
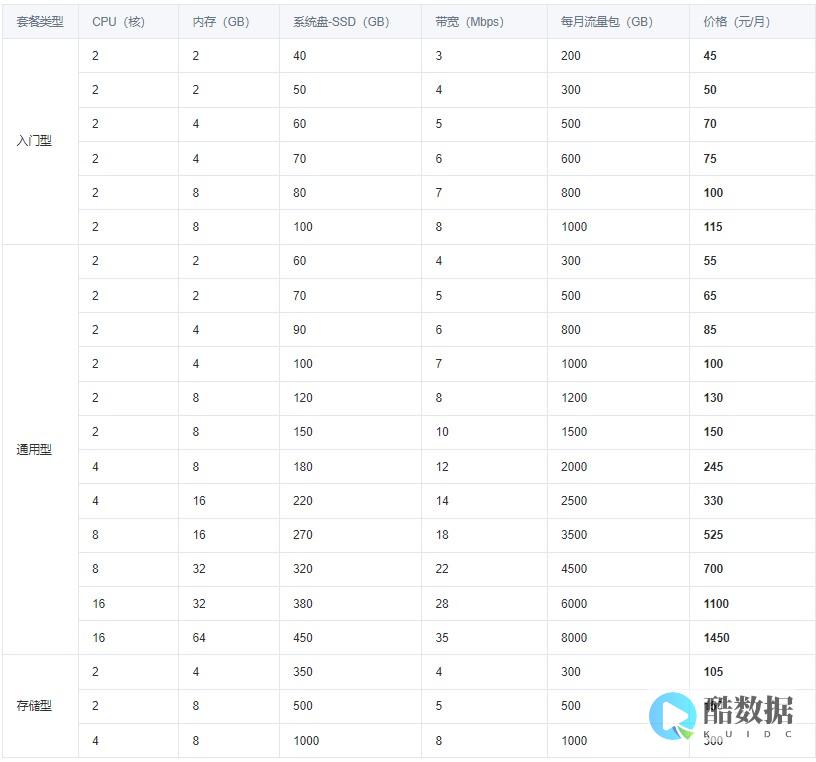
一、场景
这一段时间使用Sql Server 2005 对几个系统进行表分区,这几个系统都有一些特点,比如数据库某张表持续增长,给数据库带来了很大的压力。
现在假如提供一台新的 服务器 ,那么我们应该如何规划这个数据库呢?应该如何进行最小宕机时间的数据库转移呢?如果规划数据库呢?
二、环境准备
要搭建一个好的系统,首先要从硬件和操作系统出发,好的设置和好的规划是高性能的前提,下面我就来说说自己的一些看法,欢迎大家提出异议;
1) 对磁盘做RAID0(比如3*300G),必要时可以考虑RAID5、RAID10;
2) 使用两张千兆网卡,一张用于外网,一张用于内网(这也需要千兆路由器的配合);
3) 逻辑分区C为系统分区(50G),逻辑分区D为程序安装分区(50G),逻辑分区E为数据库文件逻辑分区;
4) 安装Microsoft Windows Server 2003, Enterprise Edition SP2(x64)操作系统;
5) D盘格式化的时候使用默认分配单元大小,E盘格式为64k分配单元;
6) 安装Microsoft SQL Server 2005(x64)数据库;
7) 在我们网上邻居-本地连接-属性-Microsoft网络的文件和打印机共享-***化网络应用程序数据吞吐量(勾选上);
8) 运行-gpedit.msc-Windows设置-安全设置-本地策略-用户权限分配-内存中锁定页面-设置用户组(比如Administrators);
9) 运行-services.msc,设置启动类型为手动,并且停止除了SQL Server (MSSQLSERVER)之外的SQL Server服务,除非你对某些服务需要启动,比如作业、全文索引;
10) 设置虚拟内存大小,我通常设置为4096MB-8192MB;
三、前期工作
在进行分区之前,我们首先要分析这个表的数据量(行数)有多少?这个表的存储空间(物理存储)有多少?需要确定分区文件多大为合理?还需要确认我们按照表中哪个字段进行分区?后期的维护是否需要对分区进行管理(比如交换分区进行数据归档等)?
假设我们决定以自增ID作为分区字段(其实应该叫分区数值类型),我们就可以使用上面的行数和存储空间来计算我们的分区边界值了,因为我们确认了分区文件的大小。比如我们表A记录为:1.5亿,占用空间为:700G,如果我们可以接受的文件大小为10G(这个要根据如果需要做交换分区和一些存储空间、硬盘等信息确认的),那么我们的分区值可以这样计算:1.5亿/(700G/10G)≈200W,也就是:200W,400W,600W等等;
分区文件在创建的时候就应该初始化为包含分区边界值数据大小,比如上面的分区文件可以设置为10G,这样就不用重新分配空间了。也可以使用定量增长,比如2048MB。
在设置自增ID为分区字段,那么通常我们会让ID成为聚集索引,而且设置填充因子为100%,这样我们的数据页就不会有空白了。
如果后期的维护需要对分区进行管理,比如交换分区进行数据归档,交换分区是需要索引对齐的,而索引对齐有两种:索引对齐;按存储位置对齐的表。
索引对齐:假如你想让数据与索引分开到不同的文件,可以使用两个不同的分区方案,但是使用同一个分区函数,这样就把索引分开了。(如图1)
存储位置对齐:创建非聚集索引的时候设置【数据空间规范】,两个索引对象可以使用相同的分区架构,并且具有相同分区键的所有数据行***将位于同一个文件组中。这就叫存储位置对齐。(数据和索引在同一个文件中)(如图2)
下面提供了创建分区的代码,其中包括模板还有例子(Ext),这里最主要是注意一些命名规范,希望对大家有用:
数据库创建2个文件组,如果你不想用
 作为分区,你可以创建多一个文件组,文件组=分区值个数+1;
作为分区,你可以创建多一个文件组,文件组=分区值个数+1;
数据库创建2个文件,文件数>=文件组数,一个文件不能属于两个不同的分组中,一个分组可以包含多个文件,注意初始化大小(根据需求)和增长大小(百分比和字节数);
数据库创建分区函数,分区值需要根据需求而变化,前面已经做了示范了,这里使用了右分区,关于边界值的理解可以参考: 解惑:对SQL Server分区进行合并(删除)
数据库创建分区方案,因为前面只创建了2个文件组,所以这里使用了 默认的文件组来保存边界值之外的数据,如果你想创建多一个文件组也可以,如下面的Ext1与Ext2;
的表,这个表有3个字段,Id是自增标识,并在Id字段中创建聚集索引,填充因子为100%,使用上面创建的 分区方案,创建有不同的创建方式,如Ext1、Ext2、Ext3;
表创建测试数据,这里我就模拟从一个存在的
表记录所处的分区情况时,可以使用下面的SQL;
其实到这里实例应该结束了吧?在网上看到的所有关于分区的文章中貌似都是在这里结束了,但是还有一点我需要指出:如果创建存储位置对齐的索引呢?也许通过上面的图2你已经了解了什么是存储位置对齐,如果还不清楚可以查看: (),其实很简单,如Ext所示,但是主要是理解它的原理和作用;
还不想结束?呵呵,这个包含性索引的创建就当是买8送1吧;
上面的代码中我们把文件与文件组是一 一对应起来的,如果我们想更小话文件的话,我们可以在文件组下面创建多个文件,并且设置文件的***值( ),这样就会把数据分配到不同的物理文件上,但是有一点需要注意,那就是它是一个个的使用文件的,当一个用完了才会使用下一个的。
日志文件也可以像上面的做法来做,这样收缩日志的时候比较方便?删除日志文件比较方便?
有一点我们可能会混淆,那就是既然可以在一个文件组里面创建多个文件,那么这个跟我们按照Id的自增来分布数据是不是等效的?这是有不同的,因为从创建分区方案的时候我们就发现文件组和分区边界值是对应的,所以一段分区值这些数据是分配到以文件组为单位的存储单元中,并不是文件。
补充一下,那就是在文件组下面创建的文件只能按照设置的***值( )来区分数据,并不能按照值来区分,这也算一个不同点吧。
如果这些表是写的多,读的少:类似记录日志,我们还有一些方案可以进行处理,比如SQL Server 2008的行压缩、页压缩等;比如MySQL的IASM数据引擎;或者是使用MySQL的master/slave负载均衡。
原文链接:
【编辑推荐】
太阳眼镜的销售技巧和成功案例谁懂写?
太阳眼镜的销售技巧和成功案例谁懂写?其实销售技巧是可以通用的,不管什么行业,掌握了核心,就能在任何行业运用自如,下面分享5个非常实用的销售技巧:一:厉兵秣马 兵法说,不打无准备之仗。 做为推销业务员来讲,道理也是一样的。 很多刚出道的推销业务员通常都有一个误区,以为销售就是要能说会道,其实根本就不是那么一回事。 我喜欢到各个卖场去转转:一来调查一下市场,做到心中有数。 现在的顾客总喜欢讹推销业务员,哪里哪里有多么便宜,哪里哪里又打多少折了,如果你不能清楚了解这些情况,面对顾客时将会非常被动。 二来可以学习一下别的推销业务员的技巧,只有博采各家之长,你才能炼就不败金身! 二:关注细节 现在有很多介绍销售技巧的书,里面基本都会讲到推销业务员待客要主动热情。 但在现实中,很多推销业务员不能领会到其中的精髓,以为热情就是要满面笑容,要言语主动。 其实这也是错误的,什么事情都要有个度,过分的热情反而会产生消极的影响。 热情不是简单地通过外部表情就能表达出来的,关键还是要用心去做。 所谓精诚所至,金石为开!随风潜入夜,润物细无声,真正的诚就是想顾客所想,用企业的产品满足他们的需求,使他们得到利益。 三:借力打力 销售就是一个整合资源的过程,如何合理利用各种资源,对销售业绩的帮助不可小视。 作为站在销售第一线的推销业务员,这点同样重要。 我们经常在街头碰到骗子实施诈骗,其中一般都有一个角色—就是俗称的托,他的重要作用就是烘托气氛。 当然,我们不能做违法的事,但是,我们是不是可以从中得到些启发呢?我在做促销员的时候,经常使用一个方法,非常有效,那就是和同事一起演双簧。 特别是对一些非常有意向购买的顾客,当我们在价格或者其他什么问题上卡住的时候,我常常会请出店长来帮忙。 一来表明我们确实很重视他,领导都出面了,二来谈判起来比较方便,只要领导再给他一点小实惠,顾客一般都会买单,屡试不爽!当然,如果领导不在,随便一个人也可以临时客串一下领导。 关键是要满足顾客的虚荣心和爱贪小便宜的坏毛病。 四:见好就收 销售最惧的就是拖泥带水,不当机立断。 根据我的经验,在销售现场,顾客逗留的时间在5-7分钟为最佳!有些推销业务员不善于察言观色,在顾客已有购买意愿时不能抓住机会促成销售,仍然在喋喋不休地介绍产品,结果导致了销售的失败。 所以,一定要牢记我们推销业务员的使命,就是促成销售!不管你是介绍产品也好,还是做别的什么努力,最终都为了销售产品。 所以,只要到了销售的边缘,一定要马上调整思路,紧急刹车,尝试缔约。 一旦错失良机,要再度钩起顾客的欲望就比较困难了,这也是刚入门的推销业务员最容易犯的错误。 五:送君一程 销售上有一个说法,开发一个新客户的成本是保持一个老客户成本的27倍!要知道,老客户带来的生意远比你想象中的要多。 认真地帮顾客打好包,再带上一声真诚的告别,如果不是很忙的话,甚至可以把他送到电梯口。 有时候,一些微不足道的举动,会使顾客感动万分! 更多有关房地产销售技巧,可访问“※财智屋※”。 ivlsmqudbcacBCAC
sql server数据库的哪个版本功能最全?
SQL Server 2005相对于SQL Server 2000来说,无论是性能还是功能都有一个相当大的提高,甚至可以用“革命”来形容这一次升级。 SQL Server 2005使 SQL Server 跻身于企业级数据库行列。 在数据高可用性方面,SQL Server 2005为用户提供了数据镜像、复制、故障转移群集、日志传送功能。 本文向读者简单介结SQL Server 2005镜像功能。 一、镜像简介数据库镜像是一个高可用性软件解决方案,为客户端提供小于10秒故障转移。 每个数据库镜像配置均包含一个主体服务器(包含主体数据库)、一个镜像服务器(包含镜像数据库)和一个见证服务器,其中见证服务器是可选的。 主体服务器和镜像服务器要求是独立的服务器实例。 主体服务器和镜像服务器的角色是相对的,可以自动或者手动地将主体服务器设置为镜像服务器,镜像服务器设置为主体服务器。 与主体服务器和镜像服务器不同的是,见证服务器并不能用于数据库。 见证服务器监视主体服务器和镜像服务器,确保在给定的时间内这两个故障转移服务器中有且只有一个作为主体服务器,从而支持自动故障转移。 如果存在见证服务器,同步会话将以“高可用性模式”运行,如果主体服务器出现故障,可以实现故障自动转移。 如果见证服务器不存在,同步会话将以“高级别保护模式”运行,出现故障需要手动故障转移,并且有可能丢失数据。 图1:两台服务器镜像图2:两台服务器镜像,一台见证服务器数据库准备结束,端点创建完成,用户便可以启用数据库镜像。 镜像启动后,每个伙伴都将开始维护所在数据库中有关其数据库,以及另一个伙伴和见证服务器的状态信息。 这些状态信息允许服务器实例维护称为“数据库镜像会话”的当前关系。 在数据库镜像会话过程中,服务器实例将通过彼此定期交换 PING 消息来互相监视。
order by 和union all 如何共存
展开全部这个如果是sqlserver2005以上版本的话,可以在A表处使用row_number()函数创建排序行号然后union all b表的数据,可以用一个较大值充当行号如最后以行号进行排序即可











发表评论