
构建Redis集群,缩短响应时间
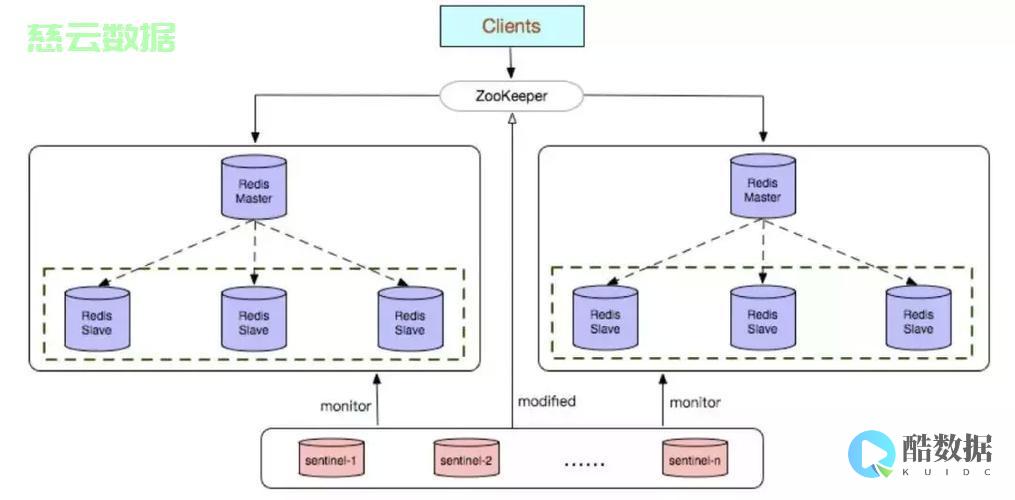
Redis是一个开源的内存数据库,它的特点是高可扩展性、高性能、高可用性,随着越来越多的应用程序把它作为一个数据存储的选择,它的重要性越来越大。然而,Redis对于单台 服务器 的容量和性能都有一定的限制,为了克服这些问题,我们可以构建一个Redis集群,使用多台服务器来提供服务,同时缩短客户端的响应时间。
在构建一个Redis集群之前,首先需要为每个节点配置一些基本的参数,包括端口、IP地址、存储路径、数据库容量等,因为集群的节点数量多,因此每一步的配置都非常重要。将多个Redis实例配置为一个集群并不是一件容易的事情,需要经过几步操作。
通过redis-cli工具将每个Redis实例加入同一个集群,并确认它可以正常工作:

redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 --cluster-replicas 1
通过命令行确保每个节点处于激活状态:
CLUSTER NODES
需要将应用程序的请求转发到Redis集群,这需要在应用程序中添加相应的代码段:
var redis = require('redis'),// create the connectionCluster = require('/quark-cluster');// setup the clientvar client = Cluster.createClient({options: {startActiveNodes: true,nodes: [{host: 'host1', port: 7000},{host: 'host2', port: 7001}]}});
这样,单台服务器将不再是性能和容量的瓶颈,构建Redis集群将能够显著提升Redis性能和可用性,同时缩短客户端的响应时间。
香港服务器首选树叶云,2H2G首月10元开通。树叶云(shuyeidc.com)提供简单好用,价格厚道的香港/美国云服务器和独立服务器。IDC+ISP+ICP资质。ARIN和APNIC会员。成熟技术团队15年行业经验。
如何学习python爬虫
其实网络爬虫就是模拟浏览器获取web页面的内容的过程,然后解析页面获取内容的过程。 首先要熟悉web页面的结构,就是要有前端的基础,不一定要精通,但是一定要了解。 然后熟悉python基础语法,相关库函数(比如beautifulSoup),以及相关框架比如pyspider等。 建议刚开始不要使用框架,自己从零开始写,这样你能理解爬虫整个过程。 推荐书籍:python网络数据采集 这本书,比较基础。
如何入门 Python 爬虫
“入门”是良好的动机,但是可能作用缓慢。 如果你手里或者脑子里有一个项目,那么实践起来你会被目标驱动,而不会像学习模块一样慢慢学习。 另外如果说知识体系里的每一个知识点是图里的点,依赖关系是边的话,那么这个图一定不是一个有向无环图。 因为学习A的经验可以帮助你学习B。 因此,你不需要学习怎么样“入门”,因为这样的“入门”点根本不存在!你需要学习的是怎么样做一个比较大的东西,在这个过程中,你会很快地学会需要学会的东西的。 当然,你可以争论说需要先懂python,不然怎么学会python做爬虫呢?但是事实上,你完全可以在做这个爬虫的过程中学习python :D看到前面很多答案都讲的“术”——用什么软件怎么爬,那我就讲讲“道”和“术”吧——爬虫怎么工作以及怎么在python实现。 先长话短说summarize一下:你需要学习基本的爬虫工作原理基本的http抓取工具,scrapyBloom Filter: Bloom Filters by Example如果需要大规模网页抓取,你需要学习分布式爬虫的概念。 其实没那么玄乎,你只要学会怎样维护一个所有集群机器能够有效分享的分布式队列就好。 最简单的实现是python-rq:和Scrapy的结合:darkrho/scrapy-redis · GitHub后续处理,网页析取(grangier/python-goose · GitHub),存储(Mongodb)
大数据学习一般要多少学费
4-6个月左右,包含java和大数据的学-习,如下:基础阶段:linux、Docker、kvm、mysql基础、oracle基础、mongodb、redis。 hADOop mapreduce hdfs yarn:hadoop:hadoop 概念、版本、历史,hdfs工作原理,yarn介绍及组件介绍。 大数据存储阶段:hbase、hive、sqoop。 大数据架构设计阶段:flume分布式、zookeeper、Kafka。 大数据实时计算阶段:mahout、spark、storm。 大数据数据采集阶段:python、scala。 大数据商业实战阶段:实操企业大数据处理业务场景,分析需求、解决方案实施,综合技术实战应用。 大数据分析的几个方面:1、可视化分析:可视化分析能够直观的呈现大数据特点,同时能够非常容易被读者所接受,就如同看图说话一样简单明了。 2、数据挖掘算法:大数据分析的理论核心就是数据挖掘算法。 3、预测性分析:从大数据中挖掘出特点,通过科学的建立模型,从而预测未来的数据。 4、语义引擎:需要设计到有足够的人工智能以足以从数据中主动地提取信息。 5、数据质量和数据管理:能够保证分析结果的真实性











发表评论