
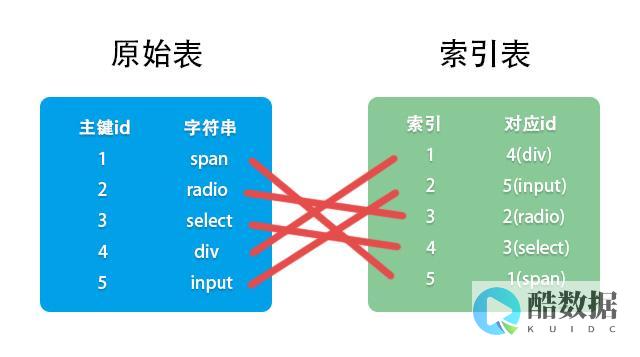
在数据库管理系统中,索引是一种可以加快数据的检索速度的重要方式。随着数据量的增大,对于大型数据库来说,建立适当数量的索引非常重要。虽然过多的索引可能会导致一些性能问题,但适当地建立一些额外的索引有助于提高查询性能和减少查询时间。本文将探讨在数据库表中多建立索引的优势。
1.更快的查询速度
查询数据库表是非常常见的操作,而建立索引可以大大降低查询的时间。当数据库表被建立索引后,查询的速度会更快。建立多个索引会加速多个搜索条件的结果集,使查询变得更加快速和高效。
2.更小的系统资源消耗
在大型数据库中,查询的速度可能会变慢,导致系统资源消耗加大。过多的查询可能导致 服务器 负载过高,降低系统性能。建立合适的索引可以减少这种负担,使系统资源消耗更小,从而提高了系统的整体性能。
3.更高的数据一致性
在处理大量数据时,确保数据的一致性非常重要。如果在数据库中存在重复的数据,可能会导致意外的错误或数据损坏。建立索引可以帮助维护数据库表的数据一致性,减少错误和损坏的情况。
4.更容易实现数据分析和挖掘
数据分析和挖掘是现代数据库的重要应用。这两个过程需要处理大量数据,并执行复杂的查询操作。通过建立更多的索引,可以轻松地分析和挖掘数据,使查询变得更加快速和简单。
5.更好的应用程序性能
在建立索引时,应该特别注意的是,在应用程序中查询数据时,需要建立与应用程序中使用的搜索条件相匹配的索引。这样可以提高应用程序的性能并提高代码的效率。对于众多的网站和应用程序来说,增加索引可以提高用户的访问速度并减少响应时间,提高用户的满意度和粘性。
6.更好的数据可靠性
当数据记录过多时,数据记录的存储就变得更加复杂。这时如果存在重复的记录就可能导致数据丢失或数据错误。多建立索引可以有效地减少数据丢失和数据错误的情况,提高数据的可靠性和完整性。
多建立数据库表索引可以大大提高数据库查询的性能和速度,减少系统资源消耗,提高数据的一致性,更容易实现数据分析和挖掘。同时,多建立索引也有助于提高应用程序的性能和用户的满意度,增强数据的可靠性。在建立索引时,应根据应用程序中使用的搜索条件进行匹配,以更大限度地提高索引的效率。
相关问题拓展阅读:
SQL中一个表可以有几个聚集索引或非聚集索引?
一个表只能有一个聚集
索引
,可以有多个非聚集索引
下面是聚集索引和非聚集索引的详细介绍:
聚集索引基于数据行的键值在表内排序和存储这些数据行。每个表只能有一个聚集索引,因为数据行本身只能按一个顺序存储。有关聚集索引体系结构的详细信息,请参阅聚集索引结构。
每个表几乎都对列定义聚集索引来实现下列功能:
可用于经常使用的查询。
提供高度唯一性。
注意:
创建 PRIMARY KEY 约束时,将在列上自动创建唯一索引。默认情况下,此索引是聚集索引,但是在创建约束时,可以指定创建非聚集索引。
可用于范围查询。
如果未使用 UNIQUE 属性创建聚集索引,数据库引擎将向表自动添加一个 4 字节的 uniqueifier
列。必要时,数据库引擎将向行自动添加一个 uniqueifier 值以使每个键唯一。此列和列值供内部使用,用户不能查看或访问。
查询注意事项
在创建聚集索引之前,应先了解数据是如何被访问的。考虑对具有以下特点的查询使用聚集索引:
使用
运算符
(如 BETWEEN、>、>=、
使用聚集索引找到包含之一个值的行后,便可以确保包含后续索引值的行物理相邻。例如,如果某个查询在一系列销售订单号间检索记录,SalesOrderNumber
列的聚集索引可快速定位包含起始销售订单号的行,然后检索表中所有连续的行,直到检索到最后的销售订单号。
返回大型结果集。
使用 JOIN 子句;一般情况下,使用该子句的是
外键
列。
使用 ORDER BY 或
子句。
在 ORDER BY 或 GROUP BY
子句中指定的列的索引,可以使数据库引擎不必对数据进行排序,因为这些行已经排序。这样可以提高查询性能。
列注意事项
一般情况下,定义聚集索引键时使用的列越少越好。考虑具有下列一个或多个属性的列:
唯一或包含许多不重复的值
例如,雇员 ID 唯一地标识雇员。EmployeeID 列的聚集索引或 PRIMARY KEY
约束将改善基于雇员 ID 号搜索雇员信息的查询的性能。另外,可对
lastName、FirstName、MiddleName
列创建聚集索引,因为经常以这种方式分组和查询雇员记录,而且这些列的组合还可提供高区分度。
按顺序被访问
例如,产品 ID 唯一地标识 AdventureWorks2023R2 数据库的
Production.Product 表中的产品。在其中指定顺序搜索的查询(如 WHERE ProductID BETWEEN 980
and 999)将从 ProductID 的聚集索引受益。这是因为行将按该键列的排序顺序存储。
由于保证了列在表中是唯一的,所以定义为 IDENTITY。
经常用于对表中检索到的数据进行排序。
按该列对表进行聚集(即物理排序)是一个好方法,它可以在每次查询该列时节省排序操作的成本。
聚集索引不适用于具有下列属性的列:
频繁更改的列
这将导致整行移动,因为数据库引擎必须按物理顺序保留行中的数据值。这一点要特别注意,因为在大容量
事务处理系统
中数据通常是可变的。
宽键
宽键是若干列或若干大型列的组合。所有非聚集索引将聚集索引中的键值用作查找键。为同一表定义的任何非聚集索引都将增大许多,这是因为非聚集索引项包含聚集键,同时也包含为此非聚集索引定义的键列。
索引选项
创建聚集索引时,可指定若干索引选项。因为聚集索引锋兆通常都很大,所以应特别注意下列选项:
SORT_IN_TEMPDB
DROP_EXISTING
FILLFACTOR
非聚集索引包含索引键值和指向表数据存储位置的行定位器。有关非聚集索引体系结构的详细信息,请参阅非聚拿碧集索引结构。
可以对表或索引视图创建多个非聚集索引。通常,设计非聚集索引是为改善经常使用的、没有建立聚集索引的查询的性能。
与使用书中索引的方式相似,查询优化器在搜索数据值时,先搜索非聚集索引以找到数据值在表中的位置,然后直接从该位置检索数据。这使非聚集索引成为完全匹配查询的更佳选择,因为索引包含说明查询所搜索的数据值在表中的精确位置的项。例如,为了从
Person.Person 表中查询具有特定姓氏的人员,查询优化器可能使用非聚集消基举索引
IX_Person_LastName_FirstName_MiddleName;它以 LastName 作为自己的一个键列。查询优化器能快速找出索引中与指定
匹配的所有项。每个索引项都指向表或聚集索引中准确的页和行,其中可以找到相应的数据。在查询优化器在索引中找到所有项之后,它可以直接转到准确的页和行进行数据检索。
数据库注意事项
设计非聚集索引时需要注意数据库的特征。
更新要求较低但包含大量数据的数据库或表可以从许多非聚集索引中获益从而改善查询性能。与全表非聚集索引相比,考虑为定义完善的数据子集创建筛选索引可以提高查询性能、降低索引存储开销并减少索引维护开销。
决策支持系统
应用程序
和主要包含只读数据的数据库可以从许多非聚集索引中获益。查询优化器具有更多可供选择的索引用来确定最快的访问方法,并且数据库的低更新特征意味着索引维护不会降低性能。
联机事务处理应用程序和包含大量更新表的数据库应避免使用过多的索引。此外,索引应该是窄的,即列越少越好。
一个表如果建有大量索引会影响

INSERT、UPDate、DELETE 和 MERGE
语句的性能,因为当表中的数据更改时,所有索引都须进行适当的调整。
查询注意事项
在创建非聚集索引之前,应先了解访问数据的方式。考虑对具有以下属性的查询使用非聚集索引:
使用 JOIN 或 GROUP BY
子句。
应为联接和分组操作中所涉及的列创建多个非聚集索引,为任何外键列创建一个聚集索引。
不返回大型结果集的查询。
创建筛选索引以覆盖从大型表中返回定义完善的行子集的查询。
包含经常包含在查询的搜索条件(例如返回完全匹配的 WHERE 子句)中的列。
列注意事项
考虑具有以下一个或多个属性的列:
覆盖查询。
当索引包含查询中的所有列时,性能可以提升。查询优化器可以找到索引内的所有列值;不会访问表或聚集索引数据,这样就减少了磁盘
I/O 操作。使用具有包含列的索引来添加覆盖列,而不是创建宽索引键。有关详细信息,请参阅
具有包含列的索引
如果表有聚集索引,则该聚集索引中定义的列将自动追加到表上每个非聚集索引的末端。这可以生成覆盖查询,而不用在非聚集索引定义中指定聚集索引列。例如,如果一个表在
C 列上有聚集索引,则 B 和 A 列的非聚集索引将具有其自己的键值列 B、A 和 C。
大量非重复值,如姓氏和名字的组合(前提是聚集索引被用于其他列)。
如果只有很少的非重复值,例如仅有 1 和
0,则大多数查询将不使用索引,因为此时表扫描通常更有效。对于这种类型的数据,应考虑对仅出现在少数行中的非重复值创建筛选索引。例如,如果大部分值都是
0,则查询优化器可以对包含 1 的数据行使用筛选查询。
索引选项
在创建非聚集索引时,可以指定若干索引选项。要尤其注意以下选项:
FILLFACTOR
每个数据库表可以建立多个索引的介绍就聊到这里吧,感谢你花时间阅读本站内容,更多关于每个数据库表可以建立多个索引,数据库表索引多建几个有什么优势?,SQL中一个表可以有几个聚集索引或非聚集索引?的信息别忘了在本站进行查找喔。
香港服务器首选树叶云,2H2G首月10元开通。树叶云(www.IDC.NET)提供简单好用,价格厚道的香港/美国云服务器和独立服务器。IDC+ISP+ICP资质。ARIN和APNIC会员。成熟技术团队15年行业经验。
sql中索引有什么用
索引用来提高读取数据的速度。 比如你要从一个有一万条记录的表中读取记录,那么如果有索引,他会通过索引定位,找到你要找的记录,速度比一个一个记录的扫描表快很多很多倍。 表的某一个列可以建立索引,也可以是几个列一起建立索引。 索引有主键索引、唯一性索引等。 主键的索引是默认的,不能删除。 你可以先看看数据结构->排序,查找,B-Tree,red-black tree等内容。 然后看看数据库系统原理的一些基本概念,不用全看懂。 然后下载MySQL数据库,安装,写一些测试程序,往表里写个百八十万条记录,然后查询。 。 。
在SQL中table与view的区别
table(表格)是一个完整的表,所有的数据都存放在这个表里面。 view(视图)可以是一个表、或表里面的部分内容。 有选择性的。 用到view的地方,一般都是一条sql语句,筛选出来的部分内容。
数据库中的索引到底有什么用啊
索引 使用索引可快速访问数据库表中的特定信息。 索引是对数据库表中一列或多列的值进行排序的一种结构,例如 employee 表的姓(lname)列。 如果要按姓查找特定职员,与必须搜索表中的所有行相比,索引会帮助您更快地获得该信息。 索引提供指向存储在表的指定列中的数据值的指针,然后根据您指定的排序顺序对这些指针排序。 数据库使用索引的方式与您使用书籍中的索引的方式很相似:它搜索索引以找到特定值,然后顺指针找到包含该值的行。 在数据库关系图中,您可以在选定表的“索引/键”属性页中创建、编辑或删除每个索引类型。 当保存索引所附加到的表,或保存该表所在的关系图时,索引将保存在数据库中。 有关详细信息,请参见创建索引。 注意;并非所有的数据库都以相同的方式使用索引。 有关更多信息,请参见数据库服务器注意事项,或者查阅数据库文档。 作为通用规则,只有当经常查询索引列中的数据时,才需要在表上创建索引。 索引占用磁盘空间,并且降低添加、删除和更新行的速度。 在多数情况下,索引用于数据检索的速度优势大大超过它的。 索引列 可以基于数据库表中的单列或多列创建索引。 多列索引使您可以区分其中一列可能有相同值的行。 如果经常同时搜索两列或多列或按两列或多列排序时,索引也很有帮助。 例如,如果经常在同一查询中为姓和名两列设置判据,那么在这两列上创建多列索引将很有意义。 确定索引的有效性: 检查查询的 WHERE 和 JOIN 子句。 在任一子句中包括的每一列都是索引可以选择的对象。 对新索引进行试验以检查它对运行查询性能的影响。 考虑已在表上创建的索引数量。 最好避免在单个表上有很多索引。 检查已在表上创建的索引的定义。 最好避免包含共享列的重叠索引。 检查某列中唯一数据值的数量,并将该数量与表中的行数进行比较。 比较的结果就是该列的可选择性,这有助于确定该列是否适合建立索引,如果适合,确定索引的类型。 索引类型 根据数据库的功能,可以在数据库设计器中创建三种索引:唯一索引、主键索引和聚集索引。 有关数据库所支持的索引功能的详细信息,请参见数据库文档。 提示:尽管唯一索引有助于定位信息,但为获得最佳性能结果,建议改用主键或唯一约束。 唯一索引唯一索引是不允许其中任何两行具有相同索引值的索引。 当现有数据中存在重复的键值时,大多数数据库不允许将新创建的唯一索引与表一起保存。 数据库还可能防止添加将在表中创建重复键值的新数据。 例如,如果在 employee 表中职员的姓 (lname) 上创建了唯一索引,则任何两个员工都不能同姓。 主键索引数据库表经常有一列或列组合,其值唯一标识表中的每一行。 该列称为表的主键。 在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。 该索引要求主键中的每个值都唯一。 当在查询中使用主键索引时,它还允许对数据的快速访问。 聚集索引在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同。 一个表只能包含一个聚集索引。 如果某索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配。 与非聚集索引相比,聚集索引通常提供更快的数据访问速度。













发表评论