
现代数据基础设施的核心基石
在数字化时代,数据量的爆炸式增长对存储系统的可扩展性、可靠性和性能提出了前所未有的挑战,传统的集中式存储架构在应对海量数据、高并发访问和跨地域容灾时逐渐显露出瓶颈,而分布式软件存储层凭借其灵活的架构设计和卓越的横向扩展能力,成为构建现代数据基础设施的核心选择,本文将深入探讨分布式软件存储层的核心原理、关键技术、应用场景及未来发展趋势。
分布式软件存储层的核心原理
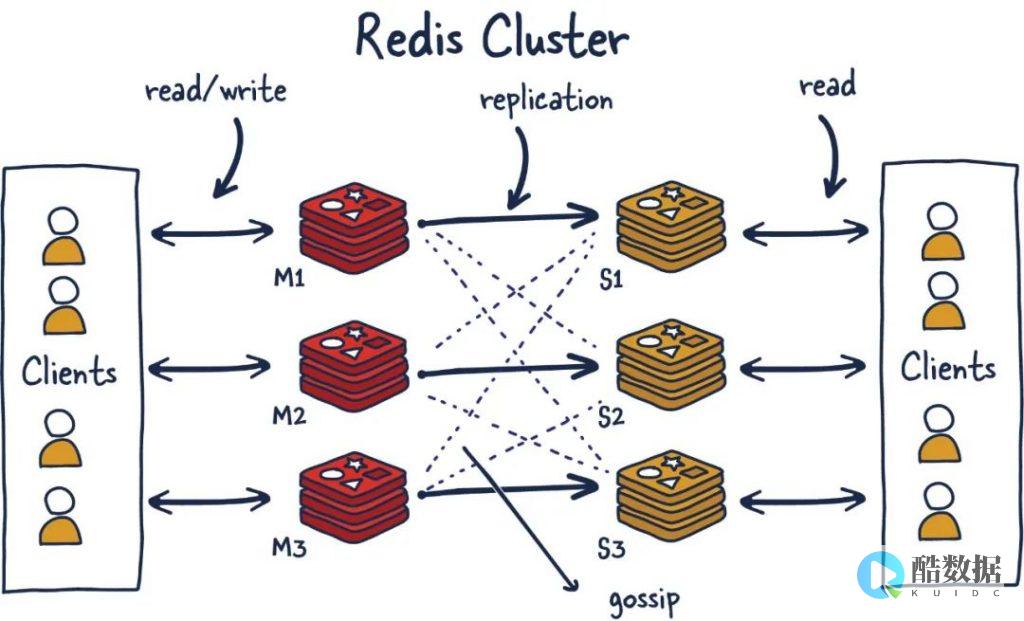
分布式软件存储层是通过将数据分散存储在多个独立节点(服务器)上,通过网络协同工作,对外提供统一存储服务的软件系统,其核心思想在于“化整为零”:数据被切分为多个分片(Shard),通过一致性哈希、副本机制或纠删码等技术分布在不同节点,既实现了存储容量的线性扩展,又通过冗余备份保障数据可靠性,与集中式存储相比,分布式架构打破了单点性能限制,能够通过增加节点轻松提升整体存储容量和吞吐量,同时具备更高的容错能力——即使部分节点故障,系统仍可通过数据副本或重构保证服务不中断。
关键技术:支撑分布式存储的三大支柱
分布式软件存储层的稳定运行依赖于多项核心技术的协同作用。
数据分片与一致性哈希 数据分片是分布式存储的基础,通过将大文件拆分为固定大小的数据块(如4MB、8MB),并分配到不同节点,实现负载均衡,一致性哈希算法则优化了分片映射机制,它通过虚拟节点技术减少数据迁移成本:当新增或删除节点时,仅影响少量相邻节点的数据分片,避免全局数据重分布,从而降低系统开销。
冗余机制与数据可靠性 为防止硬件故障或数据损坏,分布式存储通常采用副本或纠删码技术,副本机制通过保存多个数据副本(如3副本)确保数据可用性,适用于对读写性能要求较高的场景;纠删码则通过数学计算将数据分割为数据块和校验块,以更低的存储开销(如10+2纠删码)实现相同级别的容错,适合成本敏感的大规模存储场景。
分布式协议与一致性保障 在分布式环境中,多个节点间的数据一致性是关键挑战,Paxos、Raft等共识算法通过节点间投票机制确保数据修改的原子性和一致性,而最终一致性模型(如BASE理论)则允许短暂的数据不一致,优先保障系统可用性,适用于对实时性要求不高的场景,分布式锁、事务协调等机制进一步优化了多节点协同效率。
应用场景:从云计算到边缘计算
分布式软件存储层的灵活性使其在多个领域发挥重要作用,在
 云计算
中,分布式存储(如Ceph、GlusterFS)为公有云和私有云提供了弹性存储服务,支撑虚拟机、容器等云原生存储需求;在
大数据平台
中,HDFS(Hadoop Distributed File System)作为分布式文件系统,支撑着Hadoop、Spark等计算框架的海数据存储与分析;在
边缘计算
场景下,轻量级分布式存储(如MinIO)能够满足低延迟数据处理需求,适用于物联网、工业互联网等实时性要求高的领域;在
内容分发网络(CDN)
中,分布式存储通过缓存热门内容到边缘节点,显著提升用户访问速度。
云计算
中,分布式存储(如Ceph、GlusterFS)为公有云和私有云提供了弹性存储服务,支撑虚拟机、容器等云原生存储需求;在
大数据平台
中,HDFS(Hadoop Distributed File System)作为分布式文件系统,支撑着Hadoop、Spark等计算框架的海数据存储与分析;在
边缘计算
场景下,轻量级分布式存储(如MinIO)能够满足低延迟数据处理需求,适用于物联网、工业互联网等实时性要求高的领域;在
内容分发网络(CDN)
中,分布式存储通过缓存热门内容到边缘节点,显著提升用户访问速度。
未来趋势:智能化与云原生化演进
随着云原生、AI技术的普及,分布式软件存储层正朝着更智能、更高效的方向发展。 AI驱动存储优化 成为趋势,通过机器学习算法预测数据访问模式,动态调整数据分片布局和缓存策略,提升系统性能; 云原生存储 与容器化、微服务架构深度融合,支持存储资源的按需分配和自动化运维,进一步降低管理成本。 存算分离架构 的兴起将计算与存储资源解耦,实现存储资源的独立扩展和共享,为AI、大数据等场景提供更灵活的支撑。
分布式软件存储层作为现代数据基础设施的核心组件,通过其可扩展、高可靠、高性能的特性,为云计算、大数据、边缘计算等场景提供了坚实支撑,随着技术的不断演进,分布式存储将更加智能化、云原生化,持续推动数据价值的深度挖掘,在未来,构建高效、灵活的分布式存储体系,将成为企业数字化转型的重要基石。











发表评论