
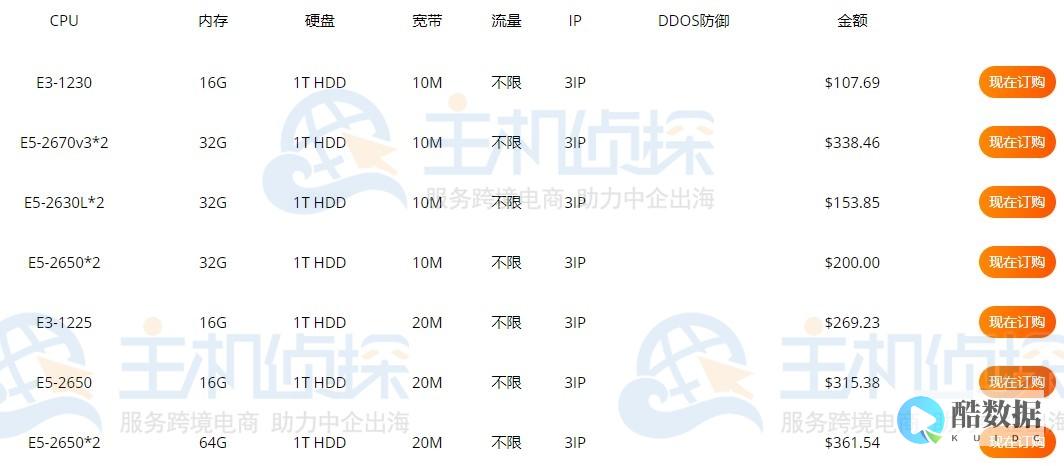
桶的高级配置与对象存储服务API
随着互联网的快速发展,对象存储服务已经成为企业数据存储和管理的首选方案,对象存储服务API提供了丰富的功能,其中设置桶配额(SetBucketQuota)是桶的高级配置之一,本文将详细介绍设置桶配额的相关知识,包括其作用、配置方法以及API调用等。
设置桶配额的作用
设置桶配额是指为特定桶设置存储空间、带宽和请求次数的限制,通过设置桶配额,可以有效地控制桶的使用情况,防止因桶容量过大或请求次数过多而导致的资源浪费或服务不稳定。
设置桶配额的配置方法
通过控制台配置
登录对象存储服务控制台,选择要配置的桶,进入桶的详细页面,在“桶配额”模块中,可以设置存储空间、带宽和请求次数的限制,设置完成后,点击“保存”即可。
通过命令行工具配置
使用对象存储服务的命令行工具(如ossutil)配置桶配额,以下是一个示例命令:
ossutil set-bucket-quota --bucket--storage --bandwidth --request
为桶名,为存储空间配额,为带宽配额,为请求次数配额。
对象存储服务API调用
设置桶配额的API调用路径为:
PUT /?bucketQuota
请求参数
请求示例
{"bucketQuota": {"storageQuota": 10240, // 存储空间配额,单位为MB"bandwidthQuota": 1000, // 带宽配额,单位为MB"requestQuota": 1000 // 请求次数配额}}
响应示例

{"code": 200,"message": "Bucket quota set successfully."}
什么情况下需要设置桶配额?
答:当您需要控制桶的使用情况,防止资源浪费或服务不稳定时,可以设置桶配额。
设置桶配额后,如何修改或删除配额?
答:您可以通过控制台或命令行工具修改或删除桶配额,在控制台中,进入桶的详细页面,找到“桶配额”模块,修改或删除配额后点击“保存”,在命令行工具中,使用
ossutil modify-bucket-quota
或
ossutil delete-bucket-quota
命令进行修改或删除。
java中hashset和hashmap 有什么特点。
HashSet:HashSet实现了Set接口,它不允许集合中有重复的值。 当我们提到HashSet时,第一件事情就是在将对象存储在HashSet之前,要先确保对象重写equals()和hashCode()方法,这样才能比较对象的值是否相等,以确保set中没有储存相等的对象。 public boolean add(Object o)方法用来在Set中添加元素,当元素值重复时则会立即返回false,如果成功添加的话会返回true。 HashMap:HashMap实现了Map接口,Map接口对键值对进行映射。 Map中不允许重复的键。 Map接口有两个基本的实现,HashMap和TreeMap。 TreeMap保存了对象的排列次序,而HashMap则不能。 HashMap允许键和值为null。 HashMap是非synchronized的,但collection框架提供方法能保证HashMap synchronized,这样多个线程同时访问HashMap时,能保证只有一个线程更改Map。 public Object put(Object Key,Object value)方法用来将元素添加到map中。
java中的xml解析
dom是解析xml的底层接口之一(另一种是sax) 而jdom和dom4j则是基于底层api的更高级封装dom是通用的,而jdom和dom4j则是面向java语言的 DOM 是用与平台和语言无关的方式表示 XML 文档的官方 W3C 标准。 DOM 是以层次结构组织的节点或信息片断的集合。 这个层次结构允许开发人员在树中寻找特定信息。 分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作。 由于它是基于信息层次的,因而 DOM 被认为是基于树或基于对象的。 DOM 以及广义的基于树的处理具有几个优点。 首先,由于树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改。 它还可以在任何时候在树中上下导航,而不是像 SAX 那样是一次性的处理。 DOM 使用起来也要简单得多。 XML的四种解析器(dom,sax,jdom,dom4j)原理及性能比较(转自zsq) 1、DOM DOM 是用与平台和语言无关的方式表示 XML 文档的官方 W3C 标准。 DOM 是以层次结构组织的节点或信息片断的集合。 这个层次结构允许开发人员在树中寻找特定信息。 分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作。 由于它是基于信息层次的,因而 DOM 被认为是基于树或基于对象的。 DOM 以及广义的基于树的处理具有几个优点。 首先,由于树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改。 它还可以在任何时候在树中上下导航,而不是像 SAX 那样是一次性的处理。 DOM 使用起来也要简单得多。 另一方面,对于特别大的文档,解析和加载整个文档可能很慢且很耗资源,因此使用其他手段来处理这样的数据会更好。 这些基于事件的模型,比如 SAX。 2、SAX 这种处理的优点非常类似于流媒体的优点。 分析能够立即开始,而不是等待所有的数据被处理。 而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。 这对于大型文档来说是个巨大的优点。 事实上,应用程序甚至不必解析整个文档;它可以在某个条件得到满足时停止解析。 一般来说,SAX 还比它的替代者 DOM 快许多。 3、选择 DOM 还是选择 SAX ? 对于需要自己编写代码来处理 XML 文档的开发人员来说,选择 DOM 还是 SAX 解析模型是一个非常重要的设计决策。 DOM 采用建立树形结构的方式访问 XML 文档,而 SAX 采用的事件模型。 DOM 解析器把 XML 文档转化为一个包含其内容的树,并可以对树进行遍历。 用 DOM 解析模型的优点是编程容易,开发人员只需要调用建树的指令,然后利用navigation APIs访问所需的树节点来完成任务。 可以很容易的添加和修改树中的元素。 然而由于使用 DOM 解析器的时候需要处理整个 XML 文档,所以对性能和内存的要求比较高,尤其是遇到很大的 XML 文件的时候。 由于它的遍历能力,DOM 解析器常用于 XML 文档需要频繁的改变的服务中。 SAX 解析器采用了基于事件的模型,它在解析 XML 文档的时候可以触发一系列的事件,当发现给定的tag的时候,它可以激活一个回调方法,告诉该方法制定的标签已经找到。 SAX 对内存的要求通常会比较低,因为它让开发人员自己来决定所要处理的tag。 特别是当开发人员只需要处理文档中所包含的部分数据时,SAX 这种扩展能力得到了更好的体现。 但用 SAX 解析器的时候编码工作会比较困难,而且很难同时访问同一个文档中的多处不同数据。 4、JDOM JDOM的目的是成为 Java 特定文档模型,它简化与 XML 的交互并且比使用 DOM 实现更快。 由于是第一个 Java 特定模型,JDOM 一直得到大力推广和促进。 正在考虑通过“Java 规范请求 JSR-102”将它最终用作“Java 标准扩展”。 从 2000 年初就已经开始了 JDOM 开发。 JDOM 与 DOM 主要有两方面不同。 首先,JDOM 仅使用具体类而不使用接口。 这在某些方面简化了 API,但是也限制了灵活性。 第二,API 大量使用了 Collections 类,简化了那些已经熟悉这些类的 Java 开发者的使用。 JDOM 文档声明其目的是“使用 20%(或更少)的精力解决 80%(或更多)Java/XML 问题”(根据学习曲线假定为 20%)。 JDOM 对于大多数 Java/XML 应用程序来说当然是有用的,并且大多数开发者发现 API 比 DOM 容易理解得多。 JDOM 还包括对程序行为的相当广泛检查以防止用户做任何在 XML 中无意义的事。 然而,它仍需要您充分理解 XML 以便做一些超出基本的工作(或者甚至理解某些情况下的错误)。 这也许是比学习 DOM 或 JDOM 接口都更有意义的工作。 JDOM 自身不包含解析器。 它通常使用 SAX2 解析器来解析和验证输入 XML 文档(尽管它还可以将以前构造的 DOM 表示作为输入)。 它包含一些转换器以将 JDOM 表示输出成 SAX2 事件流、DOM 模型或 XML 文本文档。 JDOM 是在 Apache 许可证变体下发布的开放源码。 5、DOM4J 虽然 DOM4J 代表了完全独立的开发结果,但最初,它是 JDOM 的一种智能分支。 它合并了许多超出基本 XML 文档表示的功能,包括集成的 XPath 支持、XML Schema 支持以及用于大文档或流化文档的基于事件的处理。 它还提供了构建文档表示的选项,它通过 DOM4J API 和标准 DOM 接口具有并行访问功能。 从 2000 下半年开始,它就一直处于开发之中。 为支持所有这些功能,DOM4J 使用接口和抽象基本类方法。 DOM4J 大量使用了 API 中的 Collections 类,但是在许多情况下,它还提供一些替代方法以允许更好的性能或更直接的编码方法。 直接好处是,虽然 DOM4J 付出了更复杂的 API 的代价,但是它提供了比 JDOM 大得多的灵活性。 在添加灵活性、XPath 集成和对大文档处理的目标时,DOM4J 的目标与 JDOM 是一样的:针对 Java 开发者的易用性和直观操作。 它还致力于成为比 JDOM 更完整的解决方案,实现在本质上处理所有 Java/XML 问题的目标。 在完成该目标时,它比 JDOM 更少强调防止不正确的应用程序行为。 DOM4J 是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件。 如今你可以看到越来越多的 Java 软件都在使用 DOM4J 来读写 XML,特别值得一提的是连 Sun 的 JAXM 也在用 DOM4J。 6、总述 JDOM 和 DOM 在性能测试时表现不佳,在测试 10M 文档时内存溢出。 在小文档情况下还值得考虑使用 DOM 和 JDOM。 虽然 JDOM 的开发者已经说明他们期望在正式发行版前专注性能问题,但是从性能观点来看,它确实没有值得推荐之处。 另外,DOM 仍是一个非常好的选择。 DOM 实现广泛应用于多种编程语言。 它还是许多其它与 XML 相关的标准的基础,因为它正式获得 W3C 推荐(与基于非标准的 Java 模型相对),所以在某些类型的项目中可能也需要它(如在 javascript 中使用 DOM)。 SAX表现较好,这要依赖于它特定的解析方式。 一个 SAX 检测即将到来的XML流,但并没有载入到内存(当然当XML流被读入时,会有部分文档暂时隐藏在内存中)。 无疑,DOM4J是最好的,目前许多开源项目中大量采用 DOM4J,例如大名鼎鼎的 Hibernate 也用 DOM4J 来读取 XML 配置文件。 如果不考虑可移植性,那就采用DOM4J吧!
windows无法运行安装程序
当系统运行时,先要将所需的指令和数据从外部存储器(如硬盘、软盘、光盘等)调入内存中,CPU再从内存中读取指令或数据进行运算,并将运算结果存入内存中,内存所起的作用就像一个“二传手”的作用。 当运行一个程序需要大量数据、占用大量内存时,内存这个仓库就会被“塞满”,而在这个“仓库”中总有一部分暂时不用的数据占据着有限的空间,所以要将这部分“惰性”的数据“请”出去,以腾出地方给“活性”数据使用。 这时就需要新建另一个后备“仓库”去存放“惰性”数据。 由于硬盘的空间很大,所以微软Windows操作系统就将后备“仓库”的地址选在硬盘上,这个后备“仓库”就是虚拟内存。 在默认情况下,虚拟内存是以名为的交换文件保存在硬盘的系统分区中。 手动设置虚拟内存在默认状态下,是让系统管理虚拟内存的,但是系统默认设置的管理方式通常比较保守,在自动调节时会造成页面文件不连续,而降低读写效率,工作效率就显得不高,于是经常会出现“内存不足”这样的提示,下面就让我们自已动手来设置它吧。 ①用右键点击桌面上的“我的电脑”图标,在出现的右键菜单中选择“属性”选项打开“系统属性”窗口。 在窗口中点击“高级”选项卡,出现高级设置的对话框;②点击“性能”区域的“设置”按钮,在出现的“性能选项”窗口中选择“高级”选项卡,打开其对话框。 ③在该对话框中可看到关于虚拟内存的区域,点击“更改”按钮进入“虚拟内存”的设置窗口。 选择一个有较大空闲容量的分区,勾选“自定义大小”前的复选框,将具体数值填入“初始大小”、“最大值”栏中,而后依次点击“设置→确定”按钮即可,最后重新启动计算机使虚拟内存设置生效。 以上是Windows XP操作系统中虚拟内存的设置方法,笔者在此也简单提一下在Windows 98操作系统中的设置:在Windows 98系统中依次进入“开始→设置→控制面板→系统→性能→虚拟内存”,在弹出的对话框中选中“用户自己指定虚拟内存设置”选项,将虚拟内存的位置设在合适的分区中,并设定好虚拟内存的最小值与最大值,最后点击“确定”按钮完成。 建议:可以划分出一个小分区专门提供给虚拟内存、IE临时文件存储等使用,以后可以对该分区定期进行磁盘整理,从而能更好提高计算机的工作效率。 量身定制虚似内存1.普通设置法根据一般的设置方法,虚拟内存交换文件最小值、最大值同时都可设为内存容量的1.5倍,但如果内存本身容量比较大,比如内存是512MB,那么它占用的空间也是很可观的。 所以我们可以这样设定虚拟内存的基本数值:内存容量在256MB以下,就设置为1.5倍;在512MB以上,设置为内存容量的一半;介于256MB与512MB之间的设为与内存容量相同值。 2.精准设置法由于每个人实际操作的应用程序不可能一样,比如有些人要运行3DMAX、Photoshop等这样的大型程序,而有些人可能只是打打字、玩些小游戏,所以对虚拟内存的要求并不相同,于是我们就要因地制宜地精确设置虚拟内存空间的数值。 ①先将虚拟内存自定义的“初始大小”、“最大值”设为两个相同的数值,比如500MB;②然后依次打开“控制面板→管理工具→性能”,在出现的“性能”对话框中,展开左侧栏目中的“性能日志和警报”,选中其下的“计数器日志”,在右侧栏目中空白处点击右键,选择右键菜单中的“新建日志设置”选项;③在弹出的对话框“名称”一栏中填入任意名称,比如“虚拟内存测试”。 在出现窗口中点击“添加计数器”按钮进入下一个窗口;④在该窗口中打开“性能对象”的下拉列表,选择其中的“Paging File”,勾选“从列表中选择计数器”,并在下方的栏目中选择“%UsagePeak”;勾选“从列表中选择范例”,在下方的栏目中选择“_Total”,再依次点击“添加→关闭”结束。 ⑤为了能方便查看日志文件,可打开“日志文件”选项卡,将“日志文件类型”选择为“文本文件”,最后点击“确定”按钮即可返回到“性能”主界面;⑥在右侧栏目中可以发现多了一个“虚拟内存测试”项目,如果该项目为红色则说明还没有启动,点击该项,选择右键菜单中的“启动”选项即可。 接下来运行自己常用的一些应用程序,运行一段时间后,进入日志文件所在的系统分区下默认目录“PerfLogs”,找到“虚拟内存测试_”并用记事本程序打开它,在该内容中,我们查看每一栏中倒数第二项数值,这个数值是虚拟内存的使用比率,找到这项数值的最大值,比如图中的“46”,用46%乘以500MB(前面所设定的虚拟内存数值),得出数值为230MB。 用该数值可以将初始大小设为230MB,而最大值可以根据磁盘空间大小自由设定,一般建议将它设置为最小值的2到3倍。 这样我们就可以将虚拟内存打造得更精准,使自己的爱机运行得更加流畅、更具效率了。











发表评论