
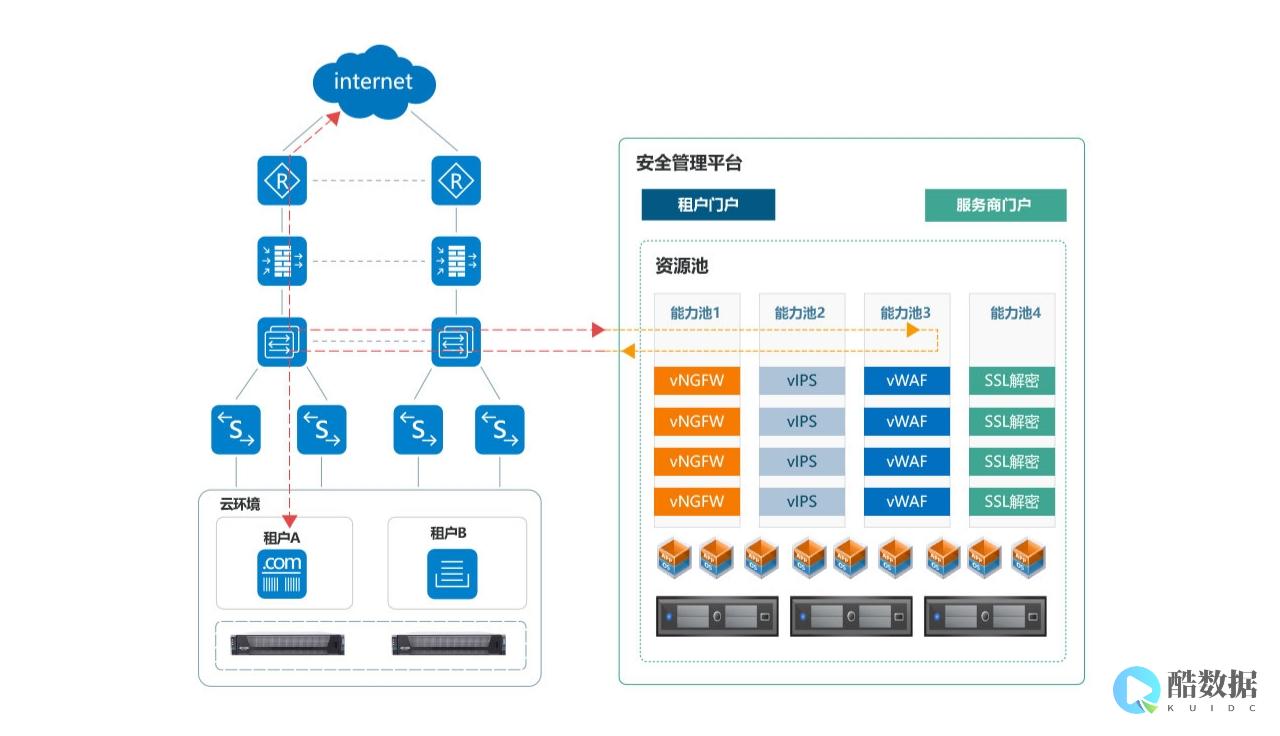
分布式数据库作为应对大规模数据和高并发场景的核心技术,通过分布式架构实现了数据存储、计算和管理能力的水平扩展,其实现涉及数据分片、分布式事务、一致性协议、数据复制、负载均衡、故障恢复及查询优化等多个关键技术模块,各模块协同工作以保障系统的高可用、可扩展与一致性。

数据分片:分布式存储的基石
数据分片是分布式数据库实现水平扩展的核心,通过将数据拆分为多个分片(Shard)存储在不同节点,突破单节点的存储和性能瓶颈,分片策略需兼顾数据均匀性、查询效率与扩展性,常见策略包括:
分片后需通过元数据管理(如ZooKeeper、etcd)记录分片与节点的映射关系,确保数据定位的准确性。
分布式事务:跨节点数据一致性的保障
分布式事务需保证跨多个节点的操作满足ACID特性(原子性、一致性、隔离性、持久性),实现难度远超单机事务,主流方案包括:
一致性协议:分布式节点的“共识引擎”
分布式节点间需通过一致性协议达成数据共识,常见的有:
数据复制:高可用与容错的基石
数据复制通过将数据副本存储在多个节点,提升系统可用性和容错能力,常见复制模式包括:
负载均衡:资源优化的关键
分布式数据库需通过负载均衡避免单节点过载,优化资源利用率,常见策略包括:
故障恢复:系统鲁棒性的保障
分布式数据库需通过故障检测与恢复机制应对节点宕机、网络分区等问题:
查询优化:分布式查询性能的提升
分布式查询需优化跨节点数据访问效率,关键包括:
分布式数据库的实现是多技术协同的结果,需在一致性、可用性、分区容错性(CAP理论)中根据业务场景权衡,随着云原生、Serverless等技术的发展,分布式数据库将进一步简化运维、提升弹性,成为支撑海量数据服务的核心基础设施。











发表评论