

以下的文章主要向大家描述的是MySQL数据库优化,SQL的实际操作步骤,我们讲述的是MySQL数据库优化,SQL的三步骤,以下就是这三步骤的具体操作的详细描述,望你浏览之后会对其有所收获。
MySQL数据库优化–SQL 第一步:
1:磁盘寻道能力,以高速硬盘(7200转/秒),理论上每秒寻道7200次.这是没有办法改变的,优化的方法是—-用多个硬盘,或者把数据分散存储.
2:硬盘的读写速度,这个速度非常的快,这个更容易解决–可以从多个硬盘上并行读写.
3:cpu.cpu处理内存中的数据,当有相对内存较小的表时,这是最常见的限制因素.
4:内存的限制.当cpu需要超出适合cpu缓存的数据时,缓存的带宽就成了内存的一个瓶颈—不过现在内存大的惊人,一般不会出现这个问题.
MySQL数据库优化–SQL第二步: (本人使用的是学校网站的Linux平台(Linux ADVX.Mandrakesoft.com 2.4.3-19mdk ))
1:调节 服务器 参数
用shell>MySQL(和PHP搭配之最佳组合)d-help这个命令声厂一张所有MySQL(和PHP搭配之最佳组合)选项和可配置变量的表.输出以下信息:
possible variables for option–set-variable(-o) are:
back_log current value:5 //要求MySQL(和PHP搭配之最佳组合)能有的连接数量.back_log指出在MySQL(和PHP搭配之最佳组合)暂停接受连接的时间内有多少个连接请求可以被存在堆栈中
connect_timeout current value:5 //MySQL(和PHP搭配之最佳组合)服务器在用bad handshake(不好翻译)应答前等待一个连接的时间
delayed_insert_timeout current value:200 //一个insert delayed在终止前等待insert的时间
delayed_insert_limit current value:50 //insert delayed处理器将检查是否有任何select语句未执行,如果有,继续前执行这些语句
delayed_queue_size current value:1000 //为insert delayed分配多大的队
flush_time current value:0 //如果被设置为非0,那么每个flush_time 时间,所有表都被关闭
interactive_timeout current value:28800 //服务器在关上它之前在洋交互连接上等待的时间
join_buffer_size current value:131072 //用与全部连接的缓冲区大小
key_buffer_size current value:1048540 //用语索引块的缓冲区的大小,增加它可以更好的处理索引
lower_case_table_names current value:0 //
long_query_time current value:10 //如果一个查询所用时间大于此时间,slow_queried计数将增加
max_allowed_packet current value:1048576 //一个包的大小
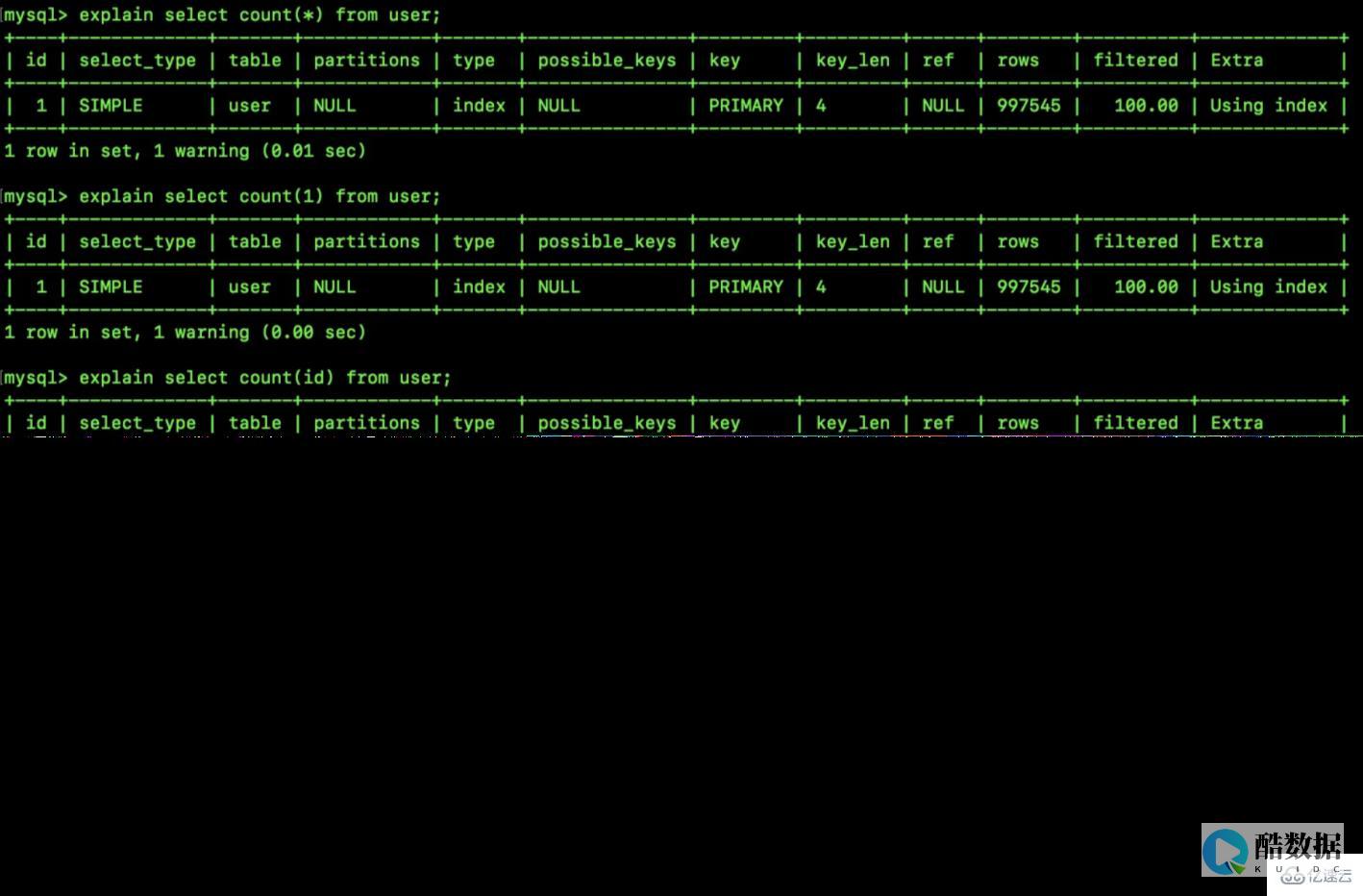
max_connections current value:300 //允许同时连接的数量
max_connect_errors current value:10 //如果有多于该数量的中断连接,将阻止进一步的连接,可以用flush Hosts来解决
max_delayed_threads current value:15 //可以启动的处理insert delayed的数量
max_heap_table_size current value:16777216 //
max_join_size current value:4294967295 //允许读取的连接的数量
max_sort_length current value:1024 //在排序blob或者text时使用的字节数量
max_tmp_tables current value:32 //一个连接同时打开的临时表的数量
max_write_lock_count current value:4294967295 //指定一个值(通常很小)来启动MySQL(和PHP搭配之最佳组合)d,使得在一定数量的write锁定之后出现read锁定
net_buffer_length current value:16384 //通信缓冲区的大小–在查询时被重置为该大小
query_buffer_size current value:0 //查询时缓冲区大小
record_buffer current value:131072 //每个顺序扫描的连接为其扫描的每张表分配的缓冲区的大小
sort_buffer current value:2097116 //每个进行排序的连接分配的缓冲区的大小
table_cache current value:64 //为所有连接打开的表的数量
thread_concurrency current value:10 //
tmp_table_size current value:1048576 //临时表的大小
thread_stack current value:131072 //每个线程的大小
wait_timeout current value:28800 //服务器在关闭它3之前的一个连接上等待的时间
根据自己的需要配置以上信息会对你帮助.
MySQL数据库优化–SQL第三: 1:如果你在一个数据库中创建大量的表,那么执行打开,关闭,创建(表)的操作就会很慢. 2:MySQL(和PHP搭配之最佳组合)使用内存
a: 关键字缓存区(key_buffer_size)由所有线程共享
b: 每个连接使用一些特定的线程空间.一个栈(默认为64k,变量thread_stack),一个连接缓冲区(变量net_buffer_length)和一个结果缓冲区(net_buffer_length).特定情况下,连接缓冲区和结果缓冲区被动态扩大到max_allowed_packet.
c:所有线程共享一个基存储器
d:没有内存影射
e:每个做顺序扫描的请求分配一个读缓冲区(record_buffer)
f:所有联结均有一遍完成并且大多数联结甚至可以不用一个临时表完成.最临时的表是基于内存的(heap)表
g:排序请求分配一个排序缓冲区和2个临时表
h:所有语法分析和计算都在一个本地存储器完成
i:每个索引文件只被打开一次,并且数据文件为每个并发运行的线程打开一次
j:对每个blob列的表,一个缓冲区动态的被扩大以便读入blob值
k:所有正在使用的表的表处理器被保存在一个缓冲器中并且作为一个fifo管理.
l:一个MySQL(和PHP搭配之最佳组合)admin flush-tables命令关闭所有不在使用的表并且在当前执行的线程结束时标记所有在使用的表准备关闭
3:MySQL(和PHP搭配之最佳组合)锁定表
MySQL(和PHP搭配之最佳组合)中所有锁定不会成为死锁. wirte锁定: MySQL(和PHP搭配之最佳组合)的锁定原理:a:如果表没有锁定,那么锁定;b否则,把锁定请求放入写锁定队列中
read锁定: MySQL(和PHP搭配之最佳组合)的锁定原理:a:如果表没有锁定,那么锁定;b否则,把锁定请求放入读锁定队列中
有时候会在一个表中进行很多的select,insert操作,可以在一个临时表中插入行并且偶尔用临时表的记录更新真正的表
max_tmp_tables current value:32 //一个连接同时打开的临时表的数量
max_write_lock_count current value:4294967295 //指定一个值(通常很小)来启动MySQL(和PHP搭配之最佳组合)d,使得在一定数量的write锁定之后出现read锁定
net_buffer_length current value:16384 //通信缓冲区的大小–在查询时被重置为该大小
query_buffer_size current value:0 //查询时缓冲区大小
record_buffer current value:131072 //每个顺序扫描的连接为其扫描的每张表分配的缓冲区的大小
sort_buffer current value:2097116 //每个进行排序的连接分配的缓冲区的大小
table_cache current value:64 //为所有连接打开的表的数量
thread_concurrency current value:10 //
tmp_table_size current value:1048576 //临时表的大小
thread_stack current value:131072 //每个线程的大小
wait_timeout current value:28800 //服务器在关闭它3之前的一个连接上等待的时间
根据自己的需要配置以上信息会对你帮助.
【编辑推荐】
mysql 查询,我要得到questionid,这个questionid必须对应有标签1和标签3,缺一不可
我有两种方法可以实现.1. 我推荐你洗数据,吧questionid相同的数据的tagid洗到同一行去,结果就是tagid变成1,3整体数据就会变成下面(当然,字段tagid类型要改一下varchar)1中午吃什么1,2标签1,标签22中午吃什么1,3标签1,标签33中午吃什么1,3标签1,标签3这样你的sql就会简单明了很多 * from table where find_in_set(1, tagid) and find_in_set(3, tagid);2. 如果上面那种方法改起来困难的话,这里有一个更困难的方法,就是硬写sqlselect * from table t1 where exists(select * from table t2 where = and tagid = 1) andexists(select * from table t3 where = and tagid = 3);用exists关键字.
mysql中查找数据库的位置用什么命令
1.查看数据库支持的所有字符集 show character set;或show char set;2.查看当前状态 里面包括当然的字符集设置 status或者\s 3.查看系统字符集设置,包括所有的字符集设置 show variables like char%; 4.查看数据表中字符集设置 show full columns from tablename; 或者 show create table tablename\G; 5.查看数据库编码 show create database dnname;
mysql 查询 条件过滤机制是怎样的
这是一个大题目,这里只能简单讲解一下。 SQL查询的筛选就是实现从一个或多个父记录行集合里筛选出所需要的子记录行集合。 数据库引擎具体的筛选机制是相当复杂的,除非您要成为一个数据库管理系统的开发工程师,一般人没有必要去了解它。 当我们需要筛选记录时将筛选逻辑的表述语句提交给数据库引擎去执行就可以了,只要描述这些筛选逻辑语句的语法正确,那么数据库引擎就会忠实地执行并返回相关的结果。 SQL语言里有多种主要方式来筛选记录。 其一是利用where子句设置筛选准则,这是最常用和最重要的筛选方式。 我们知道数据库表实际上是二维表,其横向坐标是字段(属性),纵向坐标比较特别,不像电子表格excel它没有固定的行号,纵向定位必须依赖各个字段的字段值(属性值)。 因此筛选准则实际就是规定字段值(或者基于字段值的计算表达式)满足(或不满足)某个或多个条件,既可以是精确满足的(使用=号)也可以模糊满足的(使用like运算符)。 筛选可以针对单字段也可以针对多字段,我们可以通过逻辑与、逻辑或连接多个筛选条件。 其二是利用表间连接来方式来筛选记录,包括左连接、右连接、对等连接、自连接等,这种连接方法主要是用于筛选出两个记录集之间的交集或非交集。 其三是利用子查询筛选记录,包括[ANY | ALL | SOME]子查询、in子查询、exists子查询等等,其作用跟第二种类似。 当然还有Group、分组里的having子句、distinct关键字、limit等关键字、正则表达式等等方式都可以用于筛选记录,内容相当丰富,筛选可以通过一种或多种方式组合实施,以满足千变万化的筛选需求。












发表评论