
随着数码化时代的到来,人们对数据存储和分析的需求越来越高。而Hadoop生态系统(Hadoop Distributed File System)提供了一个可扩展且能够处理海量数据的方法,它不仅支持常见的数据格式,如文本和XML,还能支持任何格式的数据,包括关系型数据库。
MySQL是一种非常流行的关系型数据库,使用广泛。但是对于需要在HDFS上处理的大数据来说,将MySQL数据转换为HDFS格式是很必要的。在这篇文章中,我们将探讨如何将MySQL数据导入到HDFS中,并分享一些技巧和方法,以实现快速高效的数据导入操作。
1. 数据库与Hadoop集群的连接
在将MySQL数据导入到HDFS之前,我们需要确保已经创建Hadoop集群,并建立与MySQL数据库的连接。需要在Hadoop集群上安装Sqoop,它是一个用于将关系型数据库导入Hadoop的工具。我们需要确保Sqoop的参数正确,并使用正确的JDBC驱动程序来连接MySQL数据库。
2. 创建和配置HDFS目录
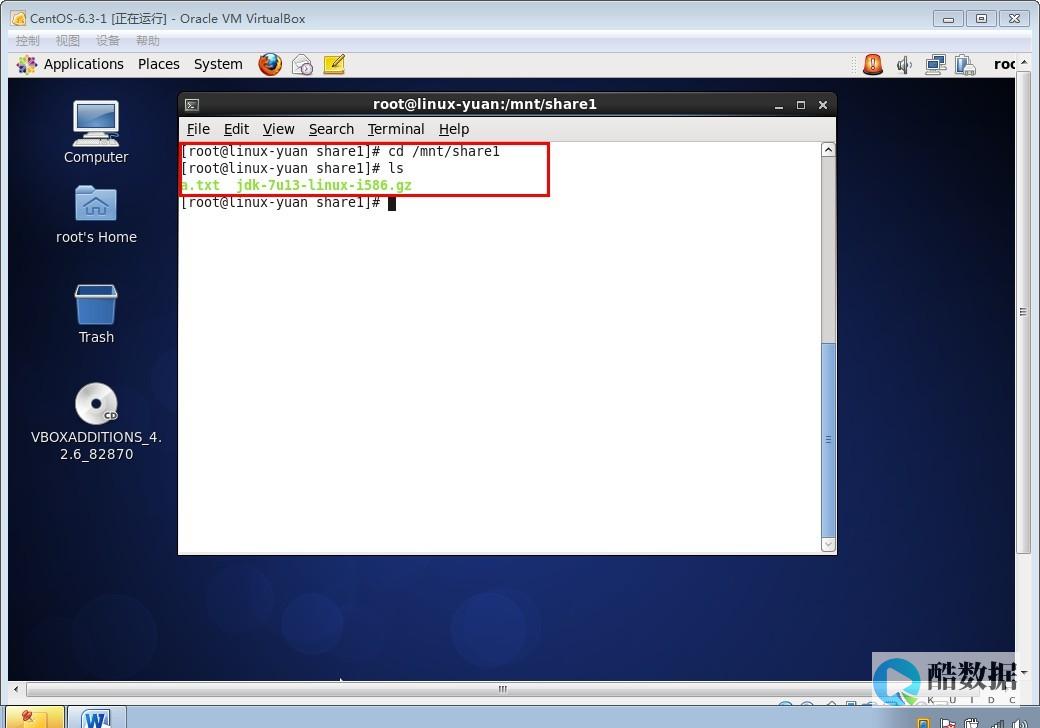
Sqoop可以导入数据到HDFS中的任何目录,但在操作之前,我们需要先创建并配置HDFS目录。我们需要将HDFS系统目录的所有权和权限更改为可写入状态。然后,通过在HDFS中创建一个新目录,用于存储导入的数据。
3. 定义导入的数据
当我们连接了MySQL数据库并准备好了目录后,就可以开始定义需要导入的数据了。Sqoop提供了多种选项,如导入表、结果集或自定义查询等。我们需要考虑数据的大小和类型,以确定何时使用每个选项。
4. 使用Sqoop进行数据导入
当我们已经定义好了导入的数据之后,就可以使用Sqoop工具进行数据导入了。在Sqoop命令中,我们需要指定导入数据的来源(这里是MySQL数据库),以及导入到HDFS的目标路径和Hadoop集群的连接信息。Sqoop可以自动将MySQL数据从表或查询结果集中导入到指定的HDFS目录中。在导入过程中,Sqoop会将数据分区为Hadoop集群中的多个部分,并将其保存在多个HDFS文件中。
5. 使用Sqoop的导入选项
Sqoop还提供了多个有用的导入选项,可以提高导入数据的效率和性能。其中一些选项是:
a. 并行导入:Sqoop提供并行导入功能,可以在单个任务中同时处理多个数据记录。这可以提高导入数据的速度。
b. 压缩:Sqoop支持数据压缩,可以在导入过程中压缩数据文件。
c. 数据库连接管理:Sqoop可以管理多个数据库连接,可以更方便地管理任务和数据源。
d. 导入过滤:Sqoop可以使用过滤器来选择需要导入的数据记录,而不是整个表或结果集。
关系型数据库和Hadoop是大数据处理中最常见的技术,将它们结合起来可以实现更高效和更强大的数据处理能力。通过使用Sqoop工具,我们可以轻松地将MySQL数据导入到HDFS中,并在Hadoop集群中进行处理。在实现这一过程时,我们应该重视数据定义、配置和导入选项的选择,以便实现更佳性能和效率。
相关问题拓展阅读:
大数据行业有哪些工作机会,招聘的岗位技能有哪些
随着大数据时代的到来,在大数据观念不断提出的今天,加强数据大数据挖掘及时的应用已成为大势所趋。大数据分析处理是对纷繁复杂的海量数据价值的提炼,而其中最有价值的地方在于预测性分析,即可以通过数据可视化、统计模式识别、数据描述等数据挖掘形式帮助数据科学家更好的理解数据,根据数据挖掘的结果得出预测性决策。其中主要工作环节参见《大数据分析流程是什么》。这些工作环节都需要什么技术?今天AAA教育小编姐姐简单分析一下大数据分析技术:简敏毁
一、大数据流程图
二、大数据各个环节主要技术
2.1、数据处理主要技术
Sqoop:(发音:skup)作为一款开源的离线数据传输工具,主要用于Hadoop(Hive) 与传统数据库(MySql,PostgreSQL)间的数据传递。它可以将一个关系数据库中数据导入Hadoop的HDFS中,也可以将HDFS中的数据导入关系型数据库中。
Flume:实时数据采集的一个开源框架,它是Cloudera提供的一个高可用用的、高可靠、分布式的海量日志采集、聚合和传输的系统。目前已经是Apache的顶级子项目。使用Flume可以收集诸如日志、时间等数据并将这些数据集中存储起来供下游使用(尤其是数据流框架,例如Storm)。和Flume类似的另一个框架是Scribe(FaceBook开源的日志收集系统,它为日志的分布式收集、统一处理提供一个可扩展的、高容错的简单方案)
Kafka:通常来说Flume采集数据的速度和下游处理的速度通常不同步,因此实时平台架构都会用一个消息中间件来缓冲,而这方面最为流行和应用最为广泛的无疑是Kafka。它是由LinkedIn开发的一个分布式消息系统,以其可以水平扩展和高吞吐率而被广泛使用。目前主流的开源分布式处理系统(如Storm和Spark等)都支持与Kafka 集成。
Kafka是一个基于分布式的消息发布-订阅系统,特点是速度快、可扩展且持久。与其他消息发布-订阅系统类似,Kafka可在主题中保存消息的信息。生产者向主题写入数据,消费者从主题中读取数据。

作为一个分布式的、分区的、低延迟的、冗余的日志提交服务。和Kafka类似消息中间件开源产品还包括RabbiMQ、ActiveMQ、ZeroMQ等。
MapReduce:MapReduce是Google公司的核心计算模型,它将运行于大规模集群上的复杂并行计算过程高度抽象为两个函数:map和reduce。MapReduce最伟大之处在于其将处理大数据的能力赋予了普通开发人员,以至于普通开发人员即使不会任何的分布式编程知识,也能将自己的程序运行在分布式系统上处理海量数据。
Hive:MapReduce将处理大数据的能力赋予了普通开发人员,而Hive进一步将处理和分析大数据的能力赋予了实际的数据使用人员(数据开发工程师、数据分析师、算法工程师、和业务分析人员)。
Hive是由Facebook开发并贡献给Hadoop开源社区的,是一个建立在Hadoop体系结构上的一层SQL抽象。Hive提供了一些对Hadoop文件中数据集进行处理、查询、分析的工具。它支持类似于传统RDBMS的SQL语言的查询语言,一帮助那些熟悉SQL的用户处理和查询Hodoop在的数据,该查询语言称为Hive SQL。Hive SQL实际上先被SQL解析器解析,然后被Hive框架解析成一个MapReduce可执行计划,并按照该计划生产MapReduce任务后交给Hadoop集群处理。
Spark:尽管MapReduce和Hive能完成海量数据的大多数批处理工作,并且在打数据时代称为企业大数据处理的首选技术,但是其数据查询的延迟一直被诟病,而且也非常不适合迭代计算和DAG(有限无环图)计算。由于Spark具有可伸缩、拿蔽基于内存计算能特点,且拦备可以直接读写Hadoop上任何格式的数据,较好地满足了数据即时查询和迭代分析的需求,因此变得越来越流行。
Spark是UC Berkeley AMP Lab(加州大学伯克利分校的 AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,它拥有Hadoop MapReduce所具有的优点,但不同MapReduce的是,Job中间输出结果可以保存在内存中,从而不需要再读写HDFS ,因此能更好适用于数据挖掘和机器学习等需要迭代的MapReduce算法。
Spark也提供类Live的SQL接口,即Spark SQL,来方便数据人员处理和分析数据。
Spark还有用于处理实时数据的流计算框架Spark Streaming,其基本原理是将实时流数据分成小的时间片段(秒或几百毫秒),以类似Spark离线批处理的方式来处理这小部分数据。
Storm:MapReduce、Hive和Spark是离线和准实时数据处理的主要工具,而Storm是实时处理数据的。
Storm是Twitter开源的一个类似于Hadoop的实时数据处理框架。Storm对于实时计算的意义相当于Hadoop对于批处理的意义。Hadoop提供了Map和Reduce原语,使对数据进行批处理变得非常简单和优美。同样,Storm也对数据的实时计算提供了简单的Spout和Bolt原语。Storm集群表面上和Hadoop集群非常像,但是在Hadoop上面运行的是MapReduce的Job,而在Storm上面运行的是Topology(拓扑)。
Storm拓扑任务和Hadoop MapReduce任务一个非常关键的区别在于:1个MapReduce Job最终会结束,而一个Topology永远运行(除非显示的杀掉它),所以实际上Storm等实时任务的资源使用相比离线MapReduce任务等要大很多,因为离线任务运行完就释放掉所使用的计算、内存等资源,而Storm等实时任务必须一直占有直到被显式的杀掉。Storm具有低延迟、分布式、可扩展、高容错等特性,可以保证消息不丢失,目前Storm, 类Storm或基于Storm抽象的框架技术是实时处理、流处理领域主要采用的技术。
Flink:在数据处理领域,批处理任务和实时流计算任务一般被认为是两种不同的任务,一个数据项目一般会被设计为只能处理其中一种任务,例如Storm只支持流处理任务,而MapReduce, Hive只支持批处理任务。
Apache Flink是一个同时面向分布式实时流处理和批量数据处理的开源数据平台,它能基于同一个Flink运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能。Flink在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来。Flink完全支持流处理,批处理被作为一种特殊的流处理,只是它的数据流被定义为有界的而已。基于同一个Flink运行时,Flink分别提供了流处理和批处理api,而这两种API也是实现上层面向流处理、批处理类型应用框架的基础。
Beam:Google开源的Beam在Flink基础上更进了一步,不但希望统一批处理和流处理,而且希望统一大数据处理范式和标准。Apache Beam项目重点在于数据处理的的编程范式和接口定义,并不涉及具体执行引擎的实现。Apache Beam希望基于Beam开发的数据处理程序可以执行在任意的分布式计算引擎上。
Apache Beam主要由Beam SDK和Beam Runner组成,Beam SDK定义了开发分布式数据处理任务业务逻辑的API接口,生成的分布式数据处理任务Pipeline交给具体的Beam Runner执行引擎。Apache Flink目前支持的API是由Java语言实现的,它支持的底层执行引擎包括Apache Flink、Apache Spark和Google Cloud Flatform。
2.2、数据存储主要技术
HDFS:Hadoop Distributed File System,简称FDFS,是一个分布式文件系统。它有一定高度的容错性和高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS提供了一个高容错性和高吞吐量的海量数据存储解决方案。
在Hadoop的整个架构中,HDFS在MapReduce任务处理过程在中提供了对文件操作的和存储的的支持,MapReduce在HDFS基础上实现了任务的分发、跟踪和执行等工作,并收集结果,两者相互作用,共同完成了Hadoop分布式集群的主要任务。
HBase:HBase是一种构建在HDFS之上的分布式、面向列族的存储系统。在需要实时读写并随机访问超大规模数据集等场景下,HBase目前是市场上主流的技术选择。
HBase解决了传递数据库的单点性能极限。实际上,传统的数据库解决方案,尤其是关系型数据库也可以通过复制和分区的方法来提高单点性能极限,但这些都是后知后觉的,安装和维护都非常复杂。而HBase从另一个角度处理伸缩性的问题,即通过线性方式从下到上增加节点来进行扩展。HBase 不是关系型数据库,也不支持SQL,它的特性如下:
1、大:一个表可以有上亿上,上百万列。
2、面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
3、稀疏:为空(null)的列不占用存储空间,因此表可以设计的非常稀疏。
4、无模式::每一行都有一个可以排序的主键和任意多的列。列可以根据需求动态增加,同一张表中不同的行可以有截然不同的列。
5、数据多版本:每个单元的数据可以有多个版本,默认情况下,版本号字段分开,它是单元格插入时的时间戳。
6、数据类型单一:HBase中数据都是字符串,没有类型。
2.3、数据应用主要技术
数据有很多应用方式,如固定报表、即时分析、数据服务、数据分析、数据挖掘和机器学习等。下面说下即时分析Drill框架、数据分析R语言、机器学习TensorFlow框架。
Drill:Apache Drill是一个开源实时大数据分布式查询引擎,目前已成为Apache的顶级项目。Drill开源版本的Google Dremel。Dremel是Google的“交互式”数据分析系统,可以组建成规模上千的集群,处理PB级别的数据。
MapReduce处理数据一般在分钟甚至小时级别,而Dremel将处理时间缩短至秒级,即Drill是对MapReduce的有力补充。Drill兼容ANSI SQL语法作为接口,支持本地文件、HDFS、Hive、HBase、MongoDb作为存储的数据查询。文件格式支持Parquet、CSV、TSV以及Json这种无模式(schema-free)数据。所有这些数据都像传统数据库的表查询一样进行快速实时查询。
R语言:R是一种开源的数据分析解决方案。R流行原因如下:
1、R是自由软件:完全免费、开源。可在官方网站及其镜像中下载任何有关的安装程序、源代码、程序包及其源代码、文档资料,标准的安装文件自身就带有许多模块和内嵌统计函数,安装好后可以直接实现许多常用的统计功能。
2、R是一种可编程的语言:作为一个开放的统计编程环境,R语言的语法通俗易懂,而且目前大多数新的统计方法和技术都可以在R中找到。
3、R具有很强的互动性:除了图形输出在另外的窗口,它的熟入输出都是在一个窗口进行的,输入语法中如果有错马上会在窗口中给出提示,对以前输入过的命令有记忆功能,可以随时再现、编辑、修改以满足用户的需要,输出的图形可以直接保存为JPG、BMP、PNG等图片格式,还可以直接保存为pdf文件。此外,R语言和其它编程语言和数据库直接有很好的接口。
TensorFlow:TensorFlow是一个非常灵活的框架,它能够运行在个人电脑或 服务器 的单个/多个cpu和GPU上,甚至是移动设备上,它最早是为了研究机器学习和深度神经网络而开发的,后来因为通用而开源。
TensorFlow是基于数据流图的处理框架,TensorFlow节点表示数学运算,边表示运算节点之间的数据交互。TensorFlow从字母意义上来讲有两层含义:一是Tensor代表的是节点之间传递的数据,通常这个数据是一个多维度矩阵(multidimensional>香港服务器首选树叶云,2H2G首月10元开通。树叶云(www.IDC.Net)提供简单好用,价格厚道的香港/美国云服务器和独立服务器。IDC+ISP+ICP资质。ARIN和APNIC会员。成熟技术团队15年行业经验。
如何制作洗发水营销渠道策略
作为快速流通消费品,洗发水几乎可以在所有的渠道都可以进行销售,如商场、超市、日杂店、浴池、发廊、宾馆等,在洗发水购买的渠道中,依次为:超市、便利店所占比重近40%,特大仓储型超市所占比重超过20%,公费发送、赠送、派送产品占将近20%。 对于厂商来说,通常采用的是经销模式,利用传统的商业流通渠道,通过一级批发、二级批发等层层渗透到各级零售终端,再达到消费者的手中。 近两年,出现了一些精品日化店、网络、团购等新的渠道形式,并且销量占比在迅速提升
如何制作香水
香精提取方法有五种:萃取法、水蒸气蒸馏法、榨压法、吸附法和气相层析与光谱分析法。 一、萃取法1、萃取法原理 萃取法是一个物理过程,其难点是要选择适用的、有挥发性的溶剂直接浸泡香料植物,通过溶液与固体香料接触,经过渗透、溶解、分配、扩散等一系列物理过程,将原料中的香成分提取出来。 该方法的优点是能并能将低沸点、高沸点组分都提取出来,非常神奇地利用物理方式,很好地保留植物香料中的原有香气,将植物香料制成香料产品。 2、工艺过程 这是一个液-固过程:植物香精 + 萃取液->渗透 + 溶解 + 分配->渗提液->渗膏;渗膏 + 乙醇->净油二、水蒸气蒸馏法1、水蒸气蒸馏法原理 香料与水构成精油与水的互不相溶体系,加热时,随着温度的增高,精油和水均要加快蒸发,产生混合体蒸气,其蒸气经锅顶鹅颈导入冷凝器中得到水与精油的液体混合物,经过油水分离后即可得到精油产品。 2、 蒸馏方式 水中蒸馏 :原料置于筛板或直接放入蒸馏锅,锅内加水浸过料层,锅底进行加热。 水上蒸馏:(隔水蒸馏)原料置于筛板,锅内加入水量要满足蒸馏要求,但水面不得高于筛板,并能保证水沸腾至蒸发时不溅湿料层,一般采用回流水,保持锅内水量恒定以满足蒸气操作所需的足够饱和整齐,因此可在锅底安装窥镜,观察水面高度。 直接蒸气蒸馏:在筛板下安装一条带孔环行管,由外来蒸气通过小孔直接喷出,进入筛孔对原料进行加热,但水散作用不充分,应预先在锅外进行水散,锅内蒸馏快且易于改为加压蒸馏。 水扩散蒸气蒸馏:这是近年国外应用的一种新颖的蒸馏技术。 水蒸气由锅顶进入,蒸气至上而下逐渐向料层渗透,同时将料层内的空气推出,其水散和传质出的精油无须全部气化即可进入锅底冷凝器。 蒸气为渗滤型,蒸馏均匀、一致、完全,而且水油冷凝液较快进入冷凝器,因此所得精油质量较好、得率较高、能耗较低、蒸馏时间短、设备简单。 3、水蒸气蒸馏工艺过程 植物原料三、榨磨法1、榨磨法的原理 主要是指柑桔类果实或果皮通过磨皮或压榨来提取精油的一种方法。 2、榨磨法的方式:冷磨和冷榨两种方式。 3、榨磨法工艺过程 冷磨法适宜于从整果取油。 调香常识 好香水,需要您用一生的时间去体会其香味创造出的艺术与科学。 各种可能性无穷无尽,新的发明层出不穷。 理解香水的味道,需知其单一和混合的香味是如何制出的。 制造香水,是一种艺术;如其它艺术一样,香水的艺术成果历经了几个主观和情感的层次。 当各种香精混合在一起时,神奇的事情随之发生。 各种原料互相影响,有的原料本身没有,或只有轻微气味,但它们经常充当其它原料的催化剂,从而改变了原有的特点。 仅仅闻闻某种特定香水的一种配料,你还无法猜想出各种配料相混合的味道。 这,就是香水的神秘性和奇特性的一部分。 调香是调香术的简称,指调配香精的技术和艺术。 是将选定的香精按拟定的香型、香气,运用调香技艺,调制出人们喜好的、和谐的、极富浪漫色彩和幻想的香精。 调香师要具有丰富的香料、香精知识、灵敏的辨香嗅觉、良好的艺术修养、丰富的想象能力及扎实的香精配备理论基础和合成工艺技术。 香精调配需要经过三个阶段:处方试验、试样试验、大样调配和加香实验。 形成过程:小样试配-->按工艺加入加香媒介-->将小样放大。 形成阶段:处方试验-->试样试验-->大样调配和加香实验。 目 的:头香、体香、基香-->香气通过定香剂的作用-->按工业化生产检验香精实际效果,满足人们的使用要求。 头香、体香、基香要连贯,香气和谐、优雅、扩散性好,香气通过定香剂的作用使香气长久保持原来香型及香气特征。 制作过程现在,大多数专业的调香师都是在专业学院中学习过香水制作艺术的。 比如著名的设在法国格拉斯(Grasse)的纪芳丹.若勒香水学校(Givaudan-Roure)。 那里设置了一系列的课程,包括现场的实验和在企业做一段时间的实习学徒,学习时间需要6年。 制造新型香水是调香师的最高艺术,但是他们还有更实际的责任。 比如当某种原料用完的时候,使用代用品重新配比以保持香水长久的销势。 调香师也必须使新的成分和原来的成分混合无间,这样就不会受植物减产和原料缺乏的威胁。 整个香水工业对味道强烈的香油持一种谨慎的态度,香水的成分必须符合国际通用的环保和健康方面的标准,很多原料,包括一些化合物,在没有做化学方面的限制之前,都不能使用。 有些还要用其它的代用品,因为在那些原料中发现了有毒的迹象。 很多调香师都在从事这一类的工作,或者为香皂、浴液、空气清新剂中的香味剂提出专业化的建议,这些工作往往更加繁重,比调制迪奥之魔(Diorissimos)和光阴的味道(Lair duTemps)这样的新品香水的任务要繁忙得多。 在国际市场上,推出一款新香水是一种困难重重的商业行为,一般需要有细致的市场调研和坚实的财力支持做后盾。 因此,调香师在研制一款新香水之初,就须考虑香水的类型和价格。 当然,也有可能在调香师介入此事之前香水的类型和价格就已经决定了。 销售价格必须确定,广告和市场推广的费用也必须确定,代表香水类型的形象要得到一致的认可,最要紧的是还须设计一个合适的瓶子。 令人惊奇的是,整个计划的激活往往是从香水的名字开始的。 当前,几乎所有的调香师都为一到两个大型的香水制造企业服务,那些有自己的制造和销售网络的人除外,比如尼古拉(Nicolai)和伊莎贝尔(Isabell)。 只有几个超级香水企业比如娇兰(Guerlain)、夏奈尔和巴铎(Patou)等有自己的调香师,而且他们一般都不会改变自己的从属关系。 当然也有例外,比如调制过洛卡斯女士(Madame Rochas)和古驰一号 (Gucci No.1)的纪.罗伯特(Guy Tobert)。 随着对香水要求的明朗化,制造公司有时是不止一个公司就开始进行流程化的处理,诸如提供样品,讨论变化方案,直到最后敲定并选择一位调香师来具体负责调制工作,等等。 调香师的“鼻子”: 由于香水业需要极敏锐的嗅觉,所以,有时候人们称调香师为“鼻子”.调香师让自己的鼻子进入状态,面前的桌子上满是装着精华油和化学合成物的瓶子。 他要在其中挑选可以架构新香水的原料。 也许要花好几年的时间来体验数百种香味,从而得到一个配方。 一种香味可能对另一种香味构成影响,怎样使某一种香味变得明显,或者保证一种原料不要盖过另一种的效果。 最终产品可能隐含了香水师自己惯有的风格-比如特别喜欢用某种成分,或者偏爱某种配方的比例,因此往往会有招牌式的痕迹。 但是压倒一切的准则是要符合客户提出的要求,而这些要求有时是相当难以满足的。 这方面的故事有很多。 例如美国的一个性格古怪的百万富翁要求欧内斯特.达尔多夫(Ernest Daltroff)调制一种香水,能让人联想到在香槟酒里沐浴,令欧内斯特啼笑皆非。 现在这种香水在市场上还有卖,并且在某种宗教仪式中派上了用场。 当佛敏尼斯公司(Firmenich)的雅克.卡佛里尔(Jacque Cavallier)接到三宅一生第一款香水的定单时,客户要求是香水的气息要像新鲜的水一样清新。 虽然香水师对能否满足这一要求并没有足够的自信,但是一生之水后来确实成了最畅销的香水。 快速地调制出香水是不可能的,只要嗅几次,鼻子就迟钝了。 所以在一种香味和另一种香味之间,可能要经过几小时甚至几天的时间间隔,才能再次测试。 测试香味的留存能力要用到科学的分析法,客户有时会自己组织测试小组复核,或者做进一步的检测。 这样,推出一款香水,把它送进市场的过程也许要持续数年,可不是一蹴而就的事情。 不过现在也很少有考迪的吸引(Laimant)香水那样拖沓的例子了。 那款香水为了力求完美,花了整整5年的工夫。 不过还有更过分的,娇兰推出爱之歌(Chant dAromes)竟然准备了7年的时间。 香水的成份: 专业的调香师会对香水这种混合液体的配比极尽精细之能事。 大多数香水包括50~100种成分,有的还会更多,200种也很常见。 乔治欧.比弗利山(Giorgio Beverly Hills)的翼(Wing)牌香水就号称有621种成分。 另一款红(Red)则有近700种。 这些成分中,最主要的部分是化学合成物。 有些可能会来自植物,而更多的来自焦油,凡士林和其它更匪夷所思的材料。 每种成分的用量必须得到精密的控制,在科技高度发展的现代,计算机等新技术被运用来精确地控制和存储香水原料。 这些技术为大工业生产提供了很好的前期准备工作。 香水制造步骤:制造香水的第一步是要准备很多种类各异的精华油,有些品种可以用较长的时间提炼,有的却要在极短的时间里完成。 比如生长在东南亚的香油树花就必须在特定的时间内采摘并立即着手萃取。 因此萃取的设备就设在香油树的周围,蒸馏后的产品立刻被存储进大缸。 香水师在现场得到萃取物或者向当地的批发商和其它二手公司购买原料。 下一步,根据那些鼻子提供的配方,将所有用到的成分混合到一起,这需要花几个星期的时间。 再用酒精稀释那些混合物,达到预先设计的浓度。 最后储存在一个铜制的容器里,使其香味更加醇厚。 然后才是装瓶和等待面世的最后环节。 制香业现在是大规模生产的行业,香料不仅用在香水上,而且扩展到包括洗浴用品的家居用品上,还被广泛运用在调味料上。 香味扑鼻的菜肴显然会刺激食欲,而香味剂的原料可能正是香水用的原料。 有很多大公司在全球很多国家都有分支机构。 他们销售香水和食用香味剂,与较小一点的公司一起,给大多数调香师提供了就业机会。 但是还有一些调香师是游离于主流的香水工业之外的。 他们用少量的工人以传统的方法制作香水,并且在自己的铺子里销售,产品还包括其它一些品种的东西。 从他们那里可以得到相当珍贵的产品:用龙涎香和沉香木制作的香水;为少数人的口味特别调制的香水和一些有特殊效果的香水;还有为鉴赏家们特制的香水。 其中如贵德香水公司(Perfumers Guild)的约翰.柏里(John Bailey)就曾为英国作家巴巴拉.卡特兰德(Barbara Cartland)度身定制了浪漫之香(Scent of Romance)。 这一类的香水绝大多数依赖于天然原料。 从店堂的环境和氛围上看,非常接近娇兰早期推出的第一款香水的格调,那是为了某一次晚会而推出香水。 香水的调制由此升华到一种艺术境界。
要当Java工程师,需要掌握什么技能?
Java工程师需要掌握的技能还是比较多的。 技能傍身才能较好的应对工作,而且不同的Java开发岗位对于面试者的需求也是不一样的。
相关技能可以参考如下:
第一阶段,Java核心基础:
1.深入理解Java面向对象思想
2.掌握开发中常用基础API
3.熟练使用集合框架、IO流、异常
4.能够基于JDK8开发
第二阶段,数据库关键技术
1.掌握最流行关系型数据MySQL常见操作
2.熟练增删改查数据处理
3.掌握Java JDBC、连接池操作
第三阶段,Web网页技术
1.掌握基本的JavaWeb基础知识JSP/Servlet/jQuery等
2.具备基本的B/S结构软件开发能力
3.可以动手开发一个B/S架构的Web项目
第四阶段,开发必备框架&技术
1.掌握SSM框架技术
2.掌握使用Maven进行模块的开发
3.熟悉基本的Linux命令以及Linux服务器的使用
4.掌握高级缓存技术Redis的原理,并熟练使用
第五阶段,互联网高级技术
分布式管理系统、Keepalived+Nginx主备、微服务架构技术、消息中间件技术、MySQL调优、高并发技术、性能优化、内存和GC等
第六阶段,前沿技术&大型企业级项目
edis的原理,并熟练使用











发表评论