
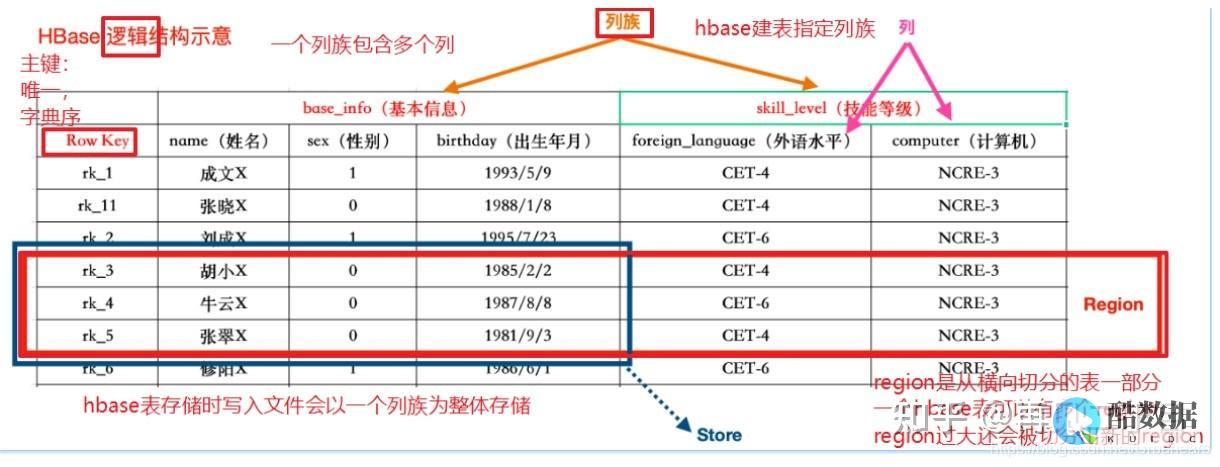
1 hbase.hregion.max.filesize应该设置多少合适
默认值:256M
说明:Maximum HStoreFile size. If any one of a column families’ HStoreFiles has grown to exceed this value, the Hosting HRegion is split in two.
HStoreFile的***值。如果任何一个Column Family(或者说HStore)的HStoreFiles的大小超过这个值,那么,其所属的HRegion就会Split成两个。
调优:
hbase中hfile的默认***值(hbase.hregion.max.filesize)是256MB,而google的bigtable论文中对tablet的***值也推荐为100-200MB,这个大小有什么秘密呢?
众所周知hbase中数据一开始会写入memstore,当memstore满64MB以后,会flush到disk上而成为storefile。当storefile数量超过3时,会启动compaction过程将它们合并为一个storefile。这个过程中会删除一些timestamp过期的数据,比如update的数据。而当合并后的storefile大小大于hfile默认***值时,会触发split动作,将它切分成两个region。
lz进行了持续insert压力测试,并设置了不同的hbase.hregion.max.filesize,根据结果得到如下结论:值越小,平均吞吐量越大,但吞吐量越不稳定;值越大,平均吞吐量越小,吞吐量不稳定的时间相对更小。
为什么会这样呢?推论如下:
a 当hbase.hregion.max.filesize比较小时,触发split的机率更大,而split的时候会将region offline,因此在split结束的时间前,访问该region的请求将被block住,客户端自我block的时间默认为1s。当大量的region同时发生split时,系统的整体访问服务将大受影响。因此容易出现吞吐量及响应时间的不稳定现象
b 当hbase.hregion.max.filesize比较大时,单个region中触发split的机率较小,大量region同时触发split的机率也较小,因此吞吐量较之小hfile尺寸更加稳定些。但是由于长期得不到split,因此同一个region内发生多次compaction的机会增加了。compaction的原理是将原有数据读一遍并重写一遍到hdfs上,然后再删除原有数据。无疑这种行为会降低以io为瓶颈的系统的速度,因此平均吞吐量会受到一些影响而下降。
综合以上两种情况,hbase.hregion.max.filesize不宜过大或过小,256MB或许是一个更理想的经验参数。对于离线型的应用,调整为128MB会更加合适一些,而在线应用除非对split机制进行改造,否则不应该低于256MB
2 autoflush=false的影响
无论是官方还是很多blog都提倡为了提高hbase的写入速度而在应用代码中设置autoflush=false,然后lz认为在在线应用中应该谨慎进行该设置。原因如下:
a autoflush=false的原理是当客户端提交delete或put请求时,将该请求在客户端缓存,直到数据超过2M(hbase.client.write.buffer决定)或用户执行了hbase.flushcommits()时才向regionserver提交请求。因此即使htable.put()执行返回成功,也并非说明请求真的成功了。假如还没有达到该缓存而client崩溃,该部分数据将由于未发送到regionserver而丢失。这对于零容忍的在线服务是不可接受的。
b autoflush=true虽然会让写入速度下降2-3倍,但是对于很多在线应用来说这都是必须打开的,也正是hbase为什么让它默认值为true的原因。当该值为true时,每次请求都会发往regionserver,而regionserver接收到请求后***件事就是写hlog,因此对io的要求是非常高的,为了提高hbase的写入速度,应该尽可能高地提高io吞吐量,比如增加磁盘、使用raid卡、减少replication因子数等
3 从性能的角度谈table中family和qualifier的设置
对于传统关系型数据库中的一张table,在业务转换到hbase上建模时,从性能的角度应该如何设置family和qualifier呢?
最极端的,①每一列都设置成一个family,②一个表仅有一个family,所有列都是其中的一个qualifier,那么有什么区别呢?
从读的方面考虑:
family越多,那么获取每一个cell数据的优势越明显,因为io和网络都减少了。
如果只有一个family,那么每一次读都会读取当前rowkey的所有数据,网络和io上会有一些损失。
当然如果要获取的是固定的几列数据,那么把这几列写到一个family中比分别设置family要更好,因为只需一次请求就能拿回所有数据。
从写的角度考虑:
首先,内存方面来说,对于一个Region,会为每一个表的每一个Family分配一个Store,而每一个Store,都会分配一个MemStore,所以更多的family会消耗更多的内存。
其次,从flush和compaction方面说,目前版本的hbase,在flush和compaction都是以region为单位的,也就是说当一个family达到flush条件时,该region的所有family所属的memstore都会flush一次,即使memstore中只有很少的数据也会触发flush而生成小文件。这样就增加了compaction发生的机率,而compaction也是以region为单位的,这样就很容易发生compaction风暴从而降低系统的整体吞吐量。
第三,从split方面考虑,由于hfile是以family为单位的,因此对于多个family来说,数据被分散到了更多的hfile中,减小了split发生的机率。这是把双刃剑。更少的split会导致该region的体积比较大,由于balance是以region的数目而不是大小为单位来进行的,因此可能会导致balance失效。而从好的方面来说,更少的split会让系统提供更加稳定的在线服务。而坏处我们可以通过在请求的低谷时间进行人工的split和balance来避免掉。
因此对于写比较多的系统,如果是离线应该,我们尽量只用一个family好了,但如果是在线应用,那还是应该根据应用的情况合理地分配family。
4 hbase.regionserver.handler.count
RegionServer端开启的RPC监听器实例个数,也即RegionServer能够处理的IO请求线程数。默认是10.

此参数与内存息息相关。该值设置的时候,以监控内存为主要参考。
对于 单次请求内存消耗较高的Big PUT场景(大容量单次PUT或设置了较大cache的scan,均属于Big PUT)或ReigonServer的内存比较紧张的场景,可以设置的相对较小。
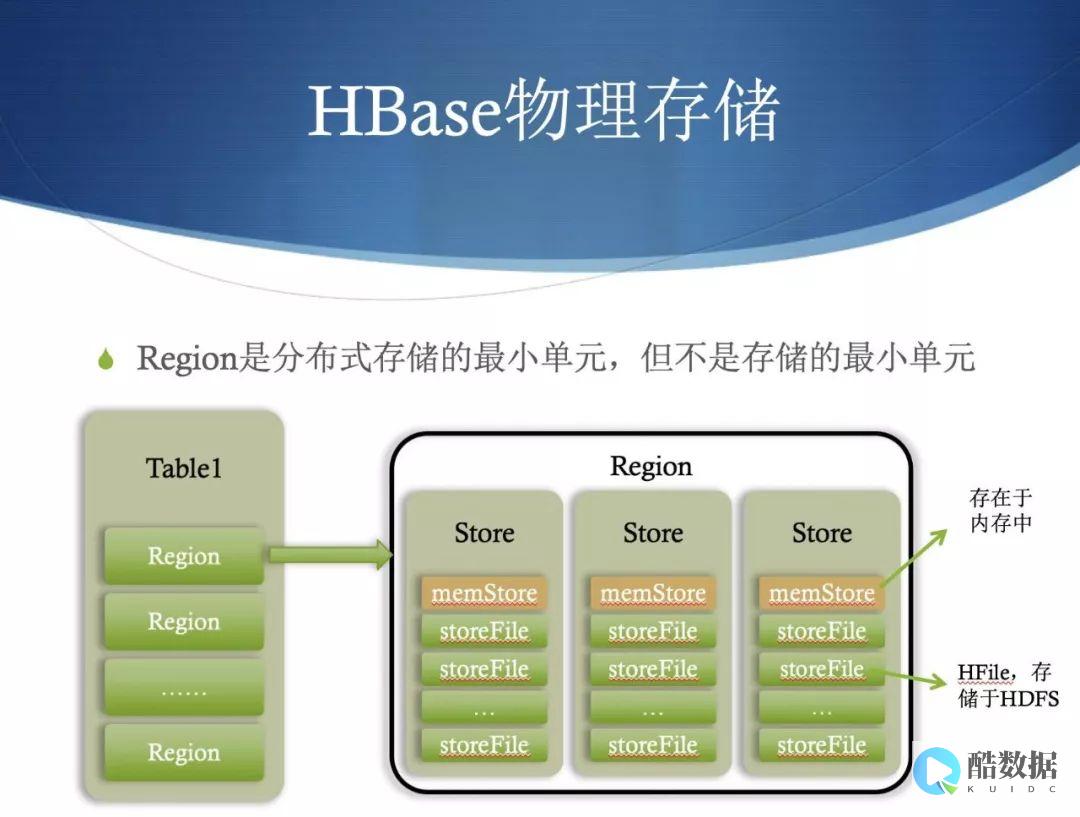
对于 单次请求内存消耗低,TPS(TransactionPerSecond,每秒事务处理量)要求非常高的场景,可以设置的相对大些。
原文链接:
【编辑推荐】
HBase 性能优化
sdwan广域网优化加速如何?
sdwan广域优化加速应用性能优化
SD-WAN应用性能优化可以改善远程办公室用户的应用体验。
有多种不同的网络问题会影响最终用户的应用程序性能,包括数据包丢失、WAN 电路拥塞、WAN 链接延迟高和 WAN 路径选择不理想。 优化应用程序体验对于实现高用户生产力至关重要。 SD-WAN 解决方案可以最大限度地减少丢失、抖动和延迟,并克服 WAN 延迟和转发错误,以优化应用程序性能。
以下SD-WAN 功能有助于解决应用程序性能优化问题:
一、应用感知路由
应用感知路由能够为流量创建定制的 SLA 策略并测量 BFD 探针的实时性能。 应用程序流量被定向到支持该应用程序 SLA 的 WAN 链接。 在性能下降期间,如果超过 SLA,可以将流量定向到其他路径。
二、服务质量(QoS)
QoS 包括对WAN 路由器接口上的流量进行分类、调度、排队、整形和监管。 总之,该功能旨在最大限度地减少关键应用程序流的延迟、抖动和数据包丢失。
三、前向纠错(FEC) 和数据包复制
这两个功能都用于减少数据包丢失。 使用 FEC,发送 WAN Edge 每四个数据包插入一个奇偶校验数据包,接收 WAN Edge 可以根据奇偶校验值重建丢失的数据包。 通过数据包复制,发送端 WAN Edge 一次通过两条隧道复制选定关键应用程序的所有数据包,而接收端 WAN Edge 重建关键应用程序流并丢弃重复的数据包。
四、TCP 优化和会话持久性
例如,这些功能可以解决长途或高延迟卫星链路的高延迟和低吞吐量问题。 通过 TCP 优化,WAN 边缘路由器充当客户端和服务器之间的 TCP 代理。 使用会话持久性,不是为每个单独的 TCP 请求和响应对创建一个新连接,而是使用单个 TCP 连接来发送和接收多个请求和响应。
五、集中管理
vManage 提供集中式故障、配置、记帐、性能和安全管理,作为操作的单一管理平台。 vManage 通过使用无处不在的策略和模板来简化操作并简化部署,从而减少变更控制和部署时间。
ARM的IP核有几种结构版本?
各ARM体系结构版本ARM体系结构从最初开发到现在有了很大的改进,并仍在完善和发展。 为了清楚地表达每个ARM应用实例所使用的指令集,ARM公司定义了6种主要的ARM指令集体系结构版本,以版本号V1~V6表示ARM版本Ⅰ: V1版架构该版架构只在原型机ARM1出现过,只有26位的寻址空间,没有用于商业产品。 其基本性能有:基本的数据处理指令(无乘法);基于字节、半字和字的Load/Store指令;转移指令,包括子程序调用及链接指令;供操作系统使用的软件中断指令SWI;寻址空间:64MB(226)。 ARM版本Ⅱ: V2版架构该版架构对V1版进行了扩展,例如ARM2和ARM3(V2a)架构。 包含了对32位乘法指令和协处理器指令的支持。 版本2a是版本2的变种,ARM3芯片采用了版本2a,是第一片采用片上Cache的ARM处理器。 同样为26位寻址空间,现在已经废弃不再使用。 V2版架构与版本V1相比,增加了以下功能:乘法和乘加指令;支持协处理器操作指令;快速中断模式;SWP/SWPB的最基本存储器与寄存器交换指令;寻址空间:64MB。 ARM版本Ⅲ : V3版架构ARM作为独立的公司,在1990年设计的第一个微处理器采用的是版本3的ARM6。 它作为IP核、独立的处理器、具有片上高速缓存、MMU和写缓冲的集成CPU。 变种版本有3G和3M。 版本3G是不与版本2a向前兼容的版本3,版本3M引入了有符号和无符号数乘法和乘加指令,这些指令产生全部64位结果。 V3版架构( 目前已废弃 )对ARM体系结构作了较大的改动:寻址空间增至32位(4GB);当前程序状态信息从原来的R15寄存器移到当前程序状态寄存器CPSR中(Current Program Status Register);增加了程序状态保存寄存器SPSR(Saved Program Status Register);增加了两种异常模式,使操作系统代码可方便地使用数据访问中止异常、指令预取中止异常和未定义指令异常。 ;增加了MRS/MSR指令,以访问新增的CPSR/SPSR寄存器;增加了从异常处理返回的指令功能。 ARM版本Ⅳ : V4版架构V4版架构在V3版上作了进一步扩充,V4版架构是目前应用最广的ARM体系结构,ARM7、ARM8、ARM9和StrongARM都采用该架构。 V4不再强制要求与26位地址空间兼容,而且还明确了哪些指令会引起未定义指令异常。 指令集中增加了以下功能:符号化和非符号化半字及符号化字节的存/取指令;增加了T变种,处理器可工作在Thumb状态,增加了16位Thumb指令集;完善了软件中断SWI指令的功能;处理器系统模式引进特权方式时使用用户寄存器操作;把一些未使用的指令空间捕获为未定义指令ARM版本Ⅴ : V5版架构V5版架构是在V4版基础上增加了一些新的指令,ARM10和Xscale都采用该版架构。 这些新增命令有:带有链接和交换的转移BLX指令;计数前导零CLZ指令;BRK中断指令;增加了数字信号处理指令(V5TE版); 为协处理器增加更多可选择的指令;改进了ARM/Thumb状态之间的切换效率;E---增强型DSP指令集,包括全部算法操作和16位乘法操作;J----支持新的JAVA,提供字节代码执行的硬件和优化软件加速功能。 ARM版本Ⅵ : V6版架构V6版架构是2001年发布的,首先在2002年春季发布的ARM11处理器中使用。 在降低耗电量地同时,还强化了图形处理性能。 通过追加有效进行多媒体处理的SIMD(Single Instruction, Multiple Data,单指令多数据 )功能,将语音及图像的处理功能提高到了原型机的4倍。 此架构在V5版基础上增加了以下功能:THUMBTM:35%代码压缩;DSP扩充:高性能定点DSP功能;JazelleTM:Java性能优化,可提高8倍;Media扩充:音/视频性能优化,可提高4倍
怎么样使CUP速度加快
请按照以下步骤进行优化:1。 通过性能监视器,检查是否是内存,I/0,CPU造成的瓶颈,并采取对应的措施2。 通过索引优化工具,对数据库进行索引优化,另外要检查库结构是否合理3。 检查你程序中效率低下的SQL语句,并进行优化












发表评论