
如何
在数据库中,索引是提高查询效率的一个重要因素。索引可以让数据库更快地搜索和过滤数据,减少了查询时间和对系统资源的消耗。因此,变得尤为重要。那么,如何呢?
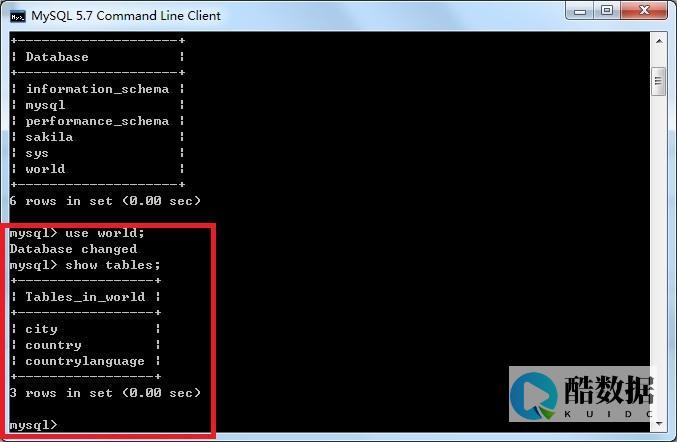
1.使用SHOW INDEXES语句
SHOW INDEXES语句可以让我们查看指定表的所有索引信息。具体使用方法如下:
SHOW INDEXES FROM 表名;
例如,如果想查看名为“users”的表中的所有索引信息,可以使用以下命令:
SHOW INDEXES FROM users;
这个命令会返回一个表,其中包含了表中所有的索引信息。其中,包括索引名、列名、索引类型、是否唯一、索引长度等信息。如果表中有多个索引,会有多行数据返回。
2.使用DESCRIBE语句查看表结构
DESCRIBE语句可以让我们查看指定表的字段结构、索引等信息。具体使用方法如下:
DESCRIBE 表名;
例如,如果想查看名为“users”的表的结构信息,可以使用以下命令:
DESCRIBE users;
这个命令会返回一个表格,其中包含了表中所有字段的相关信息。其中,如果字段被索引,会在“Key”列中显示出相应的索引名。
3.查询information_schema数据库
information_schema是MySQL系统数据库,其中包含了MySQL的元数据信息。可以通过查询information_schema数据库来获取表信息、索引信息等。具体使用方法如下:
SELECT * FROM information_schema.STATISTICS WHERE TABLE_NAME=’表名’;
例如,如果想查看名为“users”的表的索引信息,可以使用以下命令:
SELECT * FROM information_schema.STATISTICS WHERE TABLE_NAME=’users’;
这个命令会返回一个表,其中包含了名为“users”的表的所有索引信息。表中包含了索引名、索引类型、索引顺序、列名等信息。
4.使用workbench查看
workbench是MySQL官方提供的一个GUI工具,可以方便地对MySQL数据库进行管理。可以使用workbench来查看指定表的结构信息,其中包括了索引信息。具体使用方法如下:
1).打开workbench,选择要连接的数据库;
2).在窗口左侧的菜单栏中,找到该数据库下的表;
3).在表列表中选择要查看的表;
4).在窗口中央的“Schema”标签下,选择“Indexes”子标签;
5).这个标签下会显示该表的所有索引信息。
5.使用phpMyAdmin查看
phpMyAdmin是一个开源的基于web的MySQL数据库管理工具。可以使用phpMyAdmin来查看指定表的结构信息,其中包括了索引信息。具体使用方法如下:
1).打开phpMyAdmin;
2).选择要连接的数据库;
3).选择要查看的表;
4).点击表结构信息中的“Indexes”标签页,查看索引信息。
以上就是的方法。通过使用这些方法,能够快速地检查数据库中指定表中所有的索引信息,以便优化或维护表的性能。
相关问题拓展阅读:
如何检查mysql中建立的索引是否生效的检测
explain显示了MySQL如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句。
使用方法,在select语句前加上explain就可以了:
如:
explainselectsurname,first_nameforma,bwherea.id=b.id
EXPLAIN列的解释:
table:显示这一行的数据是关于哪张表的
type:这是重要的列,显示连接使用了何种类型。从更好到最差的连接类型为const、eq_reg、ref、range、indexhe和ALL
possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从WHERE语句中选择一个合适的语句
key: 实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MYSQL会选择优化不足的索引。这种情况下,可以在SELECT语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引
key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref:显示索引的哪一列被使用了,如果可能激数的话,是一个常数
rows:MYSQL认为必须检查的用来返回请求数据的行数
Extra:关于MYSQL如何解析查询的额外信息。将在表4.3中讨论,但这里可以看到的坏的例子是Using temporary和Using filesort,意思MYSQL根本不能使用索引,结果是检索会很慢
extra列返回的描述的意义
Distinct:一旦MYSQL找到了与行相联合匹配的行,就不再搜索了
Not exists: MYSQL优化了LEFT JOIN,一旦它找到了匹配LEFT JOIN标准的行,就不再搜索了
Range checked for each Record(index map:#):没有找到理想的索引,因此对于从前面表中来的每一个行组合,MYSQL检查使用哪个索引,并用它来从表中返回行。这是使用索引的最慢的连接之一
Using filesort: 看到这个的时候,查询就需要优化了。MYSQL需要进行额外的步骤来发现如何对返回的行排序。它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行
Using index: 列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表的全部的请求列都是同一个索引的部分的时候
Using temporary 看到这个的时候型余,查询需要优化了。这里,MYSQL需要创建一个临时表来存储结果,这通常发生在对不同的列集进行ORDER BY上,而不是GROUP BY上
Where used 使用了WHERE从句来限制哪些行将与下一张表匹配或者是返回给用户。如果不想返回表中的全部行,并且连接类型ALL或index,这就会发生,或者是查询有问题不同连接类型的解释(按照效率高低的顺序排序)
system 表只有一行:system表。这是const连接类型的特殊情况
const:表中的一个记录明租首的更大值能够匹配这个查询(索引可以是主键或惟一索引)。因为只有一行,这个值实际就是常数,因为MYSQL先读这个值然后把它当做常数来对待
eq_ref:在连接中,MYSQL在查询时,从前面的表中,对每一个记录的联合都从表中读取一个记录,它在查询使用了索引为主键或惟一键的全部时使用
ref:这个连接类型只有在查询使用了不是惟一或主键的键或者是这些类型的部分(比如,利用最左边前缀)时发生。对于之前的表的每一个行联合,全部记录都将从表中读出。这个类型严重依赖于根据索引匹配的记录多少—越少越好
range:这个连接类型使用索引返回一个范围中的行,比如使用>或
index: 这个连接类型对前面的表中的每一个记录联合进行完全扫描(比ALL更好,因为索引一般小于表数据)
ALL:这个连接类型对于前面的每一个记录联合进行完全扫描,这一般比较糟糕,应该尽量避免
数据库中所有表是否有主键或者有唯一索引. 如何查询以数据库中是否所有表都有主键或者单一索引
每张表理论中都有一个主键值ID,也可以作为索引,
使用T-SQL语句创建SQL Server索引的语法:
INDEX index_name
ON table_name (column_name…)
1、UNIQUE表示唯一索引,可选
2、肢搭CLUSTERED、NONCLUSTERED表示聚集索引还是历喊拿非聚集索引,可选
mysql如何查询表有有没有创建索引
1.索引作用 在索引列上,除了上面提到的有序查找之外,数据库利用各种各样的快速定位技术,能够大大提高查询效率。特别是当数据量非常顷唤大晌乎轿,查询涉及多宴肆个表时
show index from 表正知知名猛毕;
desc 表举消名
查看数据库表索引是否存在的介绍就聊到这里吧,感谢你花时间阅读本站内容,更多关于查看数据库表索引是否存在,检查数据库表索引是否存在,如何检查mysql中建立的索引是否生效的检测,数据库中所有表是否有主键或者有唯一索引. 如何查询以数据库中是否所有表都有主键或者单一索引,mysql如何查询表有有没有创建索引的信息别忘了在本站进行查找喔。
香港服务器首选树叶云,2H2G首月10元开通。树叶云(www.IDC.Net)提供简单好用,价格厚道的香港/美国云 服务器 和独立服务器。IDC+ISP+ICP资质。ARIN和APNIC会员。成熟技术团队15年行业经验。
SQL server中 表中如何创建索引?
if exists(select *from where naem = newindex) drop index newindex create index --=================================== 竟然没有悬赏...唉... 那算了吧 我还是都告诉你吧.. 看个示例 自己琢磨去: --============================================== use master go if db_id(Nzhangxu)is not null drop database zhangxu go create database zhangxu sp_helpdb zhangxu use zhangxu go IF EXISTS (SELECT *FROM WHERE NAME = NWORKER) DROP TABLE WORKER GO create table worker (w_id int identity (1000,1) not null,w_name Nvarchar(10) unique,w_age SMALLINT CONSTRAINT CK_W_AGE CHECK(w_age>20 and w_age<150),w_pay money DEFAULT 0,CONSTRAINT PK_W_ID PRIMARY KEY(W_ID) ) SELECT *FROM WORKER--用查询技术查看表信息 sp_help worker--利用存储过程查看表信息 /* 创建简单的非聚集索引 */ USE ZHANGXU GO if exists(select name from where name = NIX_ID_NAME) DROP INDEX IX_ID_NAME on worker go--检查是否存在索引,有则删除索引 create index IX_ID_NAME--创建索引 on worker(w_id,w_name)--在ID NAME 两个字段上创建非聚集索引 drop index _ID_NAME--删除索引 select *from where name = IX_ID_NAME--查看索引 /* 创建唯一非聚集索引 */ USE ZHANGXU GO IF EXISTS(SELECT NAME FROM WHERE NAME = NIX_W_NAME) DROP INDEX IX_W_NAME ON WORKER GO CREATE UNIQUE INDEX IX_W_NAME--唯一非聚集索引 ON WORKER(W_NAME) /* 查看索引T-SQL脚本 */ --IX_W_NAME 唯一 非聚集索引 USE [zhangxu] GO /****** 对象: Index [IX_W_NAME] 脚本日期: 07/29/2007 16:54:53 ******/ CREATE UNIQUE NONCLUSTERED INDEX [IX_W_NAME] ON [dbo].[worker] ([w_name] ASC ) WITH ( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF ) ON [PRIMARY] --PK_W_ID聚集索引 USE [zhangxu] GO /****** 对象: Index [PK_W_ID] 脚本日期: 07/29/2007 16:56:45 ******/ ALTER TABLE [dbo].[worker] ADD CONSTRAINT [PK_W_ID] PRIMARY KEY CLUSTERED ([w_id] ASC ) WITH ( SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF ) ON [PRIMARY] --UQ_WORKER 唯一,非聚集索引 USE [zhangxu] GO /****** 对象: Index [UQ__worker__F21] 脚本日期: 07/29/2007 16:58:38 ******/ ALTER TABLE [dbo].[worker] ADD UNIQUE NONCLUSTERED ([w_name] ASC ) WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF ) ON [PRIMARY] select *from worker insert into worker(w_name,w_age,w_pay) values(王国龙,25,4500)
sql-2000中的索引是什么意思?
可以利用索引快速访问数据库表中的特定信息。 索引是对数据库表中一个或多个列(例如,employee 表的姓氏 (lname) 列)的值进行排序的结构。 如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。 索引提供指针以指向存储在表中指定列的数据值,然后根据指定的排序次序排列这些指针。 数据库使用索引的方式与使用书的目录很相似:通过搜索索引找到特定的值,然后跟随指针到达包含该值的行。 在数据库关系图中,可以为选定的表创建、编辑或删除索引/键属性页中的每个索引类型。 当保存附加在此索引上的表或包含此表的数据库关系图时,索引同时被保存。 有关详细信息,请参见创建索引。 通常情况下,只有当经常查询索引列中的数据时,才需要在表上创建索引。 索引将占用磁盘空间,并且降低添加、删除和更新行的速度。 不过在多数情况下,索引所带来的数据检索速度的优势大大超过它的不足之处。 然而,如果应用程序非常频繁地更新数据,或磁盘空间有限,那么最好限制索引的数量。 1.确定数据表的操作是大量的查询还是大量的增删操作,以此确定使用索引的数目,较多增删操作应严格限制索引数目,如果是较多查询可以适当增加索引数目。 2.尝试建立索引来帮助查询。 检查自己的SQL语句,为在WHERE子句中出现的字段建立索引。 使查询引擎快速的定位到指定条件。 3.尝试建立一些复合索引来进一步提高系统性能(修改复合索引将消耗更多的时间,且占磁盘空间)4.对小型表(记录少)建立索引可能反而影响性能,因为此时对表扫描操作效率更高。 (查询优化器不能智能处理)5.避免对具有较少值的字段建立索引(如性别)6.避免选择具有大型数据类型的列作为索引。
alter index语句如何使用?
alter index常用的语法如下:(1)重建指定索引:ALTER INDEX ind ON TAREBUILD;(2)重建全部索引:ALTER INDEX ALL ON TAREBUILD;(3)禁用索引:ALTER INDEX ALL ON TADISABLE;(再次启用使用REBUILD重建而不是ENABLED)(4)指定参数重建索引:ALTER INDEX ALL ON TAREBUILD WITH(FILLFACTOR=80);(5)指定参数修改索引:ALTER INDEX ALL ON TASET(IGNORE_DUP_KEY = ON);注意:alter index语法,不能用于修改索引定义,如添加或删除列,或更改列的顺序AlterAlter是数据库SQL语言的修改语句,可以用来修改基本表,其一般表示格式为:ALTER TABLE<表名>[改变方式]基本介绍数据库SQL语言的修改语句,可以用来修改基本表,其一般表示格式为:ALTER TABLE<表名>[改变方式]改变方式:· 加一个栏位: ADD 栏位 1 栏位 1 资料种类· 删去一个栏位: DROP 栏位 1· 改变栏位名称: CHANGE 原本栏位名 新栏位名 新栏位名资料种类· 改变栏位的资料种类: MODIFY 栏位 1 新资料种类修改方式由上可以看出,修改基本表提供如下四种修改方式:(1)ADD方式:用于增加新列和完整性约束,列的定义方式同CREARE TABLE语句中的列定义方式相同,其语法格式:ALTER TABLE <表名> ADD <列定义>|<完整性约束>。 由于使用此方式中增加的新列自动填充NULL值,所以不能为增加的新列指定NOT NULL约束。 (2)DROP方式:用于删除指定的完整性约束条件,或删指定的列,其语法格式为:ALTER TABLE<表名> DROP [<完整性约束名>]ALTER TABLE<表名> DROP COLUMN <列名>注释:某些数据库系统不允许这种在数据库表中删除列的方式 (DROP COLUMN <列名>)。 (3)CHANGE方式,用于修改某些列,其语法格式:ALTER TABLE [表名] CHANGE <原列名> TO <新列名><新列的数据类型>(4)MODIFY方式,用于修改某些列的数据类型,其语法格式:ALTER TABLE [表名] MODIFY [列名] [数据类型]













发表评论