
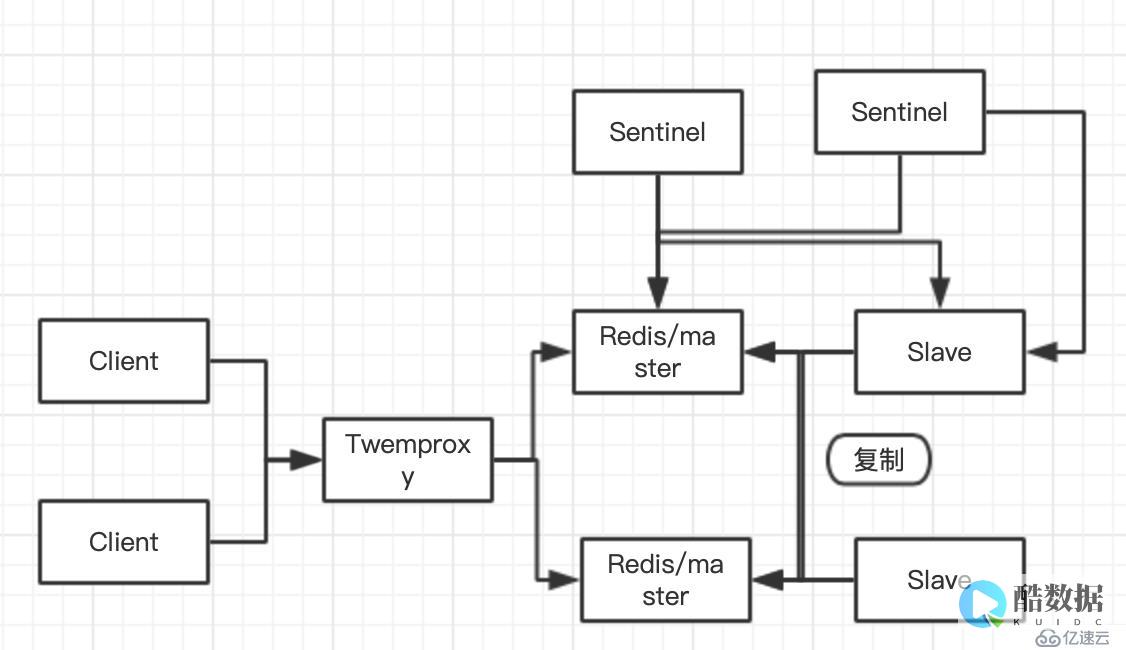
Redis是一个高性能的键值存储系统,可以用于缓存和实时数据处理。但是,当需要处理大量数据时,单个Redis节点很容易成为瓶颈,因此需要架构一个Redis集群来解决这个问题。
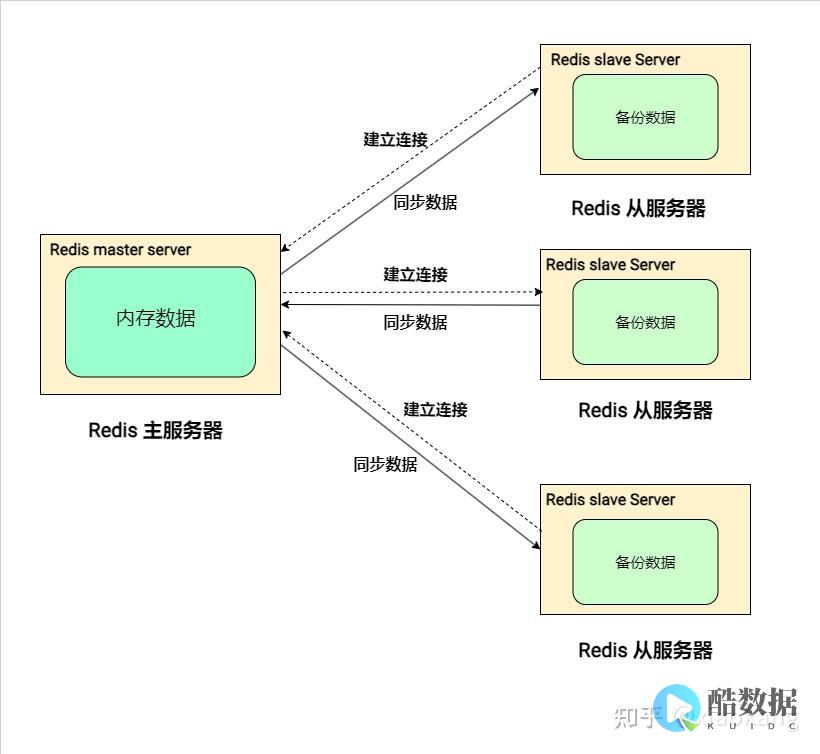
Redis集群分为两类:主从复制和分片(sharding)。主从复制是将一个节点作为主节点,其余的节点作为从节点,主节点负责写入和读取数据,从节点只负责读取数据。当主节点失效时,选举一个从节点作为主节点。分片是将数据分成多个部分,分别存储在不同的节点上,每个节点只负责存储其中一部分的数据。
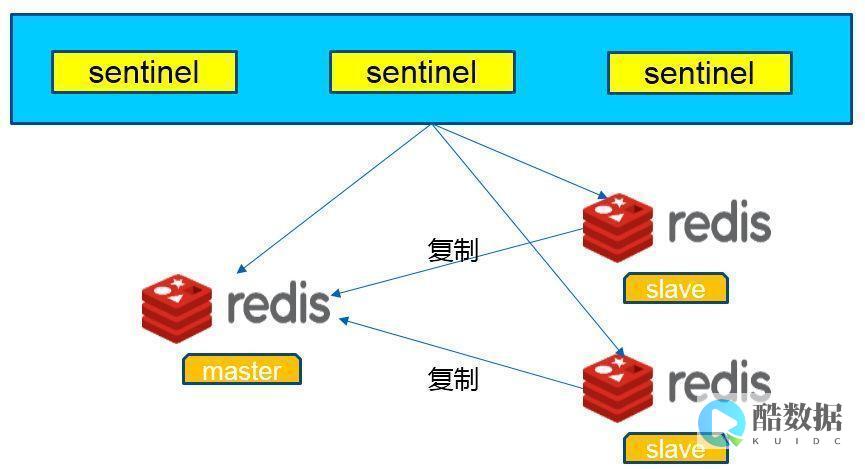
我们使用Redis Sentinel来实现主从复制。Sentinel是Redis的哨兵程序,用于监控Redis集群中每个节点的状态,并在某个节点失效时自动执行故障转移。
先在每个Redis节点上安装Sentinel,然后编辑Sentinel配置文件sentinel.conf。配置文件中需要指定Redis节点的IP和端口号,以及Sentinel自身的IP和端口号。例如:
sentinel monitor mymaster 127.0.0.1 6379 2sentinel down-after-milliseconds mymaster 5000sentinel flover-timeout mymaster 15000
这表示监控名为“mymaster”的Redis节点,IP为127.0.0.1,端口为6379,如果节点在5000毫秒内没有响应,就认为它失效了。如果节点失效了,Sentinel会在15000毫秒后执行故障转移。
接下来在主节点上执行以下命令,将从节点加入集群:
slaveof
其中是主节点的IP地址,是主节点的端口号。
然后在每个客户端连接时,使用Redis Sentinel提供的接口获取可用的Redis节点信息。
sentinel get-master-addr-by-name mymaster
这个接口返回主节点的IP地址和端口号。
使用Redis分片可以将数据均匀地分布在多个节点上,从而提高Redis集群的性能。一个划分数据的方法是按照key的值哈希到不同的节点上。Redis提供了一个简单的哈希函数来实现这个功能。
首先需要创建多个Redis节点,并将它们启动。然后在每个节点上执行以下命令,将其加入分片集群:
redis-cli cluster meet
这个命令表示将节点连接到具有指定IP地址和端口号的节点上。执行完这个命令后,需要使用以下命令指定节点的哈希槽范围:
redis-cli cluster addslots...
这个命令将指定哈希槽的范围,使节点只负责其中的哈希槽。
客户端需要使用Redis Cluster提供的接口来访问Redis分片集群。例如,如果要根据key的值获取对应的value,可以使用以下命令:
redis-cli -c get
其中-c选项表示使用Redis Cluster模式。
在Redis集群中,需要注意以下几点:
1. Sentinel和Cluster不能混合使用。
2. 每个节点都需要保留足够内存来存储数据和执行哈希算法。
3. 在主从复制模式下,主节点上的写操作不能保证立即被所有从节点执行,需要使用“写后读”的方式来访问数据。
4. 在分片模式下,如果一些节点失效,可能会导致部分数据不可访问。需要使用数据复制等技术来保证数据的可靠性和一致性。
在Redis集群架构中,需要考虑多个节点之间的数据复制、故障转移和负载均衡等问题。只有合理地部署和使用Redis集群,才能充分发挥Redis的性能优势。
香港服务器首选树叶云,2H2G首月10元开通。树叶云(www.IDC.Net)提供简单好用,价格厚道的香港/美国云 服务器 和独立服务器。IDC+ISP+ICP资质。ARIN和APNIC会员。成熟技术团队15年行业经验。
看Spring-cloud怎样使用Ribbon
关注下spring cloud是如何进行客户端负责均衡。 看怎么调用到负载均衡的,怎么定义负载均衡的,然后是怎么实现的?第一个其实可以不用关心,调用的地方应该很多,找到一个地方来说明怎么调用的即可。 第二个,可以猜下,最主要的应该是一个类似 serviceInstance get(string serviceId)这样的方法吧。 第三个问题,明摆着,使用netflix的ribbon呗。 发起一个调用时,LB对输入的serviceId,选择一个服务实例。 IOException {String serviceId = ();ServiceInstanceinstance = (serviceId);URIuri = (instance, originalUri);IClientConfigclientConfig = (());RestClientclient = ((), ); = (());return new RibbonHttpRequest(uri, verb, client, clientConfig);}关键代码看到调用的是一个LoadBalancerClient的choose方法,对一个serviceId,选择一个服务实例。 看下LoadBalancerClient是一个接口:足够简单,只定义了三个方法,根据一个serviceId,由LB选择一个服务实例。 reconstructURI使用Lb选择的serviceinstance信息重新构造访问URI,能想来也就是用服务实例的host和port来加上服务的路径来构造一个真正的刘访问的真正服务地址。 可以看到这个类定义在的package 下面,满篇不见ribbon字样。 只有loadbalancer,即这是spring-cloud定义的loadbalancer的行为,至于ribbon,只是客户端LB的一种实现。 Ribbon的实现定义在中的包下的RibbonLoadBalancerClient。 看下RibbonLoadBalancerClient中choose(String serviceId)方法的实现。 (String serviceId)@Overridepublic ServiceInstancechoose(String serviceId) {Serverserver = getServer(serviceId);return new RibbonServer(serviceId, server, isSecure(server, serviceId),serverIntrospector(serviceId)(server));}看到,最终调到的是ILoadBalancer的chooseServer方法。 即netflix的LB的能力来获取一个服务实例。 protected ServergetServer(String serviceId) {return getServer(getLoadBalancer(serviceId));}protected ServergetServer(ILoadBalancerloadBalancer) {return (“default”); ofkey}至于netflix如何提供这个能力的在另外一篇博文中尝试解析下。
memcached和redis的区别
medis与Memcached的区别传统Mysql+ Memcached架构遇到的问题 实际MySQL是适合进行海量数据存储的,通过Memcached将热点数据加载到cache,加速访问,很多公司都曾经使用过这样的架构,但随着业务数据量的不断增加,和访问量的持续增长,我们遇到了很多问题: 需要不断进行拆库拆表,Memcached也需不断跟着扩容,扩容和维护工作占据大量开发时间。 与MySQL数据库数据一致性问题。 数据命中率低或down机,大量访问直接穿透到DB,MySQL无法支撑。 4.跨机房cache同步问题。 众多NoSQL百花齐放,如何选择 最近几年,业界不断涌现出很多各种各样的NoSQL产品,那么如何才能正确地使用好这些产品,最大化地发挥其长处,是我们需要深入研究和思考的问题,实际归根结底最重要的是了解这些产品的定位,并且了解到每款产品的tradeoffs,在实际应用中做到扬长避短,总体上这些NoSQL主要用于解决以下几种问题 1.少量数据存储,高速读写访问。 此类产品通过数据全部in-momery 的方式来保证高速访问,同时提供数据落地的功能,实际这正是Redis最主要的适用场景。 2.海量数据存储,分布式系统支持,数据一致性保证,方便的集群节点添加/删除。 3.这方面最具代表性的是dynamo和bigtable 2篇论文所阐述的思路。 前者是一个完全无中心的设计,节点之间通过gossip方式传递集群信息,数据保证最终一致性,后者是一个中心化的方案设计,通过类似一个分布式锁服务来保证强一致性,数据写入先写内存和redo log,然后定期compat归并到磁盘上,将随机写优化为顺序写,提高写入性能。 free,auto-sharding等。 比如目前常见的一些文档数据库都是支持schema-free的,直接存储json格式数据,并且支持auto-sharding等功能,比如mongodb。 面对这些不同类型的NoSQL产品,我们需要根据我们的业务场景选择最合适的产品。 Redis适用场景,如何正确的使用 前面已经分析过,Redis最适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能,跟传统意义上的持久化有比较大的差别,那么可能大家就会有疑问,似乎Redis更像一个加强版的Memcached,那么何时使用Memcached,何时使用Redis呢?如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点: 1Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。 2Redis支持数据的备份,即master-slave模式的数据备份。 3Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。 抛开这些,可以深入到Redis内部构造去观察更加本质的区别,理解Redis的设计。 在Redis中,并不是所有的数据都一直存储在内存中的。 这是和Memcached相比一个最大的区别。 Redis只会缓存所有的 key的信息,如果Redis发现内存的使用量超过了某一个阀值,将触发swap的操作,Redis根据“swappability = age*log(size_in_memory)”计 算出哪些key对应的value需要swap到磁盘。 然后再将这些key对应的value持久化到磁盘中,同时在内存中清除。 这种特性使得Redis可以 保持超过其机器本身内存大小的数据。 当然,机器本身的内存必须要能够保持所有的key,毕竟这些数据是不会进行swap操作的。 同时由于Redis将内存 中的数据swap到磁盘中的时候,提供服务的主线程和进行swap操作的子线程会共享这部分内存,所以如果更新需要swap的数据,Redis将阻塞这个 操作,直到子线程完成swap操作后才可以进行修改。 使用Redis特有内存模型前后的情况对比: VM off: 300k keys, 4096 bytes values: 1.3G used VM on:300k keys, 4096 bytes values: 73M used VM off: 1 million keys, 256 bytes values: 430.12M used VM on:1 million keys, 256 bytes values: 160.09M used VM on:1 million keys, values as large as you want, still: 160.09M used当 从Redis中读取数据的时候,如果读取的key对应的value不在内存中,那么Redis就需要从swap文件中加载相应数据,然后再返回给请求方。 这里就存在一个I/O线程池的问题。 在默认的情况下,Redis会出现阻塞,即完成所有的swap文件加载后才会相应。 这种策略在客户端的数量较小,进行 批量操作的时候比较合适。 但是如果将Redis应用在一个大型的网站应用程序中,这显然是无法满足大并发的情况的。 所以Redis运行我们设置I/O线程 池的大小,对需要从swap文件中加载相应数据的读取请求进行并发操作,减少阻塞的时间。 如果希望在海量数据的环境中使用好Redis,我相信理解Redis的内存设计和阻塞的情况是不可缺少的。
java架构师主要是干什么的?
想成为java架构师,首先你自身得是一个高级java攻城狮,会使用各种框架并且很熟练,且知晓框架实现的原理。比如,你要知道,jvm虚拟机原理、调优;懂得jvm能让你写出的代码性能更优化;还有池技术:什么对象池、连接池、线程池等等。还有java反射技术,虽然是写框架必备的技术,但有严重的性能问题,替代方案java字节码技术,nio 这说不说无所谓,需要注意的是直接内存的特点,使用场景;java多线程同步异步;java各种集合对象的实现原理,了解这些可以让你在解决问题时选择合适的数据结构,高效的解决问题,比如hashmap的实现原理,甚至许多五年以上经验的人都弄不清楚!还有很多,比如,为什扩容时有性能问题?不弄清楚这些原理,不知道问题根本,你就就写不出高效的代码!还会很傻很天真的认为自己是对的,殊不知是孤芳自赏,自命不凡而已;总而验资,言而总之,越基础的东西越重要!许多工作了很多年的程序猿认为自己会用它们写代码了,其实仅仅是知其实仅仅是知道如何调用api而已,知其然不知其所以然,离会用还差的远。关于技能的提升给一些建议1.提升自己的英语水平,此重要性是不言而喻的,现在很多的新技术中文档少之又少,作为一名架构师总不能去看翻译文吧。2.多看一些沟通方面的数据,流畅的沟通利用你成为一名成功的架构师。3.有机会参加PMP考试并取得证书,拥有项目管理方向的优势就是你作为一名架构师的优势。架构师其实从某种意义上就是一种角色,而不是一种职位。一定要时时刻刻保持空杯心态。一定要有一颗保持饥渴学习和耐得住寂寞的赤子之心。4.我们知道当前的技术节奏非常的快,一定要好好的利用自己的碎片时间去学习,去了解新技术,千万不要让自己技术落伍。5.多锻炼自己在大众环境下的演讲和PTT的能力。6.与不同的技术、编程语言、设计模式和结构等(甚至是它并没有在日常中给予你直接的帮助)打交道。你永远都不知道这些知识是否会在未来派上用场,但是对你绝对是有益无害。7.有机会多做知识分享,因为你一旦分享了知识,你就会对这门技术有深刻的印象,同时也能树立在同事中的良好的技术形象,从而赢得更多的专家影响力而不是职位影响力。规划了几张体系图,可以了解一下。一:工程协作专题二、源码分析专题三、分布式专题四、微服务专题五、性能优化专题六、并发编程专题七、项目实战!java架构师课程体系完整页面架构师常用技术:













发表评论