

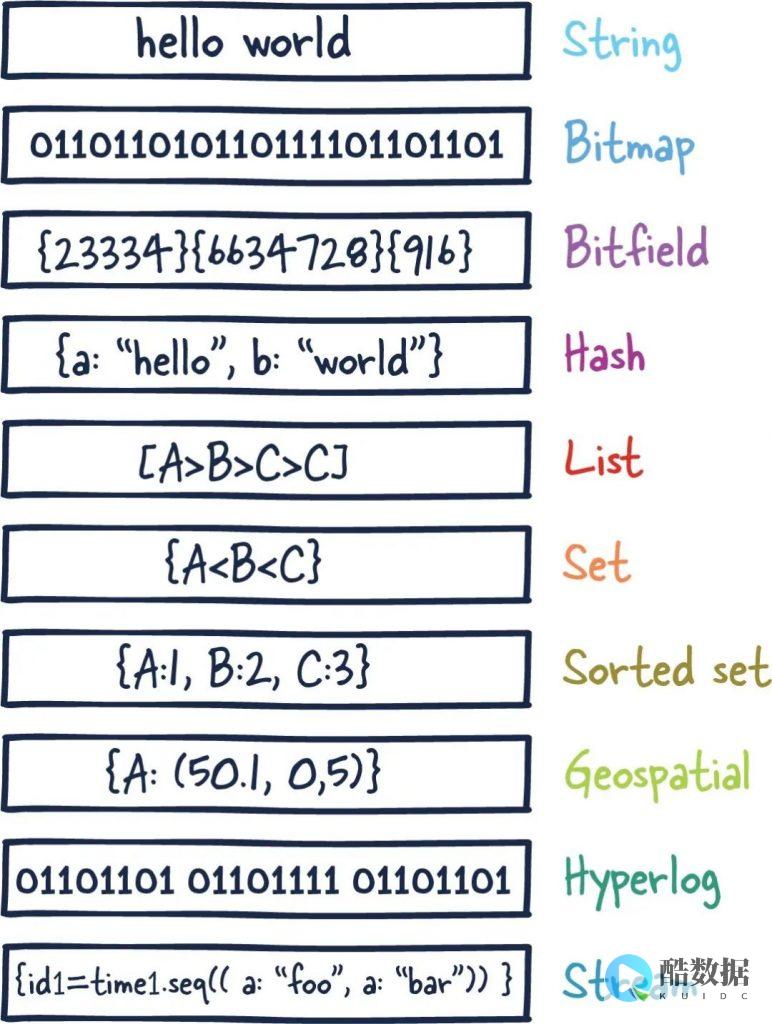
Redis中实现多线程过期策略
在使用Redis作为缓存服务时,数据的过期策略是非常重要的。在大流量场景中,如果缓存设置不当或者用户行为发生变化,可能会导致缓存中的数据失效,影响系统的性能和稳定性。为了解决这个问题,可以通过Redis的多线程过期策略来提升缓存的效率和可靠性。
1. Redis的过期策略
Redis中通过设置过期时间来控制数据的有效期,当数据过期后会被自动删除。在Redis中有两种过期策略:懒惰策略和定期删除策略。
懒惰策略:当数据被访问时,Redis会检查数据是否过期,如果已经过期,则立即删除数据。这种策略的优点是在数据过期时可以立即删除,减小了内存占用,但如果某些数据长时间不被访问,就会一直占用内存,影响 Redis 的性能。
定期删除策略:Redis会每隔一段时间,对一定数量的数据库随机键进行检查,删除其中已经过期的数据。这种策略的优点是能够定期清理过期数据,使内存占用更加稳定,但在清理过程中可能会耗费大量的 CPU 和内存资源,导致 Redis 反应变慢。
2. Redis的多线程过期策略
Redis在多线程模式下的过期检查策略是采用定期删除策略的基础上,加上多个线程并行地处理过期键的检查和删除操作,从而提高了 Redis 的过期清理效率。
在Redis 4.0.0之前,Redis对过期键的删除是单线程执行,只能通过升级Redis版本来实现多线程过期策略。在Redis 4.0.0之后,Redis引入了新的过期策略——主动删除策略(active-expire),该策略通过增加不同批次的过期键数量来提高过期键的清理效率。并且,Redis还支持用户自定义多线程的过期清理策略,可以更加灵活地控制过期键的清理。
以下是使用Python编写多线程过期键的示例代码:
import redis
import threading
r = redis.Redis()
def expire_keys():
while True:
keys = r.scan_iter(match=’*’, count=100)
for key in keys:
if r.ttl(key)
r.delete(key)
time.sleep(1)
threads = []
for i in range(10):
t = threading.Thread(target=expire_keys)
threads.append(t)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
上述代码中,我们使用了Redis的scan_iter()方法来遍历所有的缓存键,然后通过判断键的剩余过期时间来进行删除。3. 总结通过多线程过期策略,我们可以提高Redis的性能和可靠性。在实际项目中,我们可以根据实际情况来选择不同的过期策略和线程数,从而达到更好的效果。
香港服务器首选树叶云,2H2G首月10元开通。树叶云(www.IDC.Net)提供简单好用,价格厚道的香港/美国云 服务器 和独立服务器。IDC+ISP+ICP资质。ARIN和APNIC会员。成熟技术团队15年行业经验。
Redis详解------ 过期删除策略
Redis的过期删除策略涉及一系列精细的操作,主要通过设置键的生存时间和删除策略来确保数据的时效性和内存管理的效率。主要有以下几点:
1. 设置过期时间
Redis提供了四种命令来设置键的生存时间:EXPIRE/PEXPIRE 以秒或毫秒为单位,EXPIREAT/PEXPIREAT 以时间戳指定。 实际上,前三个命令最终都会被转换为PEXPIREAT来执行。
2. 过期时间判定与移除
Redis会在设置键过期时将其存入过期字典。 查询时,会检查键是否过期,过期则从内存中移除。 移除键的过期时间使用PERSIST,查询剩余生存时间则有TTL和PTTL。
3. 过期删除策略删除策略包括:定时删除(内存友好,可能影响CPU)、惰性删除(CPU友好,可能导致内存泄漏)和定期删除(减少对CPU影响,但需平衡删除频率)。 Redis采用惰性删除和定期删除的组合,确保在使用时检查过期,同时定期清理过期键。
在Redis 2.6及以后版本,定期删除的频率可以通过修改hz配置进行调整,但应避免设置过高以减轻CPU压力。
内存管理
如果过期键未被定期删除,可能造成内存占用。 这时,Redis的内存淘汰策略会介入,以确保内存资源的合理分配。
redis设置的超时时间单位(redis过期时间单位)
redis设置的超时时间单位token存储在redis中,设置了过期时间,过期就过期了 ,不需要去刷新token。 token过期后,客户端可以依据refreshtoken来获取新的token。 redis过期时间单位EXPIRE 接口定义:EXPIRE key seconds接口描述:设置一个key在当前时间seconds(秒)之后过期。 返回1代表设置成功,返回0代表key不存在或者无法设置过期时间。 例如:EXPIRE aa 60PEXPIRE 接口定义:PEXPIRE key milliseconds接口描述:设置一个key在当前时间milliseconds(毫秒)之后过期。 返回1代表设置成功,返回0代表key不存在或者无法设置过期时间。 例如:EXPIRE aa 60(integer) 1 //设置redis设置的超时时间单位是什么Redis的timeout可以指定单位是秒还是毫秒,语法如下:SET key value [EX seconds] [PX milliseconds] [NX|XX]举例:set name zhangsan ex 10十秒钟后过期,此处ex后面单位是秒set name zhangsan px 毫秒后过期,此处px后面单位是毫秒java设置redis数据超时时间redis设置过期时间可以用expire命令,设置的是过期时间戳,之后访问该key时,会将当前时间戳和过期时间戳做比较,如果已经过期,则会清除掉该key的数据redis 超时时间设置EXPIRE PEXPIRE EXPIRE 接口定义:EXPIRE key seconds 接口描述:设置一个key在当前时间seconds(秒)之后过期。 返回1代表设置成功,返回0代表key不存在或者无法设置过期时间。 PEXPIRE 接口定义:PEXPIRE key milliseconds 接口描述:设置一个key在当前时间milliseconds(毫秒)之后过期。 返回1代表设置成功,返回0代表key不存在或者无法设置过期时间。 redis连接默认超时时间SETEX 命令可以在设直一个字符串键的同时为键设直过期时间,因为这个命令是一个类型限定的命令(只能用于字符串键),但SETEX 命令设置过期时间的原理和EXPIRE命令设置过期时间的原理是完全一样的。 与EXPlRE 命令和PEXPIRE 命令类似,客户端可以通过EXPlREAT 命令或PEXPlREAT命令,以秒或者毫秒精度给数据库中的某个键设置过期时间(expire time)。 redis失效时间单位最近在使用redis,用到里面的incrBy操作,但是这个API没有提供一个参数来设置key的失效时间。 我自己想了一个比较low的办法。 Long limit = (limitCacheKey, 1);//拿到数字1的那个线程,设置key的有效期if (limit == 1) {(limitCacheKey,2);}就是当incrBy的返回值是1的时候,让拿到1的那个线程帮忙设置一下key的失效时间。 由于incrBy是原子性的,拿到1的肯定只有一个线程,所以不会存在并发调用expired操作的可能。 经过验证,这个方法是可行的,但是感觉很lowredis设置的超时时间单位有哪些1. 什么是Redis一款内存高速缓存数据库(全称远程数据服务);使用C语言编写Redis是一个key-value存储系统,它支持丰富的数据类型,如:string、list、set、zset(sorted set)、hash等特点Redis以内存作为数据存储介质,所以读写数据的效率极高,远远超过数据库。 以设置和获取一个256字节字符串为例,它的读取速度可高达次/s,写速度高达次/s。 储存在Redis中的数据是持久化的,断电或重启后,数据也不会丢失。 -----Redis的存储分为内存存储、磁盘存储和log文件三部分,重启后,Redis可以从磁盘重新将数据加载到内存中。 (实现持久化)应用场景,它能做什么在服务器中常用来存储一些需要频繁调取的数据,这样可以大大节省系统直接读取磁盘来获得数据的I/O开销,更重要的是可以极大提升速度。 (拿大型网站来举个例子,比如a网站首页一天有100万人访问,其中有一个板块为推荐新闻。 要是直接从数据库查询,那么一天就要多消耗100万次数据库请求。 上面已经说过,Redis支持丰富的数据类型,所以这完全可以用Redis来完成,将这种热点数据存到Redis(内存)中,要用的时候,直接从内存取,极大的提高了速度和节约了服务器的开销。 )使用Redis有哪些好处?(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)(2) 支持丰富数据类型,支持string,list,set,sorted set,hash(3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除redis相比memcached有哪些优势?(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型(2) redis的速度比memcached快很多(3) redis可以持久化其数据redis常见性能问题和解决方案:(1) Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件(2) 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次(3) 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内(4) 尽量避免在压力很大的主库上增加从库(5) 主从复制不要用图状结构,用单向链表结构更为稳定和mySql的区别总结(1)类型上从类型上来说,MYSQL是关系型数据库,redis是缓存数据库(2)作用上mysql用于持久化的存储数据到硬盘,功能强大,但是速度较慢redis用于存储使用较为频繁的数据到缓存中,读取速度快(3)需求上mysql和redis因为需求的不同,一般都是配合使用。 和mysql要根据具体业务场景去选型redis和mysql要根据具体业务场景去选型mysql:数据放在磁盘 redis:数据放在内存mysql支持sql查询,可以实现一些关联的查询以及统计;redis对内存要求比较高,在有限的条件下不能把所有数据都放在redis;mysql偏向于存数据,redis偏向于快速取数据,但redis查询复杂的表关系时不如mysql,所以可以把热门的数据放redis,mysql存基本数据redis设置过期时间为当天凌晨通过EXPIRE 命令或者PEXPIRE 命令,客户端可以以秒或者毫秒精度为数据库中的某个键设置生存时间( Time To Live , TTL) ,在经过指定的秒数或者毫秒数之后,服务器就会自动删除生存时间为0的键:redis> SET key valueOKredis> EXP 工RE key 5(integer) 1redis> GET key // 5 秒之内valueredis> GET key // 5 秒之后(nil)redis给hash中的值设置超时Redis一共支持5种数据结构,hash是其中的一种,在hash扩容的时候采用的是渐进式rehash的方式。 rehash原理字典中包含一个数据结构dictht的ht数组,一般情况下字典只是用ht[0]用来存储数据,ht[1]在rehash时使用。 随着操作的不断执行,哈希表中的元素会逐渐增加或者减少,为了让哈希表的负载因子维持在一个合理的范围内,程序需要对哈希表的大小进行相应的扩容和收缩。 步骤如下:为ht[1]哈希表分配空间。 如果是扩容操作,ht[1]的大小为第一个大于等于ht[0]*2的2的n次方幂,如果是收缩操作,ht[1]的大小为第一个大于等于ht[0]的2的n次方幂将保存在ht[0]中的所有键值对rehash到ht[1]:rehash指的是重新计算键的哈希值和索引值,然后将键值对放到ht[1]对应位置上当ht[0]包含的所有键值对都迁移到ht[1]之后,释放ht[0],将ht[1]设置为ht[0],并在ht[1]新创建一个空白哈希表,为下一次rehash做准备
Redis过期删除策略和内存淘汰策略
Redis可以用使用 expire 指令设置过期时间,在Redis内部,每当我们设置一个键的过期时间时,Redis就会将该键带上过期时间存放到一个过期字典中。 当我们查询一个键时,Redis便首先检查该键是否存在过期字典中,如果存在,那就获取其过期时间。 然后将过期时间和当前系统时间进行比对,比系统时间大,那就没有过期;反之判定该键过期。
那对于过期数据,一般有三种方式进行处理:
Redis的过期删除策略: 惰性删除 和 定期删除 两种策略配合使用。
spring-boot-starter-data-redis 包中提供了监听过期的类,对于key过期,需要得到通知,做业务处理的,可以做此监听。
springboot整合Redis参考, SpringBoot整合Redis -() 在整合Redis的基础上,在新加监听配置
监听配置类
监听类
将Redis用作缓存时,如果内存空间用满,就会自动驱逐老的数据。
Redis中有6种淘汰策略:
文件中配置策略,有2个地方:













发表评论