

随着大数据时代的到来,对于大规模数据的处理和分析需求越来越迫切。利用GPU服务器可以提供高性能的计算能力,加速大规模数据的处理和分析过程。下面将介绍如何在GPU服务器上实现高性能的大规模数据处理和分析。
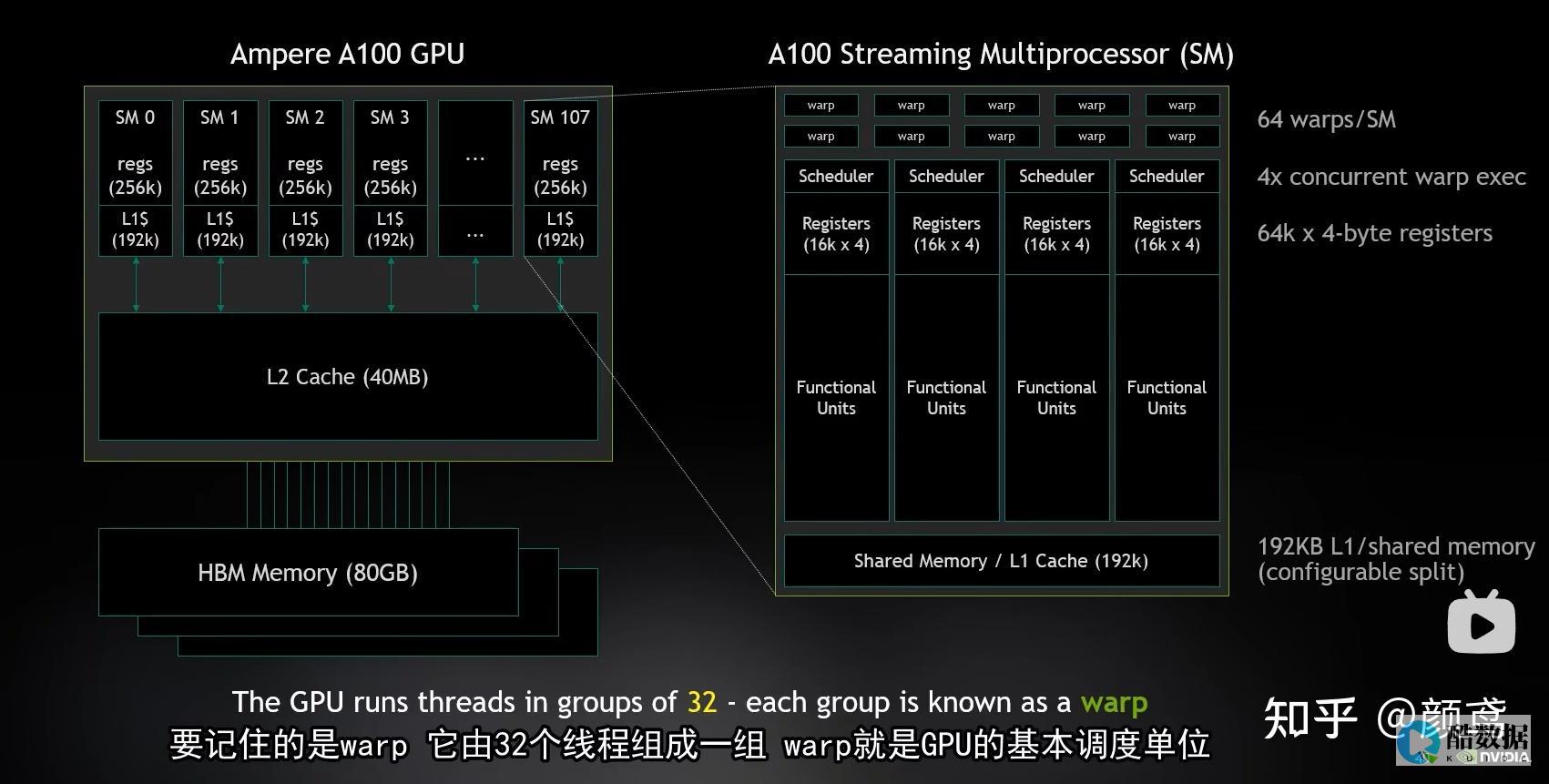
一、选购适合的GPU服务器
GPU型号选择:根据实际需求和预算,选择适合的GPU型号。NVIDIA是目前常见的GPU供应商,其GPU型号包括Tesla、Quadro和GeForce等,具有不同的性能和价格特点。
GPU数量和配置:根据数据处理和分析的复杂程度,选择适当数量和配置的GPU。多个GPU可以并行处理任务,提高计算效率。
存储和内存容量:大规模数据处理和分析需要大量的存储和内存容量,确保GPU服务器具备足够的存储和内存资源。
二、优化算法和并行计算
并行算法设计:针对大规模数据处理和分析任务,设计并行算法,充分利用GPU的并行计算能力。可以使用CUDA或OpenCL等编程框架进行开发。
数据分批处理:将大规模数据分批加载到GPU内存中,并通过循环迭代的方式进行处理和分析,避免一次性加载过多数据导致内存溢出。
内存管理:合理管理GPU内存,在任务执行过程中及时释放不再需要的中间结果,以避免内存耗尽的问题。
三、调整硬件和软件配置
驱动和库更新:及时更新GPU驱动程序和相关库文件,确保系统和应用程序与GPU服务器的兼容性。
温度和功耗控制:GPU服务器的高性能计算可能导致温度升高和功耗增加,需要确保散热和电源供应的稳定,避免系统崩溃或性能下降。
监控和调优工具:使用监控和调优工具,实时监测GPU服务器的性能指标,识别瓶颈并进行优化,以提高数据处理和分析的效率。
总之,利用GPU服务器可以实现高性能的大规模数据处理和分析。通过选购适合的GPU服务器、优化算法和并行计算、调整硬件和软件配置,可以充分发挥GPU服务器的计算潜力,加速数据处理和分析过程,提高工作效率和决策准确性。
好主机测评广告位招租-300元/3月我要当网管了,谁说下当网管的常识
其实网管的任务主要就是保护系统安全和网络的正常运转,关于这方面有几点取得了大多数网管的认可: 1.操作系统应该是服务器版本的,并且,应该使用英文版的正版系统,尤其对于Microsoft Windows系列,如果系统出现漏洞,英文版系统的补丁永远比中文版的发布的早;2.权限能给多小就给多小,能不给就不给,尤其是关系到有配置系统的权限的账户;3.使用强密码;关闭不必要的系统服务(如Terminal Service)和全部默认共享;4.不要在服务器上安装任何不必要的软件,如QQ之类的;5.在资金允许的情况下,一款强大的硬件防火墙可以极大的保障主机的安全。 这些是极浅的东西,不过却很有用。 你可以找本类似“Windows 2000 安全参考”之类的书看看,虽然内容很多,但是会很有帮助
哪些行业适合大数据APP开发
信息流广告属于原生广告的一种类型,可以显示在多个平台的内容当中,看似软广的一种形式,一般不会直接引起人们的厌恶。做好信息流推广,最重要的是做好落地页,落地页上面有很多的文章可以做,有吸引力的文案、图片都是吸引点击的一种方式,因此需要精心设计好,留下客户信息,能够实现转化的效果
hadoop的优点有哪些 a处理超大文件 b低延迟访问数据
一、 Hadoop 特点 1、支持超大文件 一般来说,HDFS存储的文件可以支持TB和PB级别的数据。 2、检测和快速应对硬件故障 在集群环境中,硬件故障是常见性问题。 因为有上千台服务器连在一起,故障率高,因此故障检测和自动恢复hdfs文件系统的一个设计目标。 假设某一个datanode节点挂掉之后,因为数据备份,还可以从其他节点里找到。 namenode通过心跳机制来检测datanode是否还存在 3、流式数据访问 HDFS的数据处理规模比较大,应用一次需要大量的数据,同时这些应用一般都是批量处理,而不是用户交互式处理,应用程序能以流的形式访问数据库。 主要的是数据的吞吐量,而不是访问速度。 访问速度最终是要受制于网络和磁盘的速度,机器节点再多,也不能突破物理的局限,HDFS不适合于低延迟的数据访问,HDFS的是高吞吐量。 4、简化的一致性模型 对于外部使用用户,不需要了解hadoop底层细节,比如文件的切块,文件的存储,节点的管理。 一个文件存储在HDFS上后,适合一次写入,多次写出的场景once-write-read-many。 因为存储在HDFS上的文件都是超大文件,当上传完这个文件到hadoop集群后,会进行文件切块,分发,复制等操作。 如果文件被修改,会导致重新出发这个过程,而这个过程耗时是最长的。 所以在hadoop里,不允许对上传到HDFS上文件做修改(随机写),在2.0版本时可以在后面追加数据。 但不建议。 5、高容错性 数据自动保存多个副本,副本丢失后自动恢复。 可构建在廉价机上,实现线性(横向)扩展,当集群增加新节点之后,namenode也可以感知,将数据分发和备份到相应的节点上。 6、商用硬件 Hadoop并不需要运行在昂贵且高可靠的硬件上,它是设计运行在商用硬件的集群上的,因此至少对于庞大的集群来说,节点故障的几率还是非常高的。 HDFS遇到上述故障时,被设计成能够继续运行且不让用户察觉到明显的中断。 二、HDFS缺点 1、不能做到低延迟 由于hadoop针对高数据吞吐量做了优化,牺牲了获取数据的延迟,所以对于低延迟数据访问,不适合hadoop,对于低延迟的访问需求,HBase是更好的选择, 2、不适合大量的小文件存储 由于namenode将文件系统的元数据存储在内存中,因此该文件系统所能存储的文件总数受限于namenode的内存容量,根据经验,每个文件、目录和数据块的存储信息大约占150字节。 因此,如果大量的小文件存储,每个小文件会占一个数据块,会使用大量的内存,有可能超过当前硬件的能力。 3、不适合多用户写入文件,修改文件 Hadoop2.0虽然支持文件的追加功能,但是还是不建议对HDFS上的 文件进行修改,因为效率低。 对于上传到HDFS上的文件,不支持修改文件,HDFS适合一次写入,多次读取的场景。 HDFS不支持多用户同时执行写操作,即同一时间,只能有一个用户执行写操作。









发表评论