
随着互联网业务的不断扩展和数据量的快速增长,如何高效地管理和同步缓存数据成为了许多企业需要解决的问题。Redis作为一款高性能的内存缓存数据库,具有快速读取和存储数据的优势,如果能够正确地使用和配置,就能够有效地提高系统的性能和稳定性。本文将介绍一些常见的Redis数据库技巧,帮助您实现高效缓存同步。
之一部分:Redis数据结构和数据操作
Redis支持多种数据类型,包括字符串、哈希表、列表、和有序。针对不同的数据类型,我们可以使用不同的数据操作,在Redis中存储和读取数据。
1.字符串数据类型
字符串是Redis中最基本的数据类型,可以存储更大长度为512MB的数据。我们可以使用SET命令来设置键值对的值,使用GET命令来获取键对应的值。除此之外,Redis还支持一些其他的字符串操作,例如INCR、DECR、APPEND等。
2.哈希表数据类型
哈希表是一种键值对的,可以存储多个键值对。每个键值对都由一个字段和一个值组成,可以使用HSET命令来设置哈希表中某个字段的值,使用HGET命令来获取哈希表中某个字段的值。还可以使用HGETALL命令来获取哈希表中所有的键值对。
3.列表数据类型
列表是一个有序的,可以存储多个元素,每个元素可以是一个字符串。我们可以使用LPUSH或RPUSH命令来向列表中添加元素,使用LPOP或RPOP命令来从列表中获取元素。还可以使用LINDEX命令来获取指定位置的元素,使用LLEN命令来获取列表的长度。
4.数据类型
是一个无序的,可以存储多个元素,每个元素可以是一个字符串。我们可以使用SADD命令向中添加元素,使用EMBERS命令来获取中所有的元素。还可以使用SCARD命令来获取中元素的数量。
5.有序数据类型
有序是一个有序的,可以存储多个元素,每个元素包含一个字符串和一个分值。我们可以使用ZADD命令向有序中添加元素,使用ZRANGE命令来按照分值顺序获取有序中的元素。还可以使用ZREVRANGE命令来按照分值倒序获取元素。
第二部分:Redis缓存同步策略
在分布式系统中,缓存同步是一个非常重要的问题。Redis可以作为主从复制、Sentinel和Cluster等多种缓存同步方式,每种方式都有各自的优劣和适用场景。
1.主从复制
主从复制是最基本的缓存同步方式,可以将一台Redis 服务器 作为主服务器,其他Redis服务器作为从服务器。当主服务器中的数据发生变化时,主服务器将变化的数据同步到从服务器中。从服务器可以读取主服务器中的数据,如果主服务器出现故障,则从服务器可以自动接替主服务器的工作。主从复制的优点是简单、稳定,适用于数据量不大的场景。
2.Sentinel
Sentinel是适用于中小规模Redis集群的缓存同步方式。它可以监控Redis服务的状态,并在主服务器故障时自动将从服务器升级为主服务器。Sentinel是一个独立的进程,可以与Redis服务器分别部署在不同的主机上,通过订阅Redis服务器的各种消息来实现缓存同步。
Cluster是适用于大规模Redis集群的缓存同步方式。它可以将多台Redis服务器组成一个集群,每个Redis服务器只存储部分数据,每个数据分片可以被多台Redis服务器读取和写入。Cluster能够自动将数据分散到各个服务器上,提高了读写数据的速度和性能,同时也保证了数据的备份和容错能力。
第三部分:Redis性能优化技巧
Redis是一款非常高性能的内存数据库,但是如果使用不当,也会出现一些性能上的问题。以下是一些Redis性能优化技巧,可以帮助你更好地使用Redis。
1.优化内存使用
由于Redis是一个内存数据库,因此内存使用是一个非常重要的问题。我们可以通过以下几种方法来优化Redis的内存使用:
– 使用压缩功能:Redis支持多种内存压缩算法,可以在配置文件中启用。
– 使用数据持久性功能:Redis支持多种数据持久性方式,可以将数据保存到磁盘中,以防止内存溢出。
– 避免重复数据:如果应用程序需要存储大量相似的数据,可以将数据进行合并和去重,以减少内存使用。
2.使用连接池
由于Redis是一个基于TCP协议的通讯协议,因此连接池的使用可以显著提高Redis的性能。连接池可以缓存多个Redis连接,以减少每次连接Redis服务器的时间和资源消耗。连接池可以减少应用程序与Redis服务器之间的延迟,提高应用程序的响应速度。
3.优化数据结构
在使用Redis时,我们应该选择与数据类型相匹配的数据结构,以提高Redis的性能。例如,如果应用程序需要按照时间顺序查询数据,则可以使用有序数据类型,以保证数据的有序性和快速查询。如果应用程序需要随机访问数据,则可以使用哈希表数据类型,以快速获取某个键对应的值。
4.使用Lua脚本
Lua脚本是一种在Redis中执行脚本的方式,可以将多个操作封装成一个单位进行原子性操作。Lua脚本可以减少与Redis服务器的通讯次数,提高Redis的性能。例如,如果应用程序需要进行多个操作,可以使用Lua脚本来执行这些操作,以减少与Redis服务器的通讯次数。
结论
本文介绍了一些Redis数据库技巧,包括数据结构和数据操作、缓存同步策略和性能优化技巧。正确地使用和配置Redis数据库,可以提高系统的性能和稳定性,帮助企业更好地管理和同步缓存数据。
相关问题拓展阅读:
php redis做MYSQL的缓存,怎么异步redis同步到mysql数据库
正常情况下是没有问题的,
但是有人用恶意脚本进行刷奖,也就是同一个人发起大量请求,1秒可能一两百的请求甚至更多,而且不只一个人刷奖。
问题出在1这一步
举个例子,假设每人只能抽一次奖,因为请求太快,同一人的a,b两个请求几乎同时来,a走完抽奖逻辑了,并且在抽奖表中插入记录的过旁慧程时,因为mysql的性能的问题,b去走1这一步是读不到表中的记录的,因为a的插入根本没有完成。所以b请求会再走一次抽奖逻辑。造成同一人抽奖两次,然后再插入抽奖表。
我关心的是能否a插入抽奖表的瞬间,b就能判断出抽奖表有数据。
所以我觉得问题侍贺是mysql写入的不够快,读取的不够快,所以我要采用redis做一层老启派快速缓存。
我们做的抽奖是单一奖品百分之百中奖,只限制奖品数量,所以必须保证每人只能抽一次,而且尽量在程序层面去解决。
Redis 如何保持和 MySQL 数据一致
redis在启动之后,从数据库加载数据。
读请求:
不要求强一致性的读请求,走redis,要求强一致性的直接从mysql读取
写请求:
数据首先都写到数据库,之后更新redis(先写喊尘芹redis再写mysql,如果写入失败事务回滚会造成redis中存在脏数据)
在并发不高的情况下,读操作优先读取redis,不存在的话就去访问MySQL,并把读到的数据写回Redis中;写操作的话,直接写MySQL,成功后再写入Redis(可以在MySQL端定义CRUD触发器,在触发CRUD操作后写数据到Redis,也可以在Redis端解析binlog,再做相应的操作)
在并发高的情况下,读操作和上面一样,写操作是异步写,写入Redis后直接返回,然后定期写入MySQL
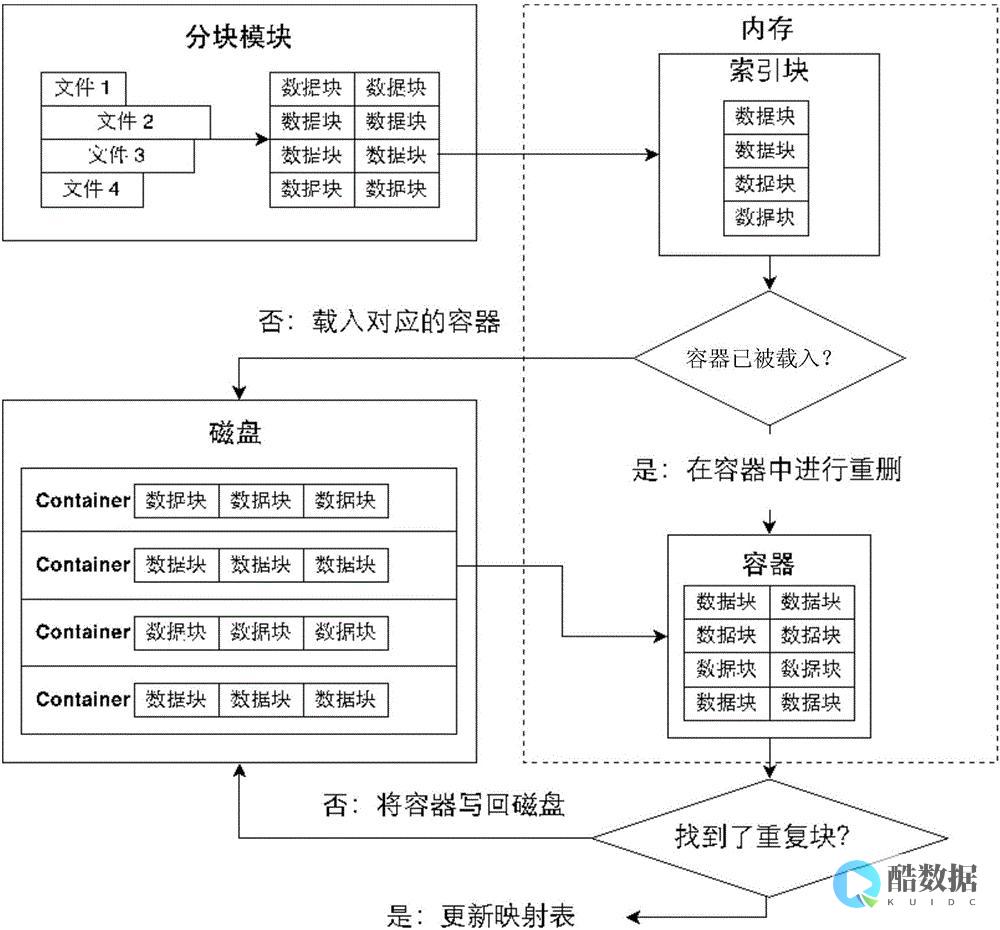
1.当更新数据时,如更新某商品的库存,当前商品的库存是100,现在要更新为99,先更新数据库更改成99,然后删除缓存,发现删除缓存失败了,这意味着数据库存的是99,而缓存是100,这导致数据库和缓存不一致。
解决方法:
这种情况应该是先删除缓存,然后在更新数据库,如果删除缓存失败,那就不要更新数据库,如果说删除缓存成功,而更新数据库失败,那查询的时候只是从数据库里查了旧的数据而已,这样就能保持数据库与缓存的一致性。
2.在高并发的情况下,如果当删除完缓存的时候,这时去更新数据库,但还没有更新完,另外一个请求来查询数据,发现缓存里没有,就去数据库里查,还是以上面商品库存为例,如果数据库中产品的库存是100,那么查询到的库存是100,然后插入缓存,插入完缓存后,原来那个更新数据库的线程把数据库更新为了99,导致数据库与缓存不一致的情况
解决方法:
遇到这种情况,可以用队列的去解决这个问,创建几个队列,如20个,根据商品的ID去做hash值,然后郑毕对队列个数取摸,当有数据更新请求时,先把它丢到队列里去,当更新完后在从队列里去除,如果在更新的过程中,遇到以上场景,先去缓存里看下有没有数据,如果没有,可以先去队列里看是否有相同商品ID在做更新,如果有也把查询的请求发送到队列里去,然后同步等待缓存更新完成。
这里有一个优化点,如果发现队列里有一个查询请求了,那么就不要放新的查询操作进去了,用一个while(true)循环去查询缓存,循环个200MS左右,如果缓存里还没有则直接取数据库的旧数据,一般情况下是可以取到的。
1、读请求时长阻塞
由于读请求进行了非常轻度的异步化,所以一定要注意读超时的问题,每个读请求必须在超时间内返回,该解决方案更大的风险在于可能数据更新很频繁,导致队列中挤压了大量的更新操作在里面,然后读请求会发生大量的超时,最后导致大量的请求直接走数据库,像遇到这种情况,一般要做好足够的压力测试,如果压力过大,需要根据实际情况添加机器。
2、请求并发量过高
这里还是要做好压力测试,多模拟真实场景,并兄悄发量在更高的时候QPS多少,扛不住就要多加机器,还有就是做好读写比例是多少
3、多服务实例部署的请求路由
可能这个服务部署了多个实例,那么必须保证说,执行数据更新操作,以及执行缓存更新操作的请求,都通过nginx服务器路由到相同的服务实例上
4、热点商品的路由问题,导致请求的倾斜
某些商品的读请求特别高,全部打到了相同的机器的相同丢列里了,可能造成某台服务器压力过大,因为只有在商品数据更新的时候才会清空缓存,然后才会导致读写并发,所以更新频率不是太高的话,这个问题的影响并不是很大,但是确实有可能某些服务器的负载会高一些。
搜索微信号(ID:芋道源码),可以获得各种 Java 源码解析。
并且,回复【书籍】后,可以领取笔者推荐的各种 Java 从入门到架构的书籍。
关于redis 数据库缓存同步的介绍到此就结束了,不知道你从中找到你需要的信息了吗 ?如果你还想了解更多这方面的信息,记得收藏关注本站。
香港服务器首选树叶云,2H2G首月10元开通。树叶云(www.IDC.Net)提供简单好用,价格厚道的香港/美国云服务器和独立服务器。IDC+ISP+ICP资质。ARIN和APNIC会员。成熟技术团队15年行业经验。
redis对象操作setTimeout(),在哪里可以查到用法?
redis对象操作setTimeout()的用法如下:setTimeout, expire设定一个key的活动时间(s)$redis->setTimeout(x, 3);有关redis的一系列set操作总结如下://SET 集合的相关操作// sadd 集合添加数据 初始化数据for($i=0; $i < 10 ; $i++){$redis->sadd(myset,$i+rand(10,99));}//srem 删除集合中的一个元素$bool = $redis->srem(myset,16);echo (int) $bool;//sMove 将value元素从名称为srckey的集合移到名称为dstkey的集合$bool = $redis->sMove(myset, myset1, 35);echo $bool;//smembers 显示集合中的元素$data = $redis->smembers(myset);// sIsMember, sContains 名称为key的集合中查找是否有value元素,有ture 没有 false$bool = $redis->sismember(myset,555);echo (int)$bool;//scard ssize集合key元素的个数echo $redis->scard(myset); //sInterStore//求交集并将交集保存到output的集合//$redis->sInterStore(output, key1, key2, key3)$redis->sinterstore(output,myset,myset1);$data = $redis->smembers(output);echo
;print_r($data);// sUnionStore求并集并将并集保存到output的集合//$redis->sUnionStore(output, key1, key2, key3);$redis->sunionstore(uoutput,myset,myset1);$data = $redis->smembers(uoutput);echo;print_r($data);//sort// 排序,分页等// 参数// by => some_pattern_*,// limit => array(0, 1),// get => some_other_pattern_* or an array of patterns,// sort => asc or desc,// alpha => TRUE,// store => external-key$data = $redis->sort(myset,array(sort=>desc));echo;print_r($data);//ZSET 有序集合的相关操作//zadd添加元素 zAdd(key, score, member):for($i=0; $i < 10 ; $i++){$redis->zadd(zset,$i+rand(10,99),$i+rand(100,999));}//zrangezRange(key, start, end,withscores) 返回指定范围的元素//zRevRange(key, start, end,withscores):返回名称为key的zset(元素已按score从大到小排序)中的index从start到end的所有元素: 是否输出socre的值,默认false,不输出//zRangeByScore, zRevRangeByScore//$redis->zRangeByScore(key, star, end, array(withscores, limit ));//返回名称为key的zset中score >= star且score <= end的所有元素$data = $redis->zrange(zset,0,3,withscores);//end -1 返回所有元素加withscoreswithscores做值 使用echo;print_r($data);//zDelete, zRem//zRem(key, member) :删除名称为key的zset中的元素member$redis->zrem(zset,456);//zCount//$redis->zCount(key, star, end);//返回名称为key的zset中score >= star且score <= end的所有元素的个数echo $redis->zcount(zset,10,50);//zRemRangeByScore, zDeleteRangeByScore$redis->zRemRangeByScore(key, star, end);//zremrangebyscore 删除 socre 大于star score 小于 end d的元素//删除名称为key的zset中score >= star且score <= end的所有元素,返回删除个数//zScore 返回名称为key的zset中元素val2的scoreecho $redis->zScore(zset, 503);//zRank, zRevRankzrank(set,value) 返回value 在集合中的位置 索引从0开始echo$redis->zrank(zset,723);//zIncrBy//$redis->zIncrBy(key, increment, member);//如果在名称为key的zset中已经存在元素member,则该元素的score增加increment;否则向集合中添加该元素,其score的值为increment//zUnion/zInter 就集合的合集和交集//HASH 哈希的相关操作//hset 初始化数据for( $i=0; $i < 10 ;$i++){$redis->hset(myhash,$i,rand(10,99)+$i);}//hget(myhash,key1) 返回哈希 myhash 中键为key1的对应的数值echo $redis->hget(myhash,0);//hLen 返回名称为h的hash中元素个数echo $redis->hlen(myhash);//hDel 删除名称为h的hash中键为key1的域echo $redis->hdel(myhash,0);// hKeys返回名称为key的hash中所有键$data = $redis->hkeys(myhash);//hVals返回名称为h的hash中所有键对应的value$data = $redis->hvals(myhash);//hGetAll 返回名称为h的hash中所有的键(field)及其对应的value$data = $redis->hgetall(myhash);echo;print_r($data);//hExists 判断某个hash的对应的键是否存在echo $redis->hexists(myhash,0);//hMset 向名称为key的hash中批量添加元素$redis->hmset(user:1,array(name1=>name1,name2=>Joe2));//hMGet 返回名称为h的hash中field1,field2对应的value$data = $redis->hmget(user:1, array(name, salary));echo;print_r($data);//Redis 相关操作//flushDB 清空当前数据库//flushAll 清空所有数据库//select 选择数据库//$redis->select(0);//move 把key1 移动到数据库2 $redis->move(key1,2);//rename, renameKey 给key从新命名//renameNx与remane类似,但是,如果重新命名的名字已经存在,不会替换成功//setTimeout, expire 设置key的生命时间$redis->settimeout(user:1,10);//expireat 指定一个key的生命时间为一个时间戳//expireAtkey存活到一个unix时间戳时间$redis->expireat(myhash,time()+ 10);//dbSize查看现在数据库有多少key $count = $redis->dbSize();//auth 密码认证$redis->auth(foobared);//bgrewriteaof使用aof来进行数据库持久化$redis->bgrewriteaof();//slaveof 通过执行 SLAVEOF host port 命令,可以将当前服务器转变为指定服务器的从属服务器(slave server)。$redis->slaveof(10.0.1.7, 6379);//save将数据同步保存到磁盘//bgsave 将数据异步保存到磁盘//lastSave返回上次成功将数据保存到磁盘的Unix时戳//info 返回redis的版本信息等详情echo;print_r($redis->info());// type 返回key的类型值 1-5 //string: Redis::REDIS_STRING 1//set: Redis::REDIS_SET 2//list: Redis::REDIS_LIST 3//zset: Redis::REDIS_ZSET 4//hash: Redis::REDIS_HASH 5//other: Redis::REDIS_NOT_FOUND 6echo $redis->type(myset); //2如何在 Redis 中配置多个可以访问的 IP 地址
redis是一个key-value存储系统和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。 这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。 在此基础上,redis支持各种不同方式的排序。 与memcached一样,为了保证效率,数据都是缓存在内存中。 区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
数据挖掘中的数据预处理技术有哪些,它们分别适用于哪些场合
一、数据挖掘工具分类数据挖掘工具根据其适用的范围分为两类:专用挖掘工具和通用挖掘工具。 专用数据挖掘工具是针对某个特定领域的问题提供解决方案,在涉及算法的时候充分考虑了数据、需求的特殊性,并作了优化。 对任何领域,都可以开发特定的数据挖掘工具。 例如,IBM公司的AdvancedScout系统针对NBA的数据,帮助教练优化战术组合。 特定领域的数据挖掘工具针对性比较强,只能用于一种应用;也正因为针对性强,往往采用特殊的算法,可以处理特殊的数据,实现特殊的目的,发现的知识可靠度也比较高。 通用数据挖掘工具不区分具体数据的含义,采用通用的挖掘算法,处理常见的数据类型。 通用的数据挖掘工具不区分具体数据的含义,采用通用的挖掘算法,处理常见的数据类型。 例如,IBM公司Almaden研究中心开发的QUEST系统,SGI公司开发的MineSet系统,加拿大SimonFraser大学开发的DBMiner系统。 通用的数据挖掘工具可以做多种模式的挖掘,挖掘什么、用什么来挖掘都由用户根据自己的应用来选择。 二、数据挖掘工具选择需要考虑的问题数据挖掘是一个过程,只有将数据挖掘工具提供的技术和实施经验与企业的业务逻辑和需求紧密结合,并在实施的过程中不断的磨合,才能取得成功,因此我们在选择数据挖掘工具的时候,要全面考虑多方面的因素,主要包括以下几点:(1)可产生的模式种类的数量:分类,聚类,关联等(2)解决复杂问题的能力(3)操作性能(4)数据存取能力(5)和其他产品的接口三、数据挖掘工具介绍是IBM公司Almaden研究中心开发的一个多任务数据挖掘系统,目的是为新一代决策支持系统的应用开发提供高效的数据开采基本构件。 系统具有如下特点:提供了专门在大型数据库上进行各种开采的功能:关联规则发现、序列模式发现、时间序列聚类、决策树分类、递增式主动开采等。 各种开采算法具有近似线性计算复杂度,可适用于任意大小的数据库。 算法具有找全性,即能将所有满足指定类型的模式全部寻找出来。 为各种发现功能设计了相应的并行算法。 是由SGI公司和美国Standford大学联合开发的多任务数据挖掘系统。 MineSet集成多种数据挖掘算法和可视化工具,帮助用户直观地、实时地发掘、理解大量数据背后的知识。 MineSet有如下特点:MineSet以先进的可视化显示方法闻名于世。 支持多种关系数据库。 可以直接从Oracle、Informix、Sybase的表读取数据,也可以通过SQL命令执行查询。 多种数据转换功能。 在进行挖掘前,MineSet可以去除不必要的数据项,统计、集合、分组数据,转换数据类型,构造表达式由已有数据项生成新的数据项,对数据采样等。 操作简单、支持国际字符、可以直接发布到Web。 是加拿大SimonFraser大学开发的一个多任务数据挖掘系统,它的前身是DBLearn。 该系统设计的目的是把关系数据库和数据开采集成在一起,以面向属性的多级概念为基础发现各种知识。 DBMiner系统具有如下特色:能完成多种知识的发现:泛化规则、特性规则、关联规则、分类规则、演化知识、偏离知识等。 综合了多种数据开采技术:面向属性的归纳、统计分析、逐级深化发现多级规则、元规则引导发现等方法。 提出了一种交互式的类SQL语言——数据开采查询语言DMQL。 能与关系数据库平滑集成。 实现了基于客户/服务器体系结构的Unix和PC(Windows/NT)版本的系统。 由美国IBM公司开发的数据挖掘软件IntelligentMiner是一种分别面向数据库和文本信息进行数据挖掘的软件系列,它包括IntelligentMinerforData和IntelligentMinerforText。 IntelligentMinerforData可以挖掘包含在数据库、数据仓库和数据中心中的隐含信息,帮助用户利用传统数据库或普通文件中的结构化数据进行数据挖掘。 它已经成功应用于市场分析、诈骗行为监测及客户联系管理等;IntelligentMinerforText允许企业从文本信息进行数据挖掘,文本数据源可以是文本文件、Web页面、电子邮件、LotusNotes数据库等等。 这是一种在我国的企业中得到采用的数据挖掘工具,比较典型的包括上海宝钢配矿系统应用和铁路部门在春运客运研究中的应用。 SASEnterpriseMiner是一种通用的数据挖掘工具,按照抽样--探索--转换--建模--评估的方法进行数据挖掘。 可以与SAS数据仓库和OLAP集成,实现从提出数据、抓住数据到得到解答的端到端知识发现。 是一个开放式数据挖掘工具,曾两次获得英国政府SMART创新奖,它不但支持整个数据挖掘流程,从数据获取、转化、建模、评估到最终部署的全部过程,还支持数据挖掘的行业标准--CRISP-DM。 Clementine的可视化数据挖掘使得思路分析成为可能,即将集中精力在要解决的问题本身,而不是局限于完成一些技术性工作(比如编写代码)。 提供了多种图形化技术,有助理解数据间的关键性联系,指导用户以最便捷的途径找到问题的最终解决法。 7.数据库厂商集成的挖掘工具SQLServer2000包含由Microsoft研究院开发的两种数据挖掘算法:Microsoft决策树和Microsoft聚集。 此外,SQLServer2000中的数据挖掘支持由第三方开发的算法。 Microsoft决策树算法:该算法基于分类。 算法建立一个决策树,用于按照事实数据表中的一些列来预测其他列的值。 该算法可以用于判断最倾向于单击特定标题(banner)或从某电子商务网站购买特定商品的个人。 Microsoft聚集算法:该算法将记录组合到可以表示类似的、可预测的特征的聚集中。 通常这些特征可能是隐含或非直观的。 例如,聚集算法可以用于将潜在汽车买主分组,并创建对应于每个汽车购买群体的营销活动。 ,SQLServer2005在数据挖掘方面提供了更为丰富的模型、工具以及扩展空间。 包括:可视化的数据挖掘工具与导航、8种数据挖掘算法集成、DMX、XML/A、第三方算法嵌入支持等等。 OracleDataMining(ODM)是Oracle数据库10g企业版的一个选件,它使公司能够从最大的数据库中高效地提取信息并创建集成的商务智能应用程序。 数据分析人员能够发现那些隐藏在数据中的模式和内涵。 应用程序开发人员能够在整个机构范围内快速自动提取和分发新的商务智能—预测、模式和发现。 ODM针对以下数据挖掘问题为Oracle数据库10g提供支持:分类、预测、回归、聚类、关联、属性重要性、特性提取以及序列相似性搜索与分析(BLAST)。 所有的建模、评分和元数据管理操作都是通过OracleDataMining客户端以及PL/SQL或基于Java的API来访问的,并且完全在关系数据库内部进行。 IBMIntelligentMiner通过其世界领先的独有技术,例如典型数据集自动生成、关联发现、序列规律发现、概念性分类和可视化呈现,它可以自动实现数据选择、数据转换、数据发掘和结果呈现这一整套数据发掘操作。 若有必要,对结果数据集还可以重复这一过程,直至得到满意结果为止。 现在,IBM的IntelligentMiner已形成系列,它帮助用户从企业数据资产中识别和提炼有价值的信息。 它包括分析软件工具----IntelligentMinerforData和IBMIntelligentMinerforText,帮助企业选取以前未知的、有效的、可行的业务知识----如客户购买行为,隐藏的关系和新的趋势,数据来源可以是大型数据库和企业内部或Internet上的文本数据源。 然后公司可以应用这些信息进行更好、更准确的决策,获得竞争优势。












发表评论