最新 服务器训练神经网络-为何速度慢还容易崩
基础架构与优化实践在人工智能领域,神经网络模型的训练往往需要强大的计算资源支持,服务器作为承载这一任务的核心载体,其硬件配置、软件架构及优化策略直接决定了训练效率与模型性能,本文将从服务器硬件选型、分布式训练框架、性能优化技巧及实际应用案例四个方面,系统阐述服务器训练神经网络的关键要素,硬件选型,计算、存储与网络的协同服务器训练神经网...。

基础架构与优化实践在人工智能领域,神经网络模型的训练往往需要强大的计算资源支持,服务器作为承载这一任务的核心载体,其硬件配置、软件架构及优化策略直接决定了训练效率与模型性能,本文将从服务器硬件选型、分布式训练框架、性能优化技巧及实际应用案例四个方面,系统阐述服务器训练神经网络的关键要素,硬件选型,计算、存储与网络的协同服务器训练神经网...。

随着人工智能技术的飞速发展,深度学习模型在图像识别、自然语言处理等领域取得了突破性进展,这些模型的卓越性能高度依赖于海量数据的训练,当数据规模达到TB甚至PB级别时,单台服务器的计算能力和存储容量便显得捉襟见肘,在此背景下,将大数据处理引擎ApacheSpark与深度学习框架相结合,成为解决大规模数据训练难题的关键路径,为何选择Spa...。

分布式环境下的深度学习随着人工智能技术的快速发展,深度学习已成为推动大数据分析、计算机视觉、自然语言处理等领域进步的核心驱动力,面对海量数据和复杂模型,单机计算能力逐渐成为瓶颈,分布式深度学习通过将计算任务分配到多个计算节点,显著提升了训练效率和模型性能,成为当前深度学习研究与应用的重要方向,本文将从分布式深度学习的架构、关键技术、挑...。

大模型分布式并行技术–数据并行优化2023,11,0120,10,53通信和计算的重叠通常是将通信和计算算子调度到不同的流,stream,上实现的,通信算子调度到通信流,计算算子调度到计算流,同一个流上的算子间是顺序执行的,不同流上的算子可以并行执行,从而实现反向中梯度通信和计算的并行重叠,从上文知道数据并行中需要同步每一个模型梯度,...。
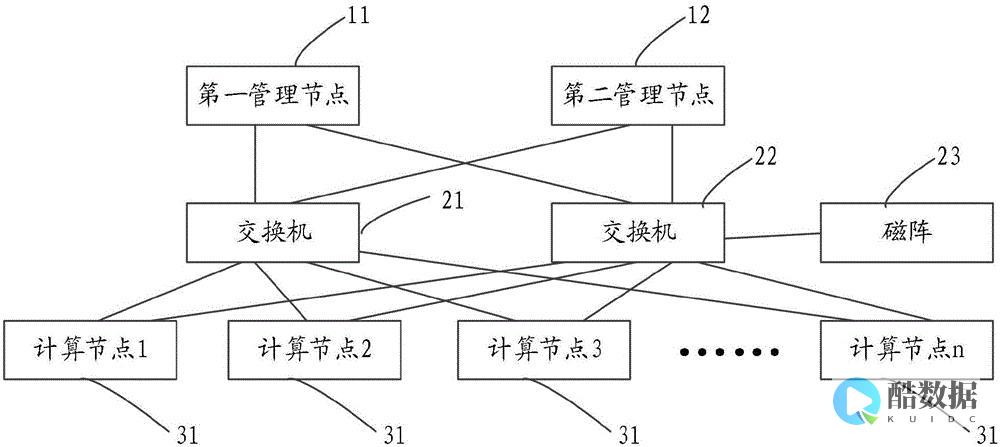
本文将介绍如何在美国GPU服务器上部署和管理分布式训练任务。随着深度学习模型的复杂性增加,单个GPU可能无法满足训练需求,因此分布式训练成为了一种常见的解决方案。本文将介绍如何使用常见的深度学习框架(如TensorFlow、PyTorch)进行分布式训练,以及如何有效地管理和监控训练任务,以提高训练效率和资源利用率。1.硬件准备首先,...

随着深度学习和人工智能的迅速发展,神经网络的训练和优化成为许多行业的核心任务。使用GPU服务器进行模型训练可以大幅提高计算效率,但要实现高效的训练和优化依然需要采用正确的方法和策略。本文将探讨在美国GPU服务器上进行神经网络训练与模型优化的最佳实践,包括硬件选择、数据处理、算法优化及分布式训练等关键方面,以帮助研究人员和开发者充分利用...
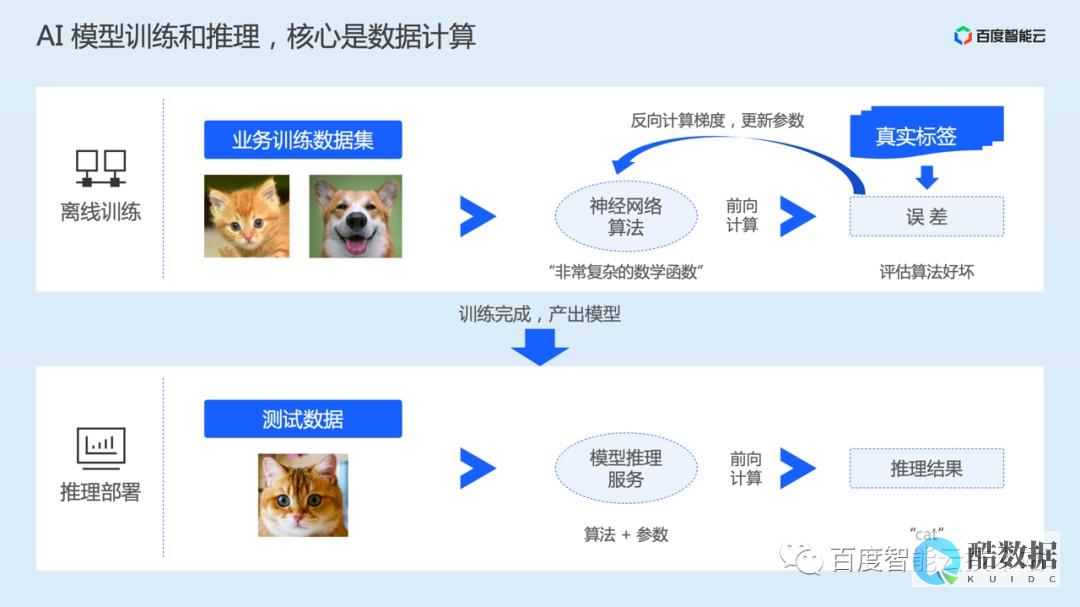
AI模型训练对服务器有以下要求:1.计算资源:需要高性能的多核心CPU和高性能GPU来处理大规模数据和复杂模型。2.存储资源:需要大容量且高速的存储设备来存储大规模的数据集和模型参数。3.分布式训练:使用分布式训练框架将训练任务分配到多台机器上进行并行计算,需要考虑网络连接的速度和稳定性。4.操作系统和电源:选择稳定的操作系统和电源等...