列”(column)。 名称对称如^a^: ##1 三、SQL语言的组成 在正式学习SQL语言之前,首先让我们对SQL语言有一个基本认识,介绍一下SQL语言的组成: 1.一个SQL数据库是表(Table)的集合,它由一个或多个SQL模式定义。 2.一个SQL表由行集构成,一行是列的序列(集合),每列与行对应一个数据项。 3.一个表或者是一个基本表或者是一个视图。 基本表是实际存储在数据库的表,而视图是由若干基本表或其他视图构成的表的定义。 4.一个基本表可以跨一个或多个存储文件,一个存储文件也可存放一个或多个基本表。 每个存储文件与外部存储上一个物理文件对应。 5.用户可以用SQL语句对视图和基本表进行查询等操作。 在用户角度来看,视图和基本表是一样的,没有区别,都是关系(表格)。 用户可以是应用程序,也可以是终端用户。 SQL语句可嵌入在宿主语言的程序中使用,宿主语言有FORTRAN,COBOL,PASCAL,PL/I,C和Ada语言等。 SQL用户也能作为独立的用户接口,供交互环境下的终端用户使用。 ##1 四、对数据库进行操作 SQL包括了所有对数据库的操作,主要是由4个部分组成: 1.数据定义:这一部分又称为“SQL DDL”,定义数据库的逻辑结构,包括定义数据库、基本表、视图和索引4部分。 2.数据操纵:这一部分又称为“SQL DML”,其中包括数据查询和数据更新两大类操作,其中数据更新又包括插入、删除和更新三种操作。 3.数据控制:对用户访问数据的控制有基本表和视图的授权、完整性规则的描述,事务控制语句等。 4.嵌入式SQL语言的使用规定:规定SQL语句在宿主语言的程序中使用的规则。 下面我们将分别介绍: ##2 (一)数据定义 SQL数据定义功能包括定义数据库、基本表、索引和视图。 首先,让我们了解一下SQL所提供的基本数据类型:(如^b^) 1.数据库的建立与删除 (1)建立数据库:数据库是一个包括了多个基本表的数据集,其语句格式为: CREATE DATABASE 〔其它参数〕 其中,在系统中必须是唯一的,不能重复,不然将导致数据存取失误。 〔其它参数〕因具体数据库实现系统不同而异。 例:要建立项目管理数据库(xmmanage),其语句应为: CREATE DATABASE xmmanage (2) 数据库的删除:将数据库及其全部内容从系统中删除。 其语句格式为:DROP DATABASE 例:删除项目管理数据库(xmmanage),其语句应为: DROP DATABASE xmmanage 2.基本表的定义及变更 本身独立存在的表称为基本表,在SQL语言中一个关系唯一对应一个基本表。 基本表的定义指建立基本关系模式,而变更则是指对数据库中已存在的基本表进行删除与修改
什么是sql语言,vb语言.vc语言?
SQL(STructured Query Language)是一种资料库查询和程式设计语言,用於存取资料以及查询、更新和管理关联式资料库系统。 美国国家标准局(ANSI)与国际标准化组织(ISO)已经制定了 SQL 标准。 ANSI 是一个美国工业和商业集团组织,发展美国的商务和通讯标准。 ANSI 同时也是 ISO 和 International Electrotechnical Commission(IEC)的成员之一。 ANSI 发布与国际标准组织相应的美国标准。 1992年,ISO 和 IEC 发布了 SQL 的国际标准,称为 SQL-92。 ANSI 随之发布的相应标准是 ANSI SQL-92。 ANSI SQL-92 有时被称为 ANSI SQL。 尽管不同的关联式资料库使用的 SQL 版本有一些差异,但大多数都遵循 ANSI SQL 标准。 SQL Server 使用 ANSI SQL-92 的扩展集,称为 T-SQL,其遵循 ANSI 制定的 SQL-92 标准。 SQL 语言包括两种主要程式设计语言类别的陈述式: 资料定义语言 (DDL)与资料操作语言 (DML)。 下面我们将介绍这两类语言。 VB与Basic是两种概念VB是Visual Basic的简写,是可视化的编程语言。 是一种简单、高效地开发应用软件的工具。 VB最早是微软从早期的BASIC语法继承而来,并加入了可视化的程序界面。 但现在的VB与Basic语言关系并不太大了,因为微软在升级VB的过程中,不断地给VB加入了更多的语法,改变旧的语法,并添加了面向对象程序设计等概念,可以说现在的VB程序与BASIC程序,除了加减乘除和For循环语句外,找不到其它相同特征。 如果说VB从BASIC语言身上继承了什么东西,那就是继承了它的简易性,它非常易学易用。 但是,如果单凭这种优点,微软是不会花那么多时间,来开创和更新VB语言的。 微软曾经开发的编程产品很多,但现在只留下了C#,VB,C++三种编程语言。 很多人可能很奇怪,网络上有很多人在学在用VB语言,但也有很多人在贬低VB语言,可以说VB是全世界最有争议的编程语言。 但是微软一直在力挺VB,将它从早期的简单语法,升级到VB2005这样强大的开发语言。 为什么?微软可以放弃许多其它不太有争议的编程语言,却一直不愿意放弃争议最大的VB语言。 通过分析微软的历史轨迹可以找到答案。 早期的C语言功能公认的强大,在当时的大型计算机软件开发尤其如此,但在开发企业商业软件时,却用处不大,在当时的小型和微型机市场上,最简单最不具有专业水平的BASIC语言却十分流行用于开发应用软件,微软就是从那时候发展起来的,最早的微软应用软件开发的所用的语言就是BASIC语言,它为微软成为日后的巨无霸立下了汗马功劳。 这一点也许让微软意识到,产品的成功,很大原因在于开发成本低,开发周期短,而BASIC语言无疑最具有这种潜力,所以微软一直力挺BASIC语言,对它进行了数不清次数的升级换代,让现在的VB2005已经完全脱胎换骨。 当然,今天的VB语言,我感觉它追求的目的与其它语言是有区别的,其它语言一般是追求功能的强大,不断地扩充语言语法。 而VB语言追求的,是软件开发的高效性,编程语言的易学性,然后才是语言的强大性。 所以,今天在应用软件开发市场上(排除非Windows软件),VB始终是最高效、开发成本最低的强大的开发工具。 以上是一个用C,C++,VB开发过不同企业应用软件的程序员感悟。 C语言是作为UNIX操作系统的主要使用语言。 由于UNIX操作系统的成功,现在C语言也得到了广泛的使用。 C语言是有经验的软件工程师设计的,它具有很强的功能,以及高度的灵活性。 它和其他的结构化语言一样,能提供丰富的数据类型、广泛使用的指针以及—组很丰富的计算和数据处理使用的运算符。
如何理解而value对于Redis来说是一个字节数组,Redis并不知道value中存储的是什么
Redis不仅仅是一个简单的key-value内存数据库,Redis官网对自身的定义是“数据结构服务器”。
通过用心设计各种数据结构类型的数据存储,可以实现部分的数据查询功能。
因为在Redis的设计中,key是一切,对于Redis是可见的,而value对于Redis来说就是一个字节数组,Redis并不知道你的value中存储的是什么,所以要想实现比如‘select * from users where =shanghai’这样的查询,在Redis是没办法通过value进行比较得出结果的。
但是可以通过不同的数据结构类型来做到这一点。
比如如下的数据定义users:1 {name:Jack,age:28,location:shanghai}users:2 {name:Frank,age:30,location:beijing}users:location:shanghai [1]其中users:1 users:2 分别定义了两个用户信息,通过Redis中的hash数据结构,而users:location:shanghai 记录了所有上海的用户id,通过集合数据结构实现。
这样通过两次简单的Redis命令调用就可以实现我们上面的查询。
Jedis jedis = ();Set













发表评论