

缓存数据库是现代Web应用程序设计中的一种更佳实践。它通过将频繁使用的数据存储在本地,从而大大提高了数据检索速度和系统响应时间。Angular技术带来的好处之一就是它可以轻松地实现缓存数据库。本文将讨论Angular技术如何实现缓存数据库,并介绍它的各种好处。
让我们了解Angular中的缓存数据库是如何工作的。Angular提供了两种缓存数据库构建器:原生和HTTP。原生构建器可以在客户端使用任何类型的缓存数据库进行缓存,而HTTP构建器则与Angular的HttpClient密切集成,可以在发送HTTP请求时通过HttpInterceptors向响应添加缓存逻辑。下面我们将着重介绍HTTP构建器。
为了开始使用缓存数据库,我们需要创建一个适当的HttpInterceptor。这个拦截器是一个可复用的服务,我们可以在项目中的任何地方使用它。在这个拦截器中,我们定义了缓存数据库的行为,包括缓存的存储时间、缓存拦截请求、缓存到期时清除缓存等。下面是一个示例拦截器的代码:
“`typescript
import { Injectable } from ‘@angular/core’;
import { HttpInterceptor, HttpRequest, HttpResponse, HttpHandler } from ‘@angular/common/http’;
import { Observable, of } from ‘rxjs’;
import { tap } from ‘rxjs/operators’;
@Injectable()
export class CacheInterceptor implements HttpInterceptor {
private cache = new Map();
intercept(req: HttpRequest, next: HttpHandler): Observable> {
const cachedResponse = this.cache.get(req.url);
if (cachedResponse) {
return of(cachedResponse);
return next.handle(req).pipe(
tap(event => {
if (event instanceof HttpResponse) {
this.cache.set(req.url, event);
在这个拦截器中,我们创建了一个名为cache的Map,用于存储与url相关联的响应。在拦截请求时,我们首先在cache中查找是否已经缓存了该请求的响应。如果已经缓存了,则简单地返回响应。如果未缓存,则发送请求并拦截响应。在拦截响应时,我们将响应存储到cache中,以备将来使用。
有了这个拦截器,我们就可以通过向HttpClient中添加拦截器来实现应用程序范围的缓存。下面是一个示例方法,该方法使用HttpClinet从 服务器 获取某些数据:
“`typescript
import { Component } from ‘@angular/core’;
import { HttpClient } from ‘@angular/common/http’;
@Component({
selector: ‘app-root’,
templateUrl: ‘./app.component.html’
export class AppComponent {
>PHP DUXCMS如何开启页面缓存
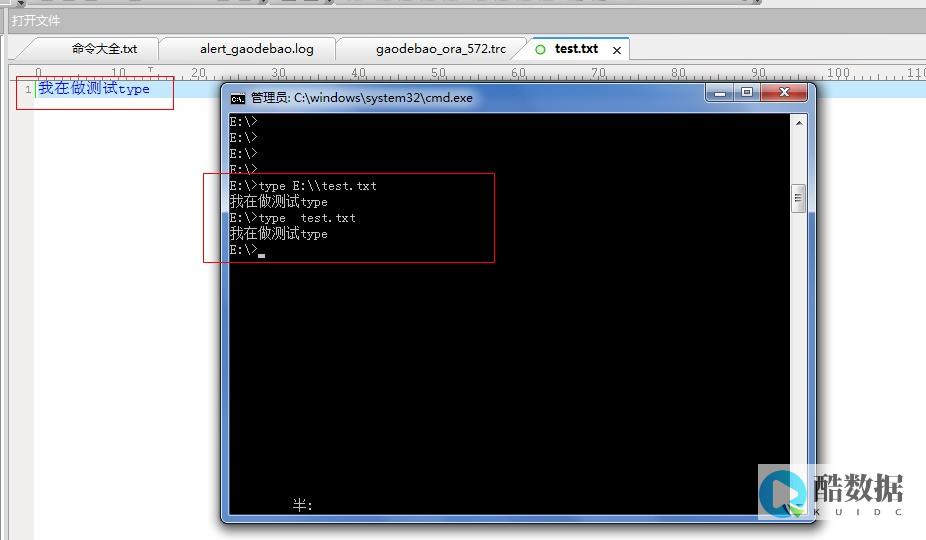
1.页面缓存。页面缓存指之前加载过的页面以文件方式缓存在服务器中,在一段时间内再次加载相同页面时无需重新执行页面逻辑直接加载静态页面。rubyPHP的页面缓存是自动进行的,在config/tpl.php中可配置是否启用缓存以及缓存文件的有效期。当然这仅仅是全局设置,在调用视图时可重新指定是否启用缓存以及缓存有效期。
2.SQL缓存。sql缓存指之前执行过的查询sql语句以及他的结果缓存在内存中,在一段时间内用相同的sql语句执行查询操作时不经过数据库直接返回内存中数据。rubyPHP使用Redis以键值方式缓存sql语句以及他的对应结果。rubyPHP能够在php7上完美运行。(附:关于windows php7 redis 扩展的下载参蠢笑照我的另一篇博客:
)。rubyPHP重写了mysql_query以及mongo_query方法,在执行查询sql查询语句时会优先加载未过期的缓存数据。与页面缓存类似,sql缓存的全局配置路径为config/redis.php,在具体执行sql语句前可重新执行是否使用缓存以及缓存有效期。
3.读写分离。读写分离是建立在主从同步基础上为了减轻服务器压力,将查询语句转移到从服务器上执行的解决方案。rubyPHP重写了mysql_query,mongo_query函数,除了对查询语句进行内存级缓存的优化,同时也将查询语句放到了从服务器上执行。mysql的主从配置文件路径为config/mysql.php。
4.html压缩。html压缩配合页面缓存,前者降低了服务器端压力,后者减少了输出内容所占空间,将html文件中的空格换行等进行压缩,减少了输出文件的大小,在一定程度上保护了html的安全。
rubyPHP在代码结构上模仿CI,在功能上模仿thinkPHP。
rubyPHP的功能包含以下几方面:
1.使用了thinkPHP的M方法操作数据库。对于一些简单的sql语句无需手工写,用熟悉的M()->where()->limit()->find()这样的语法即可完成。曾经面试有人问我为什么thinkPHP的M方法能够进行连续操作,现在终于明白是使用了单利模式。
2.屏蔽了数据库的差异。M方法的另一个优点是用来组件sql语句,对高层屏蔽数据库差异。当然,对于复杂的查询,M方法是做不到的,此时可以使用已被重写过的mysql_query以及mongo_query执行你的sql语句。
3.自定义路由。这一点模仿了CI的route.php,将url同咐核控制器的映射关系写到一个配置文件里。
不足之处:
view文件不支持变量循环输出。目前的解决方案是使用angularjs调用接口在页面输出内容。框架示例程序便是一个使用angularjs的和bootstrap的界面带简含。

angular6.x–虚拟滚动
1.安装@angular/material、@angular/cdk
cnpm install –save @angular/material @angular/cdk
2.app.module.ts导入模块
3.在当前组件引入
1.Context Variables
使用*cdkVirtualFOR,我们有一些上下文变量:index, count, first, last, even, odd.
2.视图回收
为了提高渲染性能, *cdkVirtualFor 会缓存那些曾经创建过但不再需要的视图。当要创建一个新视图时,会转而复用一个已缓存的视图。可以通过 templateCacheSize 属性来调整视图缓存的大小。把这个大小设置为 0 会禁用缓存。如果你的模板在内存方面很昂贵,你可能会希望减小这个数字,以免在模板缓存上花费太多内存。
3.固定超过滚动视图的item个数
minBufferPx maxBufferPx
当所有条目都是固定大小时,你可以使用 FixedSizeVirtualScrollStrategy。可以用 itemSize 指令轻松地将它添加到视口中。这种约束的优点是它可以提供更好的性能,因为在渲染条桐袭滚目时不需要进行测量。
固定大小的策略也支持设置一些缓冲区参数,用来决定渲染多少额外内容,也就是视口可见内容之外的部分。之一个参数是 minBufferPx。 minBufferPx 是视口必须渲染的最小内容缓冲区数量(以像素为单位)。如果视口检测到要缓冲的内容小于这个数量(未填满),就会立即渲染更多内容。 第二个参数是 maxBufferPx。它会告诉视口当检测到需要更多缓冲区的时候要渲染多少个备用缓冲区空间。
这两个缓冲区参数的作用可以用一个例子来说明。假设我们有以下参数:itemSize = 50、minBufferPx = 100、maxBufferPx = 250。当用户滚动浏览内容时,视口就会检测到只剩下 90px 的缓冲区。由于它小于 minBufferPx,所以视口必须渲染更多缓冲区。它必须渲染足够数量的缓冲区,直到其大于等于 maxBufferPx。在这种情况下,它渲染了4个条目(额外的 200px),使缓冲区总大小达到290px,略高于maxBufferPx 。
4.视口方向
虚拟滚动视口默认为垂直方向,也可局余以设置为 orientation=”horizontal”。在改变方向时,要确保该条目是用 CSS 进行水平布局的。要做到这一点,你可能希望把 .cdk-virtual-scroll-content-wrapper 类作为 CSS 的目标,它是包含待渲染内容的包装元素。
5.数据
*cdkVirtualFor 接受来自 Array、Observable 或>Angular提供Tree组件吗?能绑定统计数据而非具体数据库字段吗
Angular UI Tree是一个Angular UI 组件,可渣者排序嵌套列表,提供拖放支持,不依赖于jQuery。
特性
使用原生Angular范围数据绑定游梁码
排序并通过整个树移动神哪项目
Prevent elements from accepting child nodes
支持的浏览器
The Angular UI Tree is tested with the following browsers:
Chrome (stable)
IE 8, 9 and 10
For IE8 support, make sure you do the following:
include an ES5 shim
make your Angular application compatible with Internet Explorer
use jQuery 1.x
angular 缓存数据库的介绍就聊到这里吧,感谢你花时间阅读本站内容,更多关于angular 缓存数据库,Angular技术带来的好处:缓存数据库,PHP DUXCMS如何开启页面缓存,angular6.x–虚拟滚动,Angular提供Tree组件吗?能绑定统计数据而非具体数据库字段吗的信息别忘了在本站进行查找喔。
香港服务器首选树叶云,2H2G首月10元开通。树叶云(www.IDC.Net)提供简单好用,价格厚道的香港/美国云服务器和独立服务器。IDC+ISP+ICP资质。ARIN和APNIC会员。成熟技术团队15年行业经验。

Hibernate主要的优点在哪里 ?
对象关系映射框架 它要在配置文件配置每个类的一个映射关系 比如 一个机构里面有很多个部门 部门里面还有部门 ,用hibernate使用懒惰加载只要加载一个机构对象出来就可以了 ,而你原始的JDBC 要先查询机构 再查询这个机构的部门 ,查完还要查子部门 。 完成一次查询你可能要连接好几次数据库!你认为哪个快 !当然 这个只是hibernate其中一个功能罢了。
百度求解缓冲材料那种比较好
一般市面上比较常见的有EVA、PU、PE这些缓冲效果一般在30%以内,能高过30%的算是非常的牛的了,不过成本比较低这类材料,也算是一点优势吧。 还有一种目前市面上比较少见的艾丝孚,缓冲效果还不错。
电脑二级缓存大小有什么用?
二级缓存又叫L2 CACHE,它是处理器内部的一些缓冲存储器,其作用跟内存一样。 它是怎么出现的呢? 要上溯到上个世纪80年代,由于处理器的运行速度越来越快,慢慢地,处理器需要从内存中读取数据的速度需求就越来越高了。 然而内存的速度提升速度却很缓慢,而能高速读写数据的内存价格又非常高昂,不能大量采用。 从性能价格比的角度出发,英特尔等处理器设计生产公司想到一个办法,就是用少量的高速内存和大量的低速内存结合使用,共同为处理器提供数据。 这样就兼顾了性能和使用成本的最优。 而那些高速的内存因为是处于CPU和内存之间的位置,又是临时存放数据的地方,所以就叫做缓冲存储器了,简称“缓存”。 它的作用就像仓库中临时堆放货物的地方一样,货物从运输车辆上放下时临时堆放在缓存区中,然后再搬到内部存储区中长时间存放。 货物在这段区域中存放的时间很短,就是一个临时货场。 最初缓存只有一级,后来处理器速度又提升了,一级缓存不够用了,于是就添加了二级缓存。 二级缓存是比一级缓存速度更慢,容量更大的内存,主要就是做一级缓存和内存之间数据临时交换的地方用。 现在,为了适应速度更快的处理器P4EE,已经出现了三级缓存了,它的容量更大,速度相对二级缓存也要慢一些,但是比内存可快多了。 缓存的出现使得CPU处理器的运行效率得到了大幅度的提升,这个区域中存放的都是CPU频繁要使用的数据,所以缓存越大处理器效率就越高,同时由于缓存的物理结构比内存复杂很多,所以其成本也很高。 大量使用二级缓存带来的结果是处理器运行效率的提升和成本价格的大幅度不等比提升。 举个例子,服务器上用的至强处理器和普通的P4处理器其内核基本上是一样的,就是二级缓存不同。 至强的二级缓存是2MB~16MB,P4的二级缓存是512KB,于是最便宜的至强也比最贵的P4贵,原因就在二级缓存不同。 即L2 Cache。 由于L1级高速缓存容量的限制,为了再次提高CPU的运算速度,在CPU外部放置一高速存储器,即二级缓存。 工作主频比较灵活,可与CPU同频,也可不同。 CPU在读取数据时,先在L1中寻找,再从L2寻找,然后是内存,在后是外存储器。 所以L2对系统的影响也不容忽视。 CPU缓存(Cache Memory)位于CPU与内存之间的临时存储器,它的容量比内存小但交换速度快。 在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。 由此可见,在CPU中加入缓存是一种高效的解决方案,这样整个内存储器(缓存+内存)就变成了既有缓存的高速度,又有内存的大容量的存储系统了。 缓存对CPU的性能影响很大,主要是因为CPU的数据交换顺序和CPU与缓存间的带宽引起的。 缓存的工作原理是当CPU要读取一个数据时,首先从缓存中查找,如果找到就立即读取并送给CPU处理;如果没有找到,就用相对慢的速度从内存中读取并送给CPU处理,同时把这个数据所在的数据块调入缓存中,可以使得以后对整块数据的读取都从缓存中进行,不必再调用内存。 正是这样的读取机制使CPU读取缓存的命中率非常高(大多数CPU可达90%左右),也就是说CPU下一次要读取的数据90%都在缓存中,只有大约10%需要从内存读取。 这大大节省了CPU直接读取内存的时间,也使CPU读取数据时基本无需等待。 总的来说,CPU读取数据的顺序是先缓存后内存。 最早先的CPU缓存是个整体的,而且容量很低,英特尔公司从Pentium时代开始把缓存进行了分类。 当时集成在CPU内核中的缓存已不足以满足CPU的需求,而制造工艺上的限制又不能大幅度提高缓存的容量。 因此出现了集成在与CPU同一块电路板上或主板上的缓存,此时就把 CPU内核集成的缓存称为一级缓存,而外部的称为二级缓存。 一级缓存中还分数据缓存(Data Cache,D-Cache)和指令缓存(Instruction Cache,I-Cache)。 二者分别用来存放数据和执行这些数据的指令,而且两者可以同时被CPU访问,减少了争用Cache所造成的冲突,提高了处理器效能。 英特尔公司在推出Pentium 4处理器时,用新增的一种一级追踪缓存替代指令缓存,容量为12KμOps,表示能存储12K条微指令。 随着CPU制造工艺的发展,二级缓存也能轻易的集成在CPU内核中,容量也在逐年提升。 现在再用集成在CPU内部与否来定义一、二级缓存,已不确切。 而且随着二级缓存被集成入CPU内核中,以往二级缓存与CPU大差距分频的情况也被改变,此时其以相同于主频的速度工作,可以为CPU提供更高的传输速度。 二级缓存是CPU性能表现的关键之一,在CPU核心不变化的情况下,增加二级缓存容量能使性能大幅度提高。 而同一核心的CPU高低端之分往往也是在二级缓存上有差异,由此可见二级缓存对于CPU的重要性。 CPU在缓存中找到有用的数据被称为命中,当缓存中没有CPU所需的数据时(这时称为未命中),CPU才访问内存。 从理论上讲,在一颗拥有二级缓存的CPU中,读取一级缓存的命中率为80%。 也就是说CPU一级缓存中找到的有用数据占数据总量的80%,剩下的20%从二级缓存中读取。 由于不能准确预测将要执行的数据,读取二级缓存的命中率也在80%左右(从二级缓存读到有用的数据占总数据的16%)。 那么还有的数据就不得不从内存调用,但这已经是一个相当小的比例了。 目前的较高端的CPU中,还会带有三级缓存,它是为读取二级缓存后未命中的数据设计的—种缓存,在拥有三级缓存的CPU中,只有约5%的数据需要从内存中调用,这进一步提高了CPU的效率。 为了保证CPU访问时有较高的命中率,缓存中的内容应该按一定的算法替换。 一种较常用的算法是“最近最少使用算法”(LRU算法),它是将最近一段时间内最少被访问过的行淘汰出局。 因此需要为每行设置一个计数器,LRU算法是把命中行的计数器清零,其他各行计数器加1。 当需要替换时淘汰行计数器计数值最大的数据行出局。 这是一种高效、科学的算法,其计数器清零过程可以把一些频繁调用后再不需要的数据淘汰出缓存,提高缓存的利用率。 CPU产品中,一级缓存的容量基本在4KB到64KB之间,二级缓存的容量则分为128KB、256KB、512KB、1MB、2MB等。 一级缓存容量各产品之间相差不大,而二级缓存容量则是提高CPU性能的关键。 二级缓存容量的提升是由CPU制造工艺所决定的,容量增大必然导致CPU内部晶体管数的增加,要在有限的CPU面积上集成更大的缓存,对制造工艺的要求也就越高缓存(Cache)大小是CPU的重要指标之一,其结构与大小对CPU速度的影响非常大。 简单地讲,缓存就是用来存储一些常用或即将用到的数据或指令,当需要这些数据或指令的时候直接从缓存中读取,这样比到内存甚至硬盘中读取要快得多,能够大幅度提升CPU的处理速度。 所谓处理器缓存,通常指的是二级高速缓存,或外部高速缓存。 即高速缓冲存储器,是位于CPU和主存储器DRAM(Dynamic RAM)之间的规模较小的但速度很高的存储器,通常由SRAM(静态随机存储器)组成。 用来存放那些被CPU频繁使用的数据,以便使CPU不必依赖于速度较慢的DRAM(动态随机存储器)。 L2高速缓存一直都属于速度极快而价格也相当昂贵的一类内存,称为SRAM(静态RAM),SRAM(Static RAM)是静态存储器的英文缩写。 由于SRAM采用了与制作CPU相同的半导体工艺,因此与动态存储器DRAM比较,SRAM的存取速度快,但体积较大,价格很高。 处理器缓存的基本思想是用少量的SRAM作为CPU与DRAM存储系统之间的缓冲区,即Cache系统。 以及更高档微处理器的一个显著特点是处理器芯片内集成了SRAM作为Cache,由于这些Cache装在芯片内,因此称为片内Cache。 486芯片内Cache的容量通常为8K。 高档芯片如Pentium为16KB,Power PC可达32KB。 Pentium微处理器进一步改进片内Cache,采用数据和双通道Cache技术,相对而言,片内Cache的容量不大,但是非常灵活、方便,极大地提高了微处理器的性能。 片内Cache也称为一级Cache。 由于486,586等高档处理器的时钟频率很高,一旦出现一级Cache未命中的情况,性能将明显恶化。 在这种情况下采用的办法是在处理器芯片之外再加Cache,称为二级Cache。 二级Cache实际上是CPU和主存之间的真正缓冲。 由于系统板上的响应时间远低于CPU的速度,如果没有二级Cache就不可能达到486,586等高档处理器的理想速度。 二级Cache的容量通常应比一级Cache大一个数量级以上。 在系统设置中,常要求用户确定二级Cache是否安装及尺寸大小等。 二级Cache的大小一般为128KB、256KB或512KB。 在486以上档次的微机中,普遍采用256KB或512KB同步Cache。 所谓同步是指Cache和CPU采用了相同的时钟周期,以相同的速度同步工作。 相对于异步Cache,性能可提高30%以上。 目前,PC及其服务器系统的发展趋势之一是CPU主频越做越高,系统架构越做越先进,而主存DRAM的结构和存取时间改进较慢。 因此,缓存(Cache)技术愈显重要,在PC系统中Cache越做越大。 广大用户已把Cache做为评价和选购PC系统的一个重要指标。












发表评论