

使用Kafka和Druid了解spark流
2020-05-14 10:26:27在本博文中,我将分享通过将Spark Streaming,Kafka和Apache Druid结合在一起以构建实时分析仪表板,以确保精确的数据表示而获得的知识。
作为一名数据工程师,我正在研究大数据技术,例如Spark Streaming,Kafka和Apache Druid。 他们都有自己的教程和RTFM页面。 但是,将这些技术大规模地组合在一起时,您会发现自己正在寻找涵盖更复杂的生产用例的解决方案。 在本博文中,我将分享通过将Spark Streaming,Kafka和Apache Druid结合在一起以构建实时分析仪表板,以确保精确的数据表示而获得的知识。
在开始之前……关于实时分析的几句话
实时分析是大数据技术的新趋势,通常具有显着的业务影响。 在分析新鲜数据时,见解更加精确。 例如,为数据分析师,BI和客户经理团队提供实时分析仪表板可以帮助这些团队做出快速决策。 大规模实时分析的常用架构基于Spark Streaming和Kafka。 这两种技术都具有很好的可扩展性。 它们在群集上运行,并在许多计算机之间分配负载。 Spark作业的输出可以到达许多不同的目的地,这取决于特定的用例和体系结构。 我们的目标是提供显示实时事件的可视工具。 为此,我们选择了Apache Druid数据库。
Apache Druid中的数据可视化
Druid是高性能的实时分析数据库。 它的好处之一是能够使用来自Kafka主题的实时数据,并使用Pivot模块在其上构建强大的可视化效果。 它的可视化功能可以运行各种临时的”切片和切块”查询,并快速获得可视化结果。 这对于分析各种用例非常有用,例如特定运动在某些国家的表现。 实时检索数据,延迟1-2分钟。
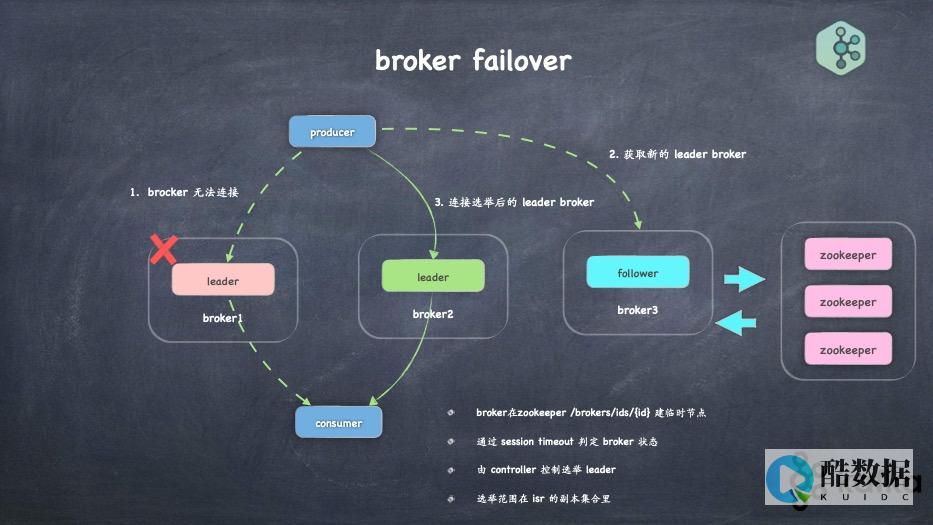
架构
因此,我们决定基于Kafka事件和Apache Druid构建实时分析系统。 我们已经在Kafka主题中进行过活动。 但是我们不能将它们直接摄取到德鲁伊中。 我们需要为每个事件添加更多维度。 我们需要用更多的数据丰富每个事件,以便在德鲁伊中方便地查看它。 关于规模,我们每分钟要处理数十万个事件,因此我们需要使用能够支持这些数字的技术。 我们决定使用Spark Streaming作业丰富原始的Kafka事件。
图1.实时分析架构
Spark Streaming作业永远运行? 并不是的。
Spark Streaming作业的想法是它始终在运行。 这项工作永远都不应停止。 它不断读取来自Kafka主题的事件,对其进行处理,并将输出写入另一个Kafka主题。 但是,这是一个乐观的看法。 在现实生活中,事情更加复杂。 Spark群集中存在驱动程序故障,在这种情况下,作业将重新启动。 有时新版本的spark应用程序已部署到生产中。 在这种情况下会发生什么? 重新启动的作业如何读取Kafka主题并处理事件? 在深入研究这些细节之前,此图显示了重新启动Spark Streaming作业时在Druid中看到的内容:
图2.作业重新启动时数据丢失
绝对是数据丢失!
我们要解决什么问题?
我们正在处理Spark Streaming应用程序,该应用程序从一个Kafka主题读取事件,并将事件写入另一个Kafka主题。 这些事件稍后将在Druid中显示。 我们的目标是在重新启动Spark Streaming应用程序期间实现平滑的数据可视化。 换句话说,我们需要确保在Spark Streaming作业重启期间不会丢失或重复任何事件。
都是关于补偿
为了理解为什么作业重新启动时会丢失数据,我们需要熟悉Kafka体系结构中的一些术语。 您可以在这里找到Kafka的官方文档。 简而言之:Kafka中的事件存储在主题中; 每个主题都分为多个分区。 分区中的每个记录都有一个偏移量-一个连续的数字,它定义了记录的顺序。 当应用程序使用该主题时,它可以通过多种方式处理偏移量。 默认行为始终是从最新的偏移量读取。 另一个选择是提交偏移量,即持久保留偏移量,以便作业可以在重新启动时读取已提交的偏移量并从此处继续。 让我们看一下解决方案的步骤,并在每个步骤中加深对Kafka胶印管理的了解。
步骤#1-自动提交偏移量
默认行为始终是从最新的偏移量读取。 这将不起作用,因为重新启动作业时,该主题中有新事件。 如果作业从最新读取,它将丢失重新启动期间添加的所有消息,如图2所示。Spark Streaming中有一个” enable.auto.commit”参数。 默认情况下,其值为false。 图3显示了将其值更改为true,运行Spark应用程序并重新启动后的行为。
图3.作业重启的数据峰值
我们可以看到,使用Kafka自动提交功能会产生新的效果。 没有”数据丢失”,但是现在我们看到重复的事件。 没有真正的事件”爆发”。 实际发生的情况是自动提交机制”不时”提交偏移量。 输出主题中有许多未提交的消息。 重新启动后,作业将使用最新提交的偏移量中的消息,并再次处理其中一些事件。 这就是为什么在输出中会出现大量事件的原因。
显然,将这些重复项合并到我们的可视化中可能会误导业务消费者此数据,并影响他们的决策和对系统的信任。
步骤#2:手动提交Kafka偏移
因此,我们不能依靠Kafka自动提交功能。 我们需要自己进行卡夫卡补偿。 为了做到这一点,让我们看看Spark Streaming如何使用Kafka主题中的数据。 Spark Streaming使用称为离散流或DStream的体系结构。 DStream由一系列连续的RDD(弹性分布式数据集)表示,这是Spark的主要抽象之一。 大多数Spark Streaming作业如下所示:
在我们的案例中,处理记录意味着将记录写入输出Kafka主题。 因此,为了提交Kafka偏移量,我们需要执行以下操作:
这是一种简单明了的方法,在我们深入讨论之前,让我们看一下大局。 假设我们正确处理了偏移量。 即,在每次RDD处理之后都保存偏移量。 当我们停止工作时会怎样? 该作业在RDD的处理过程中停止。 微批处理的部分将写入输出Kafka主题,并且不会提交。 一旦作业再次运行,它将第二次处理某些消息,并且重复消息的峰值将(与以前一样)出现在Druid中:
图4.作业重新启动时的数据峰值
正常关机
事实证明,有一种方法可以确保在RDD处理期间不会杀死作业。这称为”正常关机”。有几篇博客文章描述了如何优雅地杀死Spark应用程序,但是其中大多数与旧版本的Spark有关,并且有很多限制。我们一直在寻找一种适用于任何规模且不依赖于特定Spark版本或操作系统的”安全”解决方案。要启用正常关机,应使用以下参数创建Spark上下文:spark.streaming.sTopGracefullyOnShutdown = true。这指示Spark在JVM关闭时(而不是立即)正常关闭StreamingContext。另外,我们需要一种机制来有意地停止工作,例如在部署新版本时。我们已经通过简单地检查是否存在指示作业关闭的HDFS文件来实现该机制的第一个版本。当文件显示在HDFS中时,流上下文将使用以下参数停止:ssc.stop(stopSparkContext = true,stopGracefully = true)
在这种情况下,只有在完成所有接收到的数据处理之后,Spark应用程序才会正常停止。 这正是我们所需要的。
步骤#3:Kafka commitAsync
让我们回顾一下到目前为止的情况。 我们有意在每个RDD处理中提交Kafka偏移量(使用Kafka commitAsync API),并使用Spark正常关机。 显然,还有另一个警告。 深入研究Kafka API和Kafka commitAsync()源代码的文档,我了解到commitAsync()仅将offsetRanges放入队列中,实际上仅在下一个foreachRDD循环中进行处理。 即使Spark作业正常停止并完成了所有RDD的处理,实际上也不会提交最后一个RDD的偏移量。 为解决此问题,我们实现了一个代码,该代码可同步保留Kafka偏移量,并且不依赖于Kafka commitAsync()。 然后,对于每个RDD,我们将提交的偏移量存储在HDFS文件中。 当作业再次开始运行时,它将从HDFS加载偏移文件,并从这些偏移开始使用Kafka主题。
在这里,它有效!
仅仅是正常关机和Kafka偏移量同步存储的组合,才为我们提供了理想的结果。 重新启动期间没有数据丢失,没有数据高峰:
图5.重新启动Spark作业期间没有峰值数据丢失
结论
解决Spark Streaming和Kafka之间的集成问题是构建实时分析仪表板的重要里程碑。 我们找到了可以确保稳定的数据流的解决方案,而不会在Spark Streaming作业重启期间丢失事件或重复。 现在,我们获得了在Druid中可视化的可信赖数据。 因此,我们将更多类型的事件(Kafka主题)添加到了Druid中,并建立了实时仪表板。 这些仪表板为各种团队提供了见解,例如BI,产品和客户支持。 我们的下一个目标是利用Druid的更多功能,例如新的分析功能和警报。
linux怎么安装
可使用光盘引导进去安装,具体操作及事项如下:Linux安装前的准备工作 1.用Windows系统收集硬件信息 在安装Linux之前,您需要借助Windows系统了解计算机硬件的基本信息,如内存大小、声卡、显示器、鼠标和显卡型号等。 2.设置从光盘引导系统 Linux支持几种安装方式,但直接以光盘开机启动进行安装最方便和快速。 若要机器以光盘启动,需要修改BIOS的设置,将CD-ROM变更至开机顺序的第一位。 3.Linux分区 Linux分区的表示方法 分区就是将磁盘驱动器分隔成独立的区域,每个区域都如同一个单独的磁盘驱动器,在DOS/Windows系统下磁盘分区可分为C、 D和E盘等。 但Linux则将磁盘视为块设备文件来管理使用,它以 /dev(device的缩写)开头表示。 例: 在Linux用 “/dev/hda1”表示Windows下的C盘 其中:hd 表示IDE硬盘(SCSI硬盘用sd);hda 为 第一个IDE 硬盘(第二为 hdb);/dev/hda1 为主分区,逻辑分区 从5 开始,如: /dev/hda5、/dev/hda6、/dev/hda7等。 为Linux准备分区 Linux分区和Windows分区不同,不能共用。 所以需要为Linux单独开辟一个空闲的分区,最好是最后一个分区。 如图1中利用Windows下的Partition Magic(分区魔法)软件,在D盘上腾出空间创建新分区E盘(或利用已有的空闲E盘),文件类型暂设为FAT32,作为稍后创建Linux分区使用,RedHat 9.0 大约需4 ~ 5GB的空间。 4.Linux 的文件系统 对于不同的操作系统,文件系统也不同。 Windows文件系统为FAT16、FAT32和NTFS。 而Linux的文件系统可分为ext2、ext3、swap和vfat。 ext2支持最多为255 个字符的文件名;ext3 是基于 ext2之上,主要优点是减少系统崩溃后恢复文件系统所花费的时间,RedHat 9.0 默认文件系统为ext3;交换区swap是被用于支持虚拟内存;Windows的FAT分区在Linux下显示为vfat文件类型。
近期我想买车,七万到九万的车哪款好呢?年轻家庭使用.谢谢!
如果想选 “两厢车”的话.. 哈飞路宝、哈飞赛马、雪佛兰Spark、POLO..等等都可以.总体的性能不错,车内空间也比较宽敞,动力有保证,并且小排量更加节油经济.. 作为代步车足够了...“三厢车”的话.. 选择面就比较广了, 但我个人比较倾向于“富康”、捷达 ,原因主要是,市场保有量大,配件相对便宜,车型耐看,性能稳定,耗油量可以接受.. 雪佛兰LOVA乐风1.4SL MT 也是很好的选择..目前8.18万的价位包含的配置有前排双安全气囊、ABS防抱死制动系统、EBD电子制动力分配系统等等,在安全与行车方面,个人很佩服雪佛兰的这种经营理念----安全第一,在同价位段的车型中可以说是为数不多的,高性价比车型之一。(车型很时尚、活力、运动、动力与质量有保证)当然,其他的.. 比如:赛欧、威驰、等等,包括再贵一些的品牌:现代等等都可以,主要还是看你自己的感觉了..补充回答: 强烈推荐 “哈飞”赛马1.3或1.6排量..价位:5.98万---9万不等..手动与自动1.6..全三菱技术发动机..(发动机上三菱标志..国内生产组装成型)动力与稳定运行有保证..车身为日本原形车:DINGO..可装载空间于同类车佼佼者,乘坐感相当舒适,车内高度也设计得很广阔,不会感觉压抑.. 视野很好..~外观上可以说跟越野车很类似.. 如果有兴趣的话可以去看看.~ :)
dota德鲁伊攻略
两种套路 一种野区流,出门补刀斧,3树枝,其他恢复装 召你的小熊直接扎进野区打野吧。 。 比较主流的打法,先打出个鞋子,然后可以考虑直接奔辉耀,如果出了辉耀记住放小熊身上不要自己带。 。 小熊比你耐打多了,这种打法一定要你的队友有好的意识,多插眼,前期在野区被抓几次你就算废了。 。 毕竟我认为德鲁伊并不是一个有辉耀能逆天的英雄(他不是猴子),所以辉耀至少半小时前做出,然后你就出假腿自己带,出相位小熊带,出吸血鬼的祭品,然后可以蝴蝶或者大电锤自己带,出个振奋给小熊,出个BKB给自己,后面就无所谓了 如果线上压力不大可以直接在线上打钱,毕竟线上的钱比野区多多了,当然这是非主流打法啦,呵呵,补刀不好会被队友喷死。 。 逆风打法:自己先假腿,然后给小熊鞋子,然后出祭品,小熊合相位,再给小熊几个加速手套,然后自己出先锋盾撑撑血吧 顺风打法:裸辉耀不解释,给小熊,相位鞋给小熊,自己再出假腿,然后自己出祭品,然后小熊出个强袭,然后自己BKB,蝴蝶,大电锤什么的













发表评论