

分布式缓存系统Memcached入门指导
2009-11-09 09:25:24这篇Memcached入门介绍涵盖的主题包括安装、配置、memcached 客户机命令和评估缓存效率,主要讨论与 memcached 服务器 的直接交互,其目的是为您提供监控 memcahed 实例所需的工具。
首先介绍一下,memcached 是由 Danga Interactive 开发并使用 BSD 许可的一种通用的分布式内存缓存系统(题外话:最近,Memcached 项目将从正式转向)。这篇Memcached入门文章可以帮助读者建立起对Memcached使用与性能的认识。
Memcached示意图(来自memcached.org)
Danga Interactive 开发 memcached 的目的是创建一个内存缓存系统来处理其网站 LiveJournal.com 的巨大流量。每天超过 2000 万的页面访问量给 LiveJournal 的数据库施加了巨大的压力,因此 Danga 的 Brad Fitzpatrick 便着手设计了 memcached。memcached 不仅减少了网站数据库的负载,还成为如今世界上大多数高流量网站所使用的缓存解决方案。
本文首先全面概述 memcached,然后指导您安装 memcached 以及在开发环境中构建它。我还将介绍 memcached 客户机命令(总共有 9 个)并展示如何在标准和高级 memcached 操作中使用它们。最后,我将提供一些使用 memcached 命令测量缓存的性能和效率的技巧。
如何将 memcached 融入到您的环境中?
在开始安装和使用 using memcached 之前,我们需要了解如何将 memcached 融入到您的环境中。虽然在任何地方都可以使用 memcached,但我发现需要在数据库层中执行几个经常性查询时,memcached 往往能发挥最大的效用。我经常会在数据库和应用服务器之间设置一系列 memcached 实例,并采用一种简单的模式来读取和写入这些服务器。图 1 可以帮助您了解如何设置应用程序体系结构:
图 1. 使用 memcached 的示例应用程序体系结构
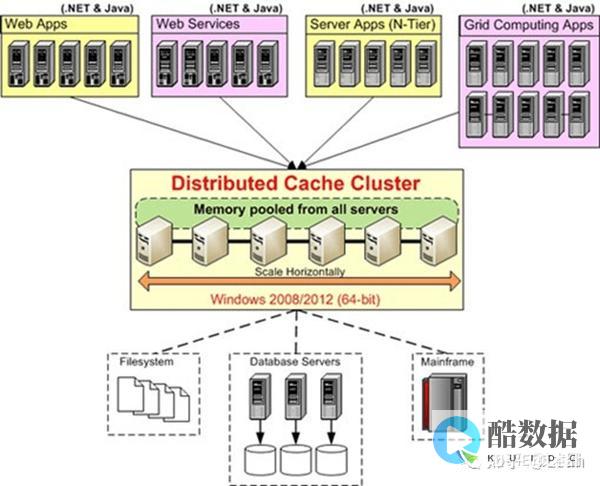
体系结构相当容易理解。我建立了一个 Web 层,其中包括一些 Apache 实例。下一层是应用程序本身。这一层通常运行于 Apache Tomcat 或其他开源应用服务器之上。再下面一层是配置 memcached 实例的地方 — 即应用服务器与数据库服务器之间。在使用这种配置时,需要采用稍微不同的方式来执行数据库的读取和写入操作。
读取
我执行读取操作的顺序是从 Web 层获取请求(需要执行一次数据库查询)并检查之前在缓存中存储的查询结果。如果我找到所需的值,则返回它。如果未找到,则执行查询并将结果存储在缓存中,然后再将结果返回给 Web 层。
写入
将数据写入到数据库中时,首先需要执行数据库写入操作,然后将之前缓存的任何受此写入操作影响的结果设定为无效。此过程有助于防止缓存和数据库之间出现数据不一致性。
安装 memcached
memcached 支持一些操作系统,包括 Linux?、Windows?、Mac OS 和 Solaris。在本文中,我将详细介绍如何通过源文件构建和安装 memcached。采用这种方式的主要原因是我在遇到问题时可以查看源代码。
libevent 是安装 memcached 的唯一前提条件。它是 memcached 所依赖的异步事件通知库。您可以在 monkey.org 上找到关于 libevent 的源文件。接下来,找到其最新版本的源文件。对于本文,我们使用稳定的 1.4.11 版本。获取了归档文件之后,将它解压到一个方便的位置,然后执行清单 1 中的命令:
清单 1. 生成和安装 libevent
cd libevent-1.4.11-stable/./configuremakemake install |
从 Danga Interactive 获取 memcached 源文件,仍然选择最新的分发版。在撰写本文时,其最新版本是 1.4.0。将 tar.gz 解压到方便的位置,并执行清单 2 中的命令:
清单 2. 生成和安装 memcached
cd memcached-1.4.0/./configuremakemake install |
完成这些步骤之后,您应该安装了一个 memcached 工作副本,并且可以使用它了。让我们进行简单介绍,然后使用它。
使用 memcached
要开始使用 memcached,您首先需要启动 memcached 服务器,然后使用 telnet 客户机连接到它。
要启动 memcached,执行清单 3 中的命令:
清单 3. 启动 memcached
./memcached -d -m 2048 -l 10.0.0.40 -p 11211 |
这会以守护程序的形式启动 memcached(-d),为其分配 2GB 内存(-m 2048),并指定监听 localhost,即端口 11211。您可以根据需要修改这些值,但以上设置足以完成本文中的练习。接下来,您需要连接到 memcached。您将使用一个简单的 telnet 客户机连接到 memcached 服务器。
大多数操作系统都提供了内置的 telnet 客户机,但如果您使用的是基于 Windows 的操作系统,则需要下载第三方客户机。我推荐使用 PuTTy。
安装了 telnet 客户机之后,执行清单 4 中的命令:
清单 4. 连接到 memcached
telnet localhost 11211 |
如果一切正常,则应该得到一个 telnet 响应,它会指示 Connected to localhost(已经连接到 localhost)。如果未获得此响应,则应该返回之前的步骤并确保 libevent 和 memcached 的源文件都已成功生成。
您现现已经登录到 memcached 服务器。此后,您将能够通过一系列简单的命令来与 memcached 通信。9 个 memcached 客户端命令可以分为三类:
基本 memcached 客户机命令
您将使用五种基本 memcached 命令执行最简单的操作。这些命令和操作包括:
前三个命令是用于操作存储在 memcached 中的键值对的标准修改命令。它们都非常简单易用,且都使用清单 5 所示的语法:
清单 5. 修改命令语法
表 1 定义了 memcached 修改命令的参数和用法。
表 1. memcached 修改命令参数
| 参数 | 用法 |
|---|---|
| key 用于查找缓存值 | |
| 可以包括键值对的整型参数,客户机使用它存储关于键值对的额外信息 | |
| expiration time | 在缓存中保存键值对的时间长度(以秒为单位,0 表示永远) |
| 在缓存中存储的字节点 | |
| 存储的值(始终位于第二行) |
现在,我们来看看这些命令的实际使用。
set 命令用于向缓存添加新的键值对。如果键已经存在,则之前的值将被替换。
注意以下交互,它使用了 set 命令:
set userId 0 0 512345STORED |
如果使用 set 命令正确设定了键值对,服务器将使用单词 STORED 进行响应。本示例向缓存中添加了一个键值对,其键为 userId,其值为 12345。并将过期时间设置为 0,这将向 memcached 通知您希望将此值存储在缓存中直到删除它为止。
仅当缓存中不存在键时,add 命令才会向缓存中添加一个键值对。如果缓存中已经存在键,则之前的值将仍然保持相同,并且您将获得响应 NOT_STORED。
下面是使用 add 命令的标准交互:
set userId 0 0 512345STOREDadd userId 0 0 555555NOT_STOREDadd companyId 0 0 3564STORED |
仅当键已经存在时,replace 命令才会替换缓存中的键。如果缓存中不存在键,那么您将从 memcached 服务器接受到一条 NOT_STORED 响应。
下面是使用 replace 命令的标准交互:
replace accountId 0 0 567890NOT_STOREDset accountId 0 0 567890STOREDreplace accountId 0 0 555555STORED |
最后两个基本命令是 get 和 delete。这些命令相当容易理解,并且使用了类似的语法,如下所示:
接下来看这些命令的应用。
get 命令用于检索与之前添加的键值对相关的值。您将使用 get 执行大多数检索操作。
下面是使用 get 命令的典型交互:
set userId 0 0 512345STOREDget userIdVALUE userId 0 512345ENDget bobEND |
如您所见,get 命令相当简单。您使用一个键来调用 get,如果这个键存在于缓存中,则返回相应的值。如果不存在,则不返回任何内容。
最后一个基本命令是 delete。delete 命令用于删除 memcached 中的任何现有值。您将使用一个键调用 delete,如果该键存在于缓存中,则删除该值。如果不存在,则返回一条 NOT_FOUND 消息。
下面是使用 delete 命令的客户机服务器交互:
set userId 0 0 598765STOREDdelete bobNOT_FOUNDdelete userIdDELETEDget userIdEND |
高级 memcached 客户机命令
可以在 memcached 中使用的两个高级命令是 gets 和 cas。gets 和 cas 命令需要结合使用。您将使用这两个命令来确保不会将现有的名称/值对设置为新值(如果该值已经更新过)。我们来分别看看这些命令。
gets 命令的功能类似于基本的 get 命令。两个命令之间的差异在于,gets 返回的信息稍微多一些:64 位的整型值非常像名称/值对的 “版本” 标识符。
下面是使用 gets 命令的客户机服务器交互:
set userId 0 0 512345STOREDget userIdVALUE userId 0 512345ENDgets userIdVALUE userId 0 5 412345END |
考虑 get 和 gets 命令之间的差异。gets 命令将返回一个额外的值 — 在本例中是整型值 4,用于标识名称/值对。如果对此名称/值对执行另一个 set 命令,则 gets 返回的额外值将会发生更改,以表明名称/值对已经被更新。清单 6 显示了一个例子:
清单 6. set 更新版本指示符
set userId 0 0 533333STOREDgets userIdVALUE userId 0 5 533333END |
您看到 gets 返回的值了吗?它已经更新为 5。您每次修改名称/值对时,该值都会发生更改。
cas(check 和 set)是一个非常便捷的 memcached 命令,用于设置名称/值对的值(如果该名称/值对在您上次执行 gets 后没有更新过)。它使用与 set 命令相类似的语法,但包括一个额外的值:gets 返回的额外值。
注意以下使用 cas 命令的交互:
set userId 0 0 555555STOREDgets userIdVALUE userId 0 5 655555ENDcas userId 0 0 5 633333STORED |
如您所见,我使用额外的整型值 6 来调用 gets 命令,并且操作运行非常顺序。现在,我们来看看清单 7 中的一系列命令:
清单 7. 使用旧版本指示符的 cas 命令
set userId 0 0 555555STOREDgets userIdVALUE userId 0 5 855555ENDcas userId 0 0 5 633333EXISTS |
注意,我并未使用 gets 最近返回的整型值,并且 cas 命令返回 EXISTS 值以示失败。从本质上说,同时使用 gets 和 cas 命令可以防止您使用自上次读取后经过更新的名称/值对。
缓存管理命令
最后两个 memcached 命令用于监控和清理 memcached 实例。它们是 stats 和 flush_all 命令。
stats 命令的功能正如其名:转储所连接的 memcached 实例的当前统计数据。在下例中,执行 stats 命令显示了关于当前 memcached 实例的信息:
statsSTAT pid 63STAT uptime 101758STAT time 1248643186STAT version 1.4.11STAT pointer_size 32STAT rusage_user 1.177192STAT rusage_system 2.365370STAT curr_items 2STAT total_items 8STAT bytes 119STAT curr_connections 6STAT total_connections 7STAT connection_structures 7STAT cmd_get 12STAT cmd_set 12STAT get_hits 12STAT get_misses 0STAT evictions 0STAT bytes_read 471STAT bytes_written 535STAT limit_maxbytes 67108864STAT threads 4END |
此处的大多数输出都非常容易理解。稍后在讨论缓存性能时,我还将详细解释这些值的含义。至于目前,我们先来看看输出,然后再使用新的键来运行一些 set 命令,并再次运行 stats 命令,注意发生了哪些变化。
flush_all 是最后一个要介绍的命令。这个最简单的命令仅用于清理缓存中的所有名称/值对。如果您需要将缓存重置到干净的状态,则 flush_all 能提供很大的用处。下面是一个使用 flush_all 的例子:
set userId 0 0 555555STOREDget userIdVALUE userId 0 555555ENDflush_allOKget userIdEND |
缓存性能
在本文的最后,我将讨论如何使用高级 memcached 命令来确定缓存的性能。stats 命令用于调优缓存的使用。需要注意的两个最重要的统计数据是 et_hits 和 get_misses。这两个值分别指示找到名称/值对的次数(get_hits)和未找到名称/值对的次数(get_misses)。
结合这些值,我们可以确定缓存的利用率如何。初次启动缓存时,可以看到 get_misses 会自然地增加,但在经过一定的使用量之后,这些 get_misses 值应该会逐渐趋于平稳 — 这表示缓存主要用于常见的读取操作。如果您看到 get_misses 继续快速增加,而 get_hits 逐渐趋于平稳,则需要确定一下所缓存的内容是什么。您可能缓存了错误的内容。
确定缓存效率的另一种方法是查看缓存的命中率(hit ratio)。缓存命中率表示执行 get 的次数与错过 get 的次数的百分比。要确定这个百分比,需要再次运行 stats 命令,如清单 8 所示:
清单 8. 计算缓存命中率
statsSTAT pid 6825STAT uptime 540692STAT time 1249252262STAT version 1.2.6STAT pointer_size 32STAT rusage_user 0.056003STAT rusage_system 0.180011STAT curr_items 595STAT total_items 961STAT bytes 4587415STAT curr_connections 3STAT total_connections 22STAT connection_structures 4STAT cmd_get 2688STAT cmd_set 961STAT get_hits 1908STAT get_misses 780STAT evictions 0STAT bytes_read 5770762STAT bytes_written 7421373STAT limit_maxbytes 536870912STAT threads 1END |
现在,用 get_hits 的数值除以 cmd_gets。在本例中,您的命中率大约是 71%。在理想情况下,您可能希望得到更高的百分比 — 比率越高越好。查看统计数据并不时测量它们可以很好地判定缓存策略的效率。
结束语
缓存是任何海量 Web 应用程序不可或缺的部分。我自己成功使用过它好几次。如果您选择使用 memcached 作为缓存解决方案,那么我敢保证您可以看到它的效率如何。
【编辑推荐】
集群部署怎么保障系统的可靠性
VPLEX的技术核心是“分布式缓存一致性”,下图则是“分布式缓存一致性”技术的工作机制示意:正是因为这项核心技术优势,使得VPLEX方案和目前所有厂商的虚拟化方案截然不同,并能够实现异地的数据中心整合。 对跨数据中心的所有负载实现跨引擎的平摊或者实时迁移,来自任何一个主机的I/O请求可以通过任何一个引擎得到响应。 缓存一致性的记录目录使用少量的元数据,记录下哪个数据块属于哪个引擎更新的,以及在何时更新过,并通过4K大小的数据块告诉在集群中的所有其他的引擎。 在整个过程中实际发生的沟通过程,远远比实际上正在更新数据块少很多。 分布式缓存一致性数据流示意图:上方是一个目录,记录下左侧的主机读取缓存A的操作,并分发给所有引擎,右侧主机需要读取该数据块时,会先通过目录查询,确定该数据块所属的引擎位置,读取请求会直接发送给引擎,并直接从数据块所在的缓存上读取。 当一个读请求进入时,VPLEX会自动检查目录,查找该数据块所属的引擎,一旦确定该数据块所属的引擎位置,读的请求会直接发送给该引擎。 一旦一个写入动作完成,并且目录表被修改,这时另一个读请求从另一个引擎过来,VPLEX会检查目录,并且直接从该引擎的缓存上读取。 如果该数据仍然在缓存上,则完全没必要去磁盘上读取。 如上图,来自图中左侧主机的操作,由Cache A服务,会记录一个更新状态,并分发给所有所有引擎知道。 如果读取的需求来自最右侧的服务器,首先通过目录查询。 通过这种技术可以实现所有引擎一致性工作,而且这个技术不仅可以跨引擎还可以跨VPLEX集群,而VPLEX集群可以跨区域,因此缓存一致性也可以跨区域部署。 分布式缓存一致性技术使VPLEX相比传统的虚拟化方案拥有更高的性能和可靠性,并实现异地数据中心的虚拟化整合 对传统的虚拟化架构来说,如果虚拟化的I/O集群中有一个节点坏了,那么性能就会降低一半,而且实际情况降低不止一半。 因为坏了一个节点,这个节点缓存一般会被写进去。 因为没有缓存,操作会直接写到硬盘里。 如果图中中心这个节点坏掉,那主机所有的可用性都没有了。 而VPLEX如果有一个引擎或者一个控制器坏掉了,那这个引擎的负载会均摊到其他活动引擎上。 这样总体来讲用户可以维持可预知性能,性能降低也不那么明显。
redis可以存储websocket session对象吗
集群web系统的话,可以通过第三方缓存来统一实现session管理。 如果使用spring的话,可以通过session listener来监听session的变化,实现起来比较方便。 不建议把Session存储起来可以考虑用Redis模拟session,特别是分布式环境,比如多台web serve(如tomcat)r的情况下
手机上网的HTTP是什么意思?
WWW的核心——HTTP协议 众所周知,Internet的基本协议是TCP/IP协议,目前广泛采用的FTP、Archie Gopher等是建立在TCP/IP协议之上的应用层协议,不同的协议对应着不同的应用 WWW服务器使用的主要协议是HTTP协议,即超文体传输协议。 由于HTTP协议支持的服务不限于WWW,还可以是其它服务,因而HTTP协议允许用户在统一的界面下,采用不同的协议访问不同的服务,如FTP、Archie、SMTP、Nntp等。 另外,HTTP协议还可用于名字服务器和分布式对象管理。 HTTP协议简介 HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。 它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。 目前在WWW中使用的是HTTP/1.0的第六版,HTTP/1.1的规范化工作正在进行之中,而且HTTP-NG(Next Generation of HTTP)的建议已经提出。 HTTP协议的主要特点可概括如下: 1.支持客户/服务器模式。 2.简单快速:客户向服务器请求服务时,只需传送请求方法和路径。 请求方法常用的有GET、HEAD、POST。 每种方法规定了客户与服务器联系的类型不同。 由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。 3.灵活:HTTP允许传输任意类型的数据对象。 正在传输的类型由Content-Type加以标记。 4.无连接:无连接的含义是限制每次连接只处理一个请求。 服务器处理完客户的请求,并收到客户的应答后,即断开连接。 采用这种方式可以节省传输时间。 5.无状态:HTTP协议是无状态协议。 无状态是指协议对于事务处理没有记忆能力。 缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。 另一方面,在服务器不需要先前信息时它的应答就较快。 HTTP协议的几个重要概念 1.连接(Connection):一个传输层的实际环流,它是建立在两个相互通讯的应用程序之间。 2.消息(Message):HTTP通讯的基本单位,包括一个结构化的八元组序列并通过连接传输。 3.请求(Request):一个从客户端到服务器的请求信息包括应用于资源的方法、资源的标识符和协议的版本号 4.响应(Response):一个从服务器返回的信息包括HTTP协议的版本号、请求的状态(例如“成功”或“没找到”)和文档的MIME类型。 5.资源(Resource):由URI标识的网络数据对象或服务。 6.实体(Entity):数据资源或来自服务资源的回映的一种特殊表示方法,它可能被包围在一个请求或响应信息中。 一个实体包括实体头信息和实体的本身内容。 7.客户机(Client):一个为发送请求目的而建立连接的应用程序。 8.用户代理(User agent):初始化一个请求的客户机。 它们是浏览器、编辑器或其它用户工具。 9.服务器(server):一个接受连接并对请求返回信息的应用程序。 10.源服务器(Origin server):是一个给定资源可以在其上驻留或被创建的服务器。 11.代理(Proxy):一个中间程序,它可以充当一个服务器,也可以充当一个客户机,为其它客户机建立请求。 请求是通过可能的翻译在内部或经过传递到其它的服务器中。 一个代理在发送请求信息之前,必须解释并且如果可能重写它。 代理经常作为通过防火墙的客户机端的门户,代理还可以作为一个帮助应用来通过协议处理没有被用户代理完成的请求。 12.网关(Gateway):一个作为其它服务器中间媒介的服务器。 与代理不同的是,网关接受请求就好象对被请求的资源来说它就是源服务器;发出请求的客户机并没有意识到它在同网关打交道。 网关经常作为通过防火墙的服务器端的门户,网关还可以作为一个协议翻译器以便存取那些存储在非HTTP系统中的资源。 13.通道(Tunnel):是作为两个连接中继的中介程序。 一旦激活,通道便被认为不属于HTTP通讯,尽管通道可能是被一个HTTP请求初始化的。 当被中继的连接两端关闭时,通道便消失。 当一个门户(Portal)必须存在或中介(Intermediary)不能解释中继的通讯时通道被经常使用。 14.缓存(Cache):反应信息的局域存储。 HTTP协议的运作方式 HTTP协议是基于请求/响应范式的。 一个客户机与服务器建立连接后,发送一个请求给服务器,请求方式的格式为,统一资源标识符、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。 服务器接到请求后,给予相应的响应信息,其格式为一个状态行包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。 许多HTTP通讯是由一个用户代理初始化的并且包括一个申请在源服务器上资源的请求。 最简单的情况可能是在用户代理(UA)和源服务器(O)之间通过一个单独的连接来完成(见图2-1)。 图2-1 当一个或多个中介出现在请求/响应链中时,情况就变得复杂一些。 中介由三种:代理(Proxy)、网关(Gateway)和通道(Tunnel)。 一个代理根据URI的绝对格式来接受请求,重写全部或部分消息,通过URI的标识把已格式化过的请求发送到服务器。 网关是一个接收代理,作为一些其它服务器的上层,并且如果必须的话,可以把请求翻译给下层的服务器协议。 一个通道作为不改变消息的两个连接之间的中继点。 当通讯需要通过一个中介(例如:防火墙等)或者是中介不能识别消息的内容时,通道经常被使用。 图2-2 上面的图2-2表明了在用户代理(UA)和源服务器(O)之间有三个中介(A,B和C)。 一个通过整个链的请求或响应消息必须经过四个连接段。 这个区别是重要的,因为一些HTTP通讯选择可能应用于最近的连接、没有通道的邻居,应用于链的终点或应用于沿链的所有连接。 尽管图2-2是线性的,每个参与者都可能从事多重的、并发的通讯。 例如,B可能从许多客户机接收请求而不通过A,并且/或者不通过C把请求送到A,在同时它还可能处理A的请求。 任何针对不作为通道的汇聚可能为处理请求启用一个内部缓存。 缓存的效果是请求/响应链被缩短,条件是沿链的参与者之一具有一个缓存的响应作用于那个请求。 下图说明结果链,其条件是针对一个未被UA或A加缓存的请求,B有一个经过C来自O的一个前期响应的缓存拷贝。 图2-3 在Internet上,HTTP通讯通常发生在TCP/IP连接之上。 缺省端口是TCP 80,但其它的端口也是可用的。 但这并不预示着HTTP协议在Internet或其它网络的其它协议之上才能完成。 HTTP只预示着一个可靠的传输。 以上简要介绍了HTTP协议的宏观运作方式,下面介绍一下HTTP协议的内部操作过程。 首先,简单介绍基于HTTP协议的客户/服务器模式的信息交换过程,如图2-4所示,它分四个过程,建立连接、发送请求信息、发送响应信息、关闭连接。 图2-4 在WWW中,“客户”与“服务器”是一个相对的概念,只存在于一个特定的连接期间,即在某个连接中的客户在另一个连接中可能作为服务器。 WWW服务器运行时,一直在TCP80端口(WWW的缺省端口)监听,等待连接的出现。









发表评论