
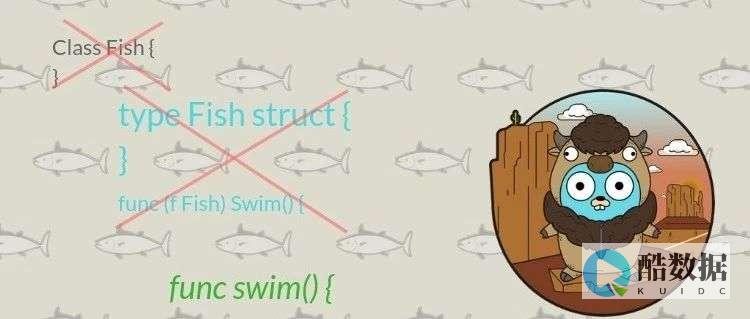
那些用Go实现的分布式事务框架之二
2021-12-15 10:00:21seata中的TM对标dtm事务SDK。作用都是一样:第一阶段开启一个全局事务,执行各RM分支事务,第二阶段根据RM第一阶段执行结果,决定调用TC(seata)|TM(dtm) commit或者rollback。
开篇
这次我们来介绍一下另一个go实现的分布式事务:dtm。
再来看之前的seata架构图。
从架构上来看,大差不差。
seata中的TC对标dam的TM。
RM两边意思一致。
seata中的TM对标dtm事务SDK。作用都是一样:第一阶段开启一个全局事务,执行各RM分支事务,第二阶段根据RM第一阶段执行结果,决定调用TC(seata)|TM(dtm) commit或者rollback。
架构上,个人感觉只是因为模块名称以及图画不一样的差别,当然在实现细节上还是有很大差别的。
我们先简单介绍下DTM各个模块。
TM 层在代码中是没有具体的主体结构的,开始都是函数之前的调用。
启动TM实际上开启了两个服务,http以及grpc这两个服务。
http路由,
gRPC接口,
即然提供了两个服务入口,那理所当然有公共处理核心业务的部分。
TM对数据的存储管理并不是依赖于接口,而是依赖于common.DB 结构。根据配置文件中DB.driver 的值决定底层数据库是mysql还是postgres两种。
再看这个DB结构,所以本质上无论底层是哪种数据库,都是直接依赖gorm来对数据进行操作的。
接着,看下TM是如何通知各个RM进行commit或者rollback的?
举一个TCC模式的例子。
TCC的两个阶段。
从上面我们可以得知,TCC模式下,TM在第二阶段要么通知各分支事务Confirm要么Cancel。
在注册各RM事务分支到TM的时候,最终TM会为每一个分布式事务的参与者(RM)生成两条分支信息。
就像这样,
对,就是把对应的RM资源操作地址直接存入。
当TM接收到commit或者rollback命令,在处理完自身逻辑(一般就是修改Gloable状态),就需要开始处理每一个注册进来的分支事务了,说白了就是需要调用各个分支事务对应操作的接口。
这里的t.getProcessor() 是需要根据当前事务的类型(TCC、SAGA、XA)获取到对应的处理器来进行逻辑的处理。
当然,每个事务处理器只需要实现接口,
真正调用RM资源服务地址的时候,分为http和grpc,这是由开发者决定的。
在v1.6之前的版本,grpc的请求是很简单粗暴解析地址方法然后连接的。
现在为了支持那些采用gRPC Resolver 机制之上的一些微服务框架接入,做了一块抽象。感兴趣[1]可以看下,这里就不介绍了。
至于SDK,每一个事务模式都是独立的,本质上是没有关联的。比如下面我们启动一个TCC分布式事务。这个分布式事务是由两个服务组成,简称+30和-30的服务。
另外提一点,分布式事务常见的一些问题:比如空补偿、重挂等问题。
一般情况下,业务需要自行去处理这种场景,以免造成不可描述的错误。
dtm里面提供了对应子事务屏障方案。核心就在,
其实就是利用数据库的唯一索引机制,当然每个RM资源你都得新增一张表。
上面提到,dtm的TM角色本质上就是对应 seata 中的 TC,但是他们的处理模式是不同的。
dtm中的TM会根据注册时的各分支保存的地址,决定通过http还是rpc调用各RM操作,是由TM直接发起对RM的请求。
seata-go的实现中,TC是不参与直接调用RM的。
还记得上篇提到一个双向流RPC接口(BranchCommunicate)。TC通过这个接口把对应分支处理信息传递给RM管理器。
然后由RM管理器根据事务类型选择对应的事务管理器进行处理,最终调用的是对应事务类型管理器的BranchCommit方法。
下面是一个TCC事务类型管理器的处理。

对应的事务RM管理器是如何通知、处理各个RM资源的。
原理就是我上篇提到的作者实现的一个全局事务代理模式,本质上是利用go的反射实现的,感兴趣的可以自己去扒下源码,也可以看看作者对实现全局事务代理的介绍[2]。
总结
这篇文章主要介绍了dtm实现的一些细节,从这两篇文章大体能看出实现上的部分区别,更多的细节还得靠自己去挖掘。
最后再问几个问题,
相关
class="zdmcj_hr"/>
NET中有没有类似ZooKeeper这样的分布式服务框架
您好,很高兴为您解答。参考下:如若满意,请点击右侧【采纳答案】,如若还有问题,请点击【追问】希望我的回答对您有所帮助,望采纳! ~ O(∩_∩)O~
弱弱问一句:system.linq是做什么用的命名空间``?
framworker 3.5增加的新特性 LINQ(Language Integrated Query)是Visual Studio 2008中的领军人物。 借助于LINQ技术,我们可以使用一种类似SQL的语法来查询任何形式的数据。 目前为止LINQ所支持的数据源有SQL Server、XML以及内存中的数据集合。 开发人员也可以使用其提供的扩展框架添加更多的数据源,例如MySQL、Amazon甚至是Google Desktop。 一般来讲,这类查询语句的一个重要特点就是可以并行化执行。 虽然有些情况下并行可能会带来一些问题,但这种情况非常少见。 这样也就水到渠成地引出了PLINQ这个并行处理的LINQ类库。 PLINQ原名为Parallel LINQ,支持XML和内存中的数据集合。 执行于远程服务器上的查询语句(例如LINQ to SQL)显然无法实现这个功能。 将LINQ语句转换为PLINQ语句极为简单——只需要在查询语句中From子句所指定的数据源的最后添加()即可。 随后Where、OrderBy和Select子句将自动改为调用这个并行的LINQ版本。 据MSDN Magazine介绍,PLINQ可以以三种方式执行。 第一种是管道处理:一个线程用来读取数据源,而其他的线程则用来处理查询语句,二者同步进行——虽然这个单一的消费线程可能并不那么容易与多个生产线程同步。 不过若是能够仔细配置好负载平衡的话,仍然会极大地减少内存占用。 第二种模式叫做“stop and go”,用于处理结果集需要被一次返回时(例如调用ToList、ToArray或对结果排序)的情况。 在这种模式下,将依次完成各个处理过程,并将结果统一返回给消费线程。 这个模式在性能上将优于第一种模式,因为它省去了用来保持线程同步所花费的开销。 最后一种方法叫做“inverted enumeration”。 该方法并不需要实现收集到所有的输出,然后在单一的线程中处理,而是将最终调用的函数通过ForAll扩展传递到每个线程中。 这是目前为止最快的一种处理模式,不过这需要传递到ForAll中的函数是线程安全的,且最好不包含任何lock之类的互斥语句。 若是PLINQ中任意的一个线程抛出异常,那么所有的其他线程将会被终止。 若是抛出了多个异常,那么这些异常将被组合成一个multipleFailuresException类型的异常,但每个异常的调用堆栈仍会被保留。
堆栈的结构如果用连接的方式实现,类如何定义
#include












发表评论