
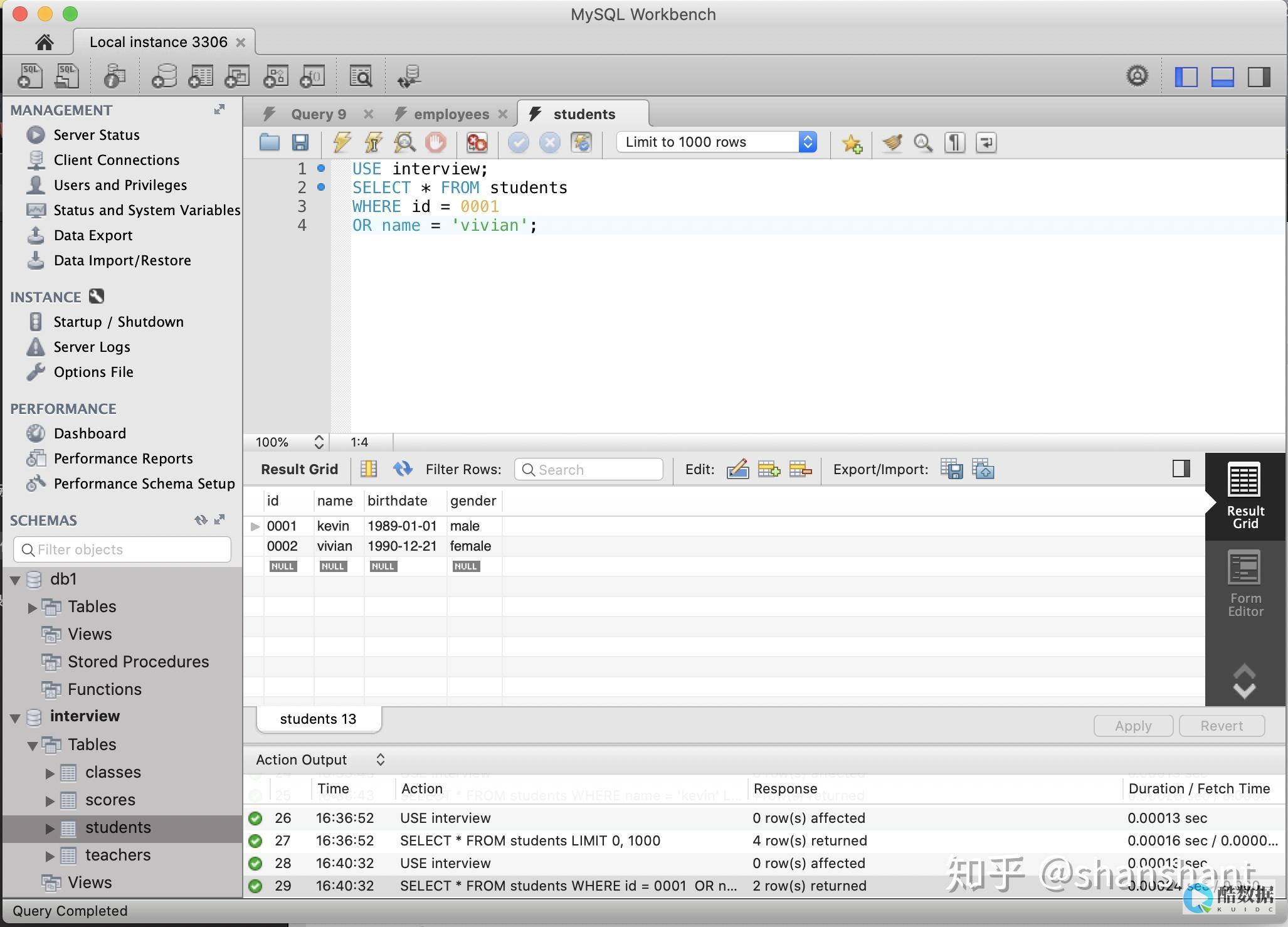
SELECT COUNT(*) FROM table_name;
CI数据库中的和
count_all_results
方法用于统计表中记录的数量,下面将详细介绍这两种方法的使用方法、示例代码以及常见问题解答。
一、count_all方法
基本用法:
无条件计数 :直接统计整个表的记录数。
有条件计数 :结合where()等条件函数进行特定条件的记录计数。
示例代码:
// 无条件计数$total = $this->db->count_all('tableName');echo $total; // 输出表中总记录数// 有条件计数$this->db->where('sex', 'M');$this->db->from('user');$total = $this->db->count_all_results();echo $total; // 输出符合条件的记录数
二、count_all_results方法
基本用法:
带条件计数 :通过Active Record查询语句获取结果数量。
 多条件组合
:可以结合多个条件函数如,
多条件组合
:可以结合多个条件函数如,
or_where()
,等。
示例代码:
// 使用Active Record查询并计算结果数量$this->db->like('title', 'match');$this->db->from('my_table');$total = $this->db->count_all_results();echo $total; // 输出符合条件的记录数
三、 分页功能
基本用法:
配置分页参数 :设置每页显示记录数、当前页码等。
生成分页链接 :使用pagination库生成分页链接。
示例代码:
// 配置分页参数$config['base_url'] = base_url();$config['total_rows'] = $this->db->count_all('tableName');$config['per_page'] = 10;$config['uri_segment'] = 3;// 初始化分页类$this->pagination->initialize($config);// 生成分页链接并输出echo $this->pagination->create_links();
四、相关问题与解答
1. count_all和count_all_results的区别?
答
:用于无条件的计数,直接统计整个表的记录数;而
count_all_results
用于有条件的计数,需要先通过Active Record查询语句设置条件,再获取符合条件的记录数。
2. 如何在SQL语句中使用COUNT(*)进行计数?
答 :可以在SQL语句中使用进行计数,
$sql = "SELECT COUNT(*) as num FROM user WHERE sex='male'";$res = $this->db->query($sql)->row_array();$num = $res['num'];echo $num; // 输出符合条件的记录数
这种方法适用于复杂的查询需求,但性能可能不如
count_all_results
高效。
各位小伙伴们,我刚刚为大家分享了有关“ ci数据库 count ”的知识,希望对你们有所帮助。如果您还有其他相关问题需要解决,欢迎随时提出哦!
access的数据库中的查询有什么意义?
在使用表存储数据的时候我们都有侧重点,通过它们的名字就可以看出这个表是用来做什么的,这样很容易就可以知道哪些表中存储有什么数据内容。 很少有人会把表的名字起成“表一”、“表二”的。 如果有很多表的话,这样根本就不知道这些表存储了什么内容。 所以我们在建立表的时候,首先想的就是要把同一类的数据放在一个表中,然后给这个表取个一目了然的名字,这样管理起来会方便得多。 但是另一方面,我们在实际工作中使用数据库中的数据时,并不是简单地使用这个表或那个表中的数据,而常常是将有“关系”的很多表中的数据一起调出使用,有时还要把这些数据进行一定的计算以后才能使用。 如果再建立一个新表,把要用到的数据拷贝到新表中,并把需要计算的数据都计算好,再填入新表中,就显得太麻烦了,用“查询”对象可以很轻松地解决这个问题,它同样也会生成一个数据表视图,看起来就像新建的“表”对象的数据表视图一样。 “查询”的字段来自很多互相之间有“关系”的表,这些字段组合成一个新的数据表视图,但它并不存储任何的数据。 当我们改变“表”中的数据时,“查询”中的数据也会发生改变。 计算的工作也可以交给它来自动地完成,完全将用户从繁重的体力劳动中解脱出来,充分体现了计算机数据库的优越性。 让我们在数据库中建立一个“查询”,看看“查询”究竟有什么用,该怎么用。 我们现在用的“查询”是“选择查询”,这种查询很好学,而且用得也很普遍,很多数据库查询功能都可以用它来实现。 顾名思义,“选择查询”就是从一个或多个有关系的表中将满足要求的数据提取出来,并把这些数据显示在新的查询数据表中。 而其他的方法,像“交叉查询”、“操作查询”和“参数查询”等,都是“选择查询”的扩展,课后的补充内容中会专门讲到。 这次建立查询我们不用向导,而是直接用“查询设计视图”来建立新的查询。 直接使用查询设计视图建立查询可以帮助你理解数据库中表之间的关系,让你看到要查询的字段之间是如何联系的。 这些对建立一个优秀的数据库非常有帮助。 其实查询向导的使用和表向导基本一样,也非常简单。 现在我们建立一个“订单”查询,建立这个查询就是为了将每份订单中的各项信息都显示出来,包括“订单号”、“订货公司”、“货品名称”、“货物单价”、“订货数量”、“订货金额”、“经办人”和“订货时间”这些字段。 首先要在Access中打开“客户订单数据库”,然后单击“对象”列表中的“查询”项,并在创建方法列表中单击“在设计视图中创建查询”项。 因为下面的操作都是在对“查询”这个对象进行操作,所以要将当前的对象切换到“查询”对象上。 在第二课和第四课中讲过,执行任何操作都必须先选择这个操作所针对的对象 单击“在设计视图中创建查询”后,屏幕上出现“查询”窗口,它的上面还有一个“显示表”对话框。 在上一课“建立表之间的关系”中曾经提到过“显示表”对话框。 单击“显示表”对话框上的“两者都有”选项,在列表框中选择需要的表或查询。 “表”选项卡中只列出了所有的表,“查询”选项卡中只列出了所有的查询,而选择“两者都有”就可以把数据库中所有“表”和“查询”对象都显示出来,这样有助于我们从选择的表或查询中选取新建查询的字段。 单击所需要的表或查询,然后单击对话框上的“添加”按钮,这个表的字段列表就会出现在查询窗口中。 将“客户订单数据库”中的“订单信息表”和“产品信息表”都添加到查询窗口中。 添加完提供原始数据的表后,就可以把“显示表”窗口关闭,回到“查询窗口”中准备建立“查询”了。
4、空间数据库中,矢量数据的管理方式有哪些,各有什么优缺点?
1、文件-关系数据库混合管理方式不足:①属性数据和图形数据通过ID联系起来,使查询运算,模型操作运算速度慢;② 数据分布和共享困难;③属性数据和图形数据分开存储,数据的安全性、一致性、完整性、并发控制以及数据损坏后的恢复方面缺少基本的功能;④缺乏表示空间对象及其关系的能力。 因此,目前空间数据管理正在逐步走出文件管理模式。 2、全关系数据库管理方式对于变长结构的空间几何数据,一般采用两种方法处理。 ⑴ 按照关系数据库组织数据的基本准则,对变长的几何数据进行关系范式分解,分解成定长记录的数据表进行存储。 然而,根据关系模型的分解与连接原则,在处理一个空间对象时,如面对象时,需要进行大量的连接操作,非常费时,并影响效率。 ⑵ 将图形数据的变长部分处理成Binary二进制Block块字段。 3、对象-关系数据库管理方式由于直接采用通用的关系数据库管理系统的效率不高,而非结构化的空间数据又十分重要,所以许多数据库管理系统的软件商在关系数据库管理系统中进行扩展,使之能直接存储和管理非结构化的空间数据。 这种扩展的空间对象管理模块主要解决了空间数据的变长记录的管理,由数据库软件商进行扩展,效率要比前面所述的二进制块的管理高得多。 但是它仍然没有解决对象的嵌套问题,空间数据结构也不能内用户任意定义,使用上仍受到一定限制。 矢量图形数据与属性数据的管理问题已基本得到解决。 从概念上说,空间数据还应包括数字高程模型、影像数据及其他专题数据。 虽然利用关系数据库管理系统中的大对象字段可以分块存贮影像和DEM数据,但是对于多尺度DEM数据,影像数据的空间索引、无缝拼接与漫游、多数据源集成等技术还没有一个完整的解决方案。
ORACLE 常用操作语句规范和注意事项
规范: i. 尽量避免大事务操作,慎用holdlock子句,提高系统并发能力。 ii. 尽量避免反复访问同一张或几张表,尤其是数据量较大的表,可以考虑先根据条件提取数据到临时表中,然后再做连接。 iii. 尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该改写;如果使用了游标,就要尽量避免在游标循环中再进行表连接的操作。 iv. 注意where字句写法,必须考虑语句顺序,应该根据索引顺序、范围大小来确定条件子句的前后顺序,尽可能的让字段顺序与索引顺序相一致,范围从大到小。 v. 不要在where子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。 vi. 尽量使用exists代替select count(1)来判断是否存在记录,count函数只有在统计表中所有行数时使用,而且count(1)比count(*)更有效率。 vii. 尽量使用“>=”,不要使用“>”。 viii. 注意一些or子句和union子句之间的替换 ix. 注意表之间连接的数据类型,避免不同类型数据之间的连接。 x. 注意存储过程中参数和数据类型的关系。 xi. 注意insert、update操作的数据量,防止与其他应用冲突。 如果数据量超过200个数据页面(400k),那么系统将会进行锁升级,页级锁会升级成表级锁。 b) 索引的使用规范: i. 索引的创建要与应用结合考虑,建议大的OLTP表不要超过6个索引。 ii. 尽可能的使用索引字段作为查询条件,尤其是聚簇索引,必要时可以通过index index_name来强制指定索引 iii. 避免对大表查询时进行table scan,必要时考虑新建索引。 iv. 在使用索引字段作为条件时,如果该索引是联合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用。 v. 要注意索引的维护,周期性重建索引,重新编译存储过程。 c) tempdb的使用规范: i. 尽量避免使用distinct、order by、group by、having、join、cumpute,因为这些语句会加重tempdb的负担。 ii. 避免频繁创建和删除临时表,减少系统表资源的消耗。 iii. 在新建临时表时,如果一次性插入数据量很大,那么可以使用select into代替create table,避免log,提高速度;如果数据量不大,为了缓和系统表的资源,建议先create table,然后insert。 iv. 如果临时表的数据量较大,需要建立索引,那么应该将创建临时表和建立索引的过程放在单独一个子存储过程中,这样才能保证系统能够很好的使用到该临时表的索引。 v. 如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先truncate table,然后drop table,这样可以避免系统表的较长时间锁定。 vi. 慎用大的临时表与其他大表的连接查询和修改,减低系统表负担,因为这种操作会在一条语句中多次使用tempdb的系统表。 d) 合理的算法使用: 根据上面已提到的SQL优化技术和ASE Tuning手册中的SQL优化内容,结合实际应用,采用多种算法进行比较,以获得消耗资源最少、效率最高的方法。 具体可用ASE调优命令:set statistics io on, set statistics time on , set showplan on 等。











发表评论