最新 Apache大数据框架有哪些核心组件及适用场景
Apache大数据框架是当今数据处理领域的重要技术体系,由Apache软件基金会维护的一系列开源工具组成,旨在解决海量数据的存储、计算、分析和可视化问题,这些框架通过模块化设计、分布式架构和高可扩展性特性,已成为企业级大数据平台的首选技术栈,以下从核心组件、技术特点、应用场景及发展趋势等方面进行系统阐述,核心组件与架构体系Apache...。

Apache大数据框架是当今数据处理领域的重要技术体系,由Apache软件基金会维护的一系列开源工具组成,旨在解决海量数据的存储、计算、分析和可视化问题,这些框架通过模块化设计、分布式架构和高可扩展性特性,已成为企业级大数据平台的首选技术栈,以下从核心组件、技术特点、应用场景及发展趋势等方面进行系统阐述,核心组件与架构体系Apache...。

JSON数据通常是半结构化、非固定结构的,将来,我们将扩展SparkSQL对JSON支持,以处理数据集中的每个对象可能具有相当不同的结构的情况,例如,考虑使用JSON字段来保存表示HTTP标头的键,值对的数据集,每个记录可能会引入新的标题类型,并为每个记录使用一个不同的列将产生一个非常宽的模式,我们计划支持自动检测这种情况,而是使用m...。

本文从数据倾斜的危害、现象、原因等方面,由浅入深阐述Spark数据倾斜及其解决方案,一、什么是数据倾斜对Spark,Hadoop这样的分布式大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜,对于分布式系统而言,理想情况下,随着系统规模,节点数量,的增加,应用整体耗时线性下降,如果一台机器处理一批大量数据需要120分钟,当机器数量增加...。

Redis是一种流行的开源数据存储和处理系统,可以高效地处理各种类型的数据,如文件、字符串和哈希等,RedisHash算法是Redis中最常用的数据类型之一,它的性能非常出色,可以处理亿万级别的数据,RedisHash算法是一个类似于数据库中表的数据结构,可以存储键值对,每个键对应一个值,RedisHash支持各种操作,包括插入、删除...。

在当今数字化时代,数据被认为是最宝贵的资源之一,而对于大数据处理领域来说,Spark作为一款快速、通用、可扩展的大数据处理引擎,被广泛应用于数据处理和分析中,而Hive则是一个建立在Hadoop之上的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,介绍如何使用Spark读取JSON数据并将其写入Hive中...。

spark自己的分布式存储系统–BlockManager2018,05,1009,34,21BlockManager是spark中至关重要的一个组件,在spark的的运行过程中到处都有BlockManager的身影,只有搞清楚BlockManager的原理和机制,你才能更加深入的理解spark,今天我们来揭开BlockaManager...。

随着大数据技术的发展,Spark和Hive都成为了数据处理领域中的重要工具,Spark是一个高效的分布式计算框架,可以用来处理大数据;而Hive是一个基于Hadoop的数据仓库工具,可以让用户使用SQL语言来查询和分析数据,在实际的数据处理工作中,Spark和Hive往往需要同时使用,因此在Spark中使用Hive数据库变得非常重要,...。

解析SparkStreaming和Kafka集成的两种方式2020,02,2117,33,17SparkStreaming是基于微批处理的流式计算引擎,通常是利用SparkCore或者SparkCore与SparkSql一起来处理数据,在企业实时处理架构中,通常将SparkStreaming和Kafka集成作为整个大数据处理架构的核心...。

Spark查询优化,提升关系型数据库性能随着数据量的不断增加,传统的关系型数据库在处理海量数据时显得力不从心,而Spark作为一种高速、通用、可扩展、分布式内存计算引擎,已成为处理大数据和机器学习任务的首选工具之一,在现实应用中,人们经常需要将关系型数据库数据导入到Spark中,来进行各种数据的分析和处理,但是,因为关系型数据库和Sp...。

Livy是一个提供Rest接口和spark集群交互的服务,它可以提交SparkJob或者Spark一段代码,同步或者异步的返回结果,也提供Sparkcontext的管理,通过Restful接口或RPC客户端库,Livy也简化了与Spark与应用服务的交互,这允许通过web,mobile与Spark的使用交互,...。

在当今大数据时代,Spark已经成为了一个非常受欢迎的开源分布式计算框架,对于想要在Linux上进行Spark开发的开发者来说,首先需要搭建一个可用的Spark开发环境,本文将为大家介绍如何在Linux上进行Spark开发,并简单介绍如何运行一个简单的Spark程序,1.准备环境之一步是确保您在Linux环境中安装了Java,如果尚未...。

JVM默认会通过JMX的方式暴露基础指标,很多中间件也会通过JMX的方式暴露业务指标,比如Kafka、Zookeeper、ActiveMQ、Cassandra、Spark、Tomcat、Flink等等,掌握了JMX监控方式,就掌握了一批程序的监控方式,本节介绍JMX,Exporter的使用,利用JMX,Exporter把JMX监控数据...。

三分钟读懂Hadoop、HBase、Hive、Spark分布式系统架构2020,04,0315,35,53我们来分别部署一套hadoop、hbase、hive、spark,在讲解部署方法过程中会特殊说明一些重要配置,以及一些架构图以帮我们理解,目的是为后面讲解系统架构和关系打基础,机器学习、数据挖掘等各种大数据处理都离不开各种开源分布...。

Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的,partition,、多副本的,replica,,基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于hadoop的批处理系统、低延迟的实时系统、storm,Spark流式处理引擎,web,nginx日志、...。

从dba转大数据是可行的,因为两者都需要处理大量数据和优化性能。dba的数据库管理经验有助于在大数据分析中发挥作用,但需学习新的技能如hadoop、spark等大数据技术。从数据库管理员(DBA)转型到大数据领域,是当前许多技术从业者面临的一个重要选择,随着数据量的爆炸性增长和大数据技术的广泛应用,传统的DBA角色正在发生显著变化,需...
Eagle–来自eBay的分布式实时监控及预警框架2015-07-2815:51:45Eagle是来自eBay的面向大型分布式系统比如Hadoop,Spark以及Cloud等设计的通用实时监控与与预警框架。主要由基础的核心框架以及针对不同应用领域的诸多app组成,专注于解决大数据时代大型分布式系统自身监控这个复杂的大数据问题,具有高扩...
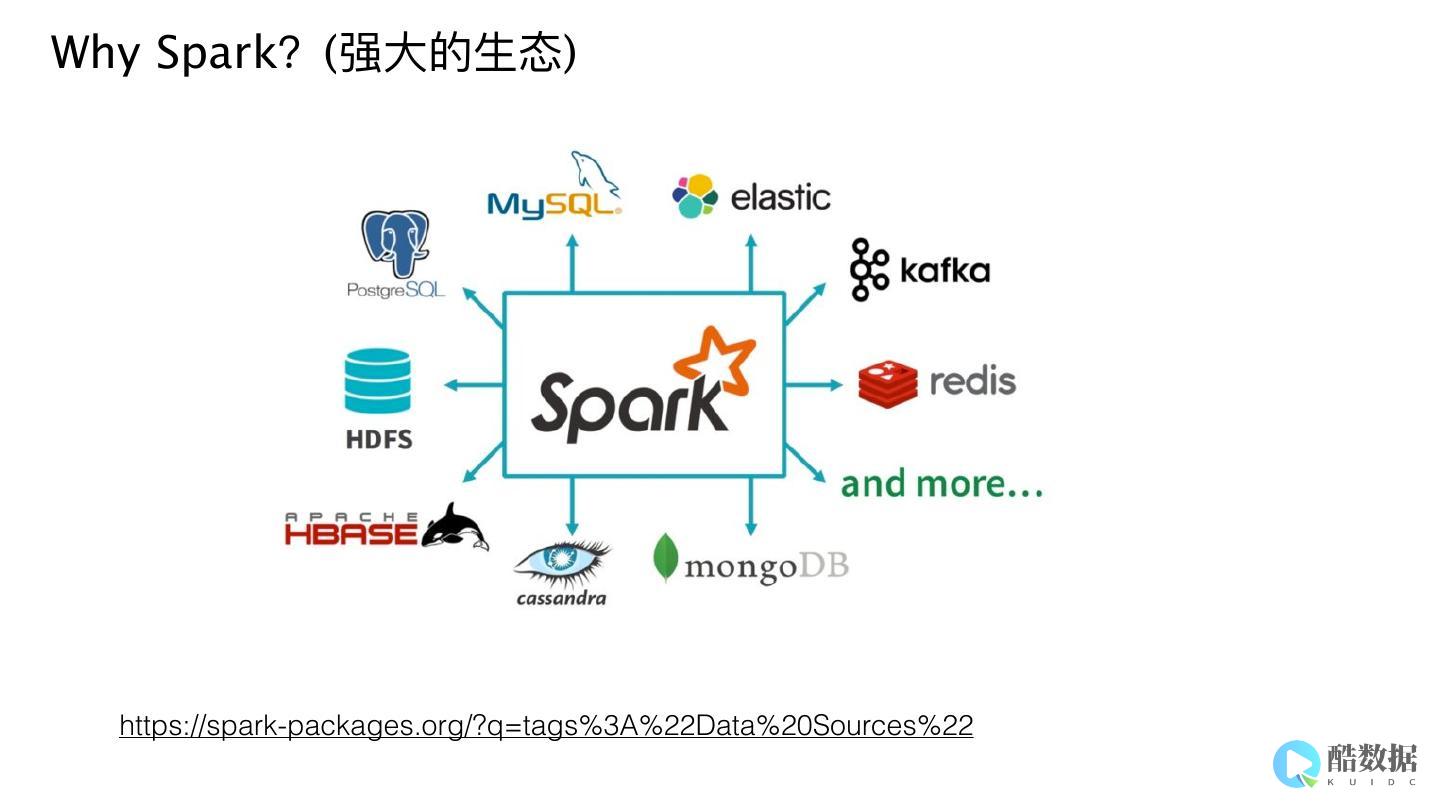
SparkStreaming与Kafka整合遇到的问题及解决方案2017-08-0309:37:35最近工作中是做日志分析的平台,采用了sparkstreaming+kafka,采用kafka主要是看中了它对大数据量处理的高性能,处理日志类应用再好不过了,采用了sparkstreaming的流处理框架主要是考虑到它本身是基于spark...

SparkStreaming与Kafka整合遇到的问题及解决方案2017-08-0309:37:35最近工作中是做日志分析的平台,采用了sparkstreaming+kafka,采用kafka主要是看中了它对大数据量处理的高性能,处理日志类应用再好不过了,采用了sparkstreaming的流处理框架主要是考虑到它本身是基于spark...
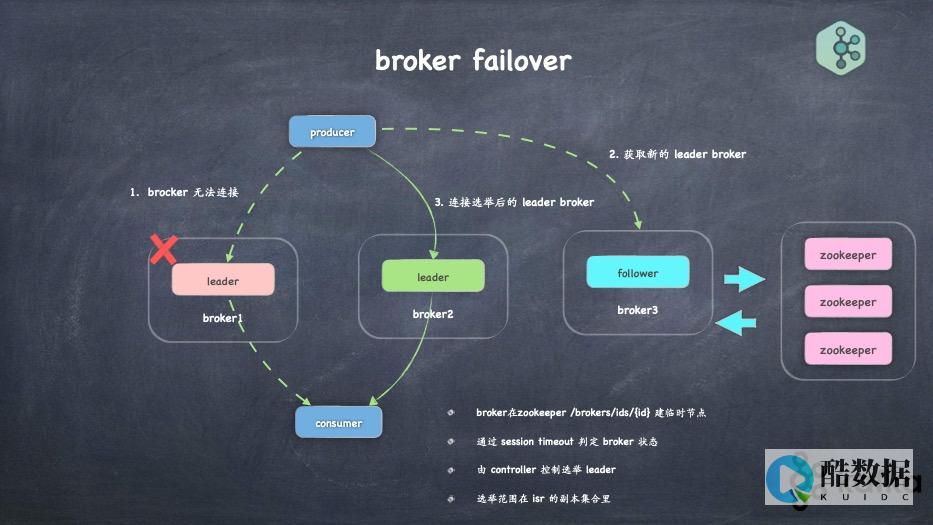
使用Kafka和Druid了解Spark流2020-05-1410:26:27在本博文中,我将分享通过将SparkStreaming,Kafka和ApacheDruid结合在一起以构建实时分析仪表板,以确保精确的数据表示而获得的知识。作为一名数据工程师,我正在研究大数据技术,例如SparkStreaming,Kafka和ApacheD...