
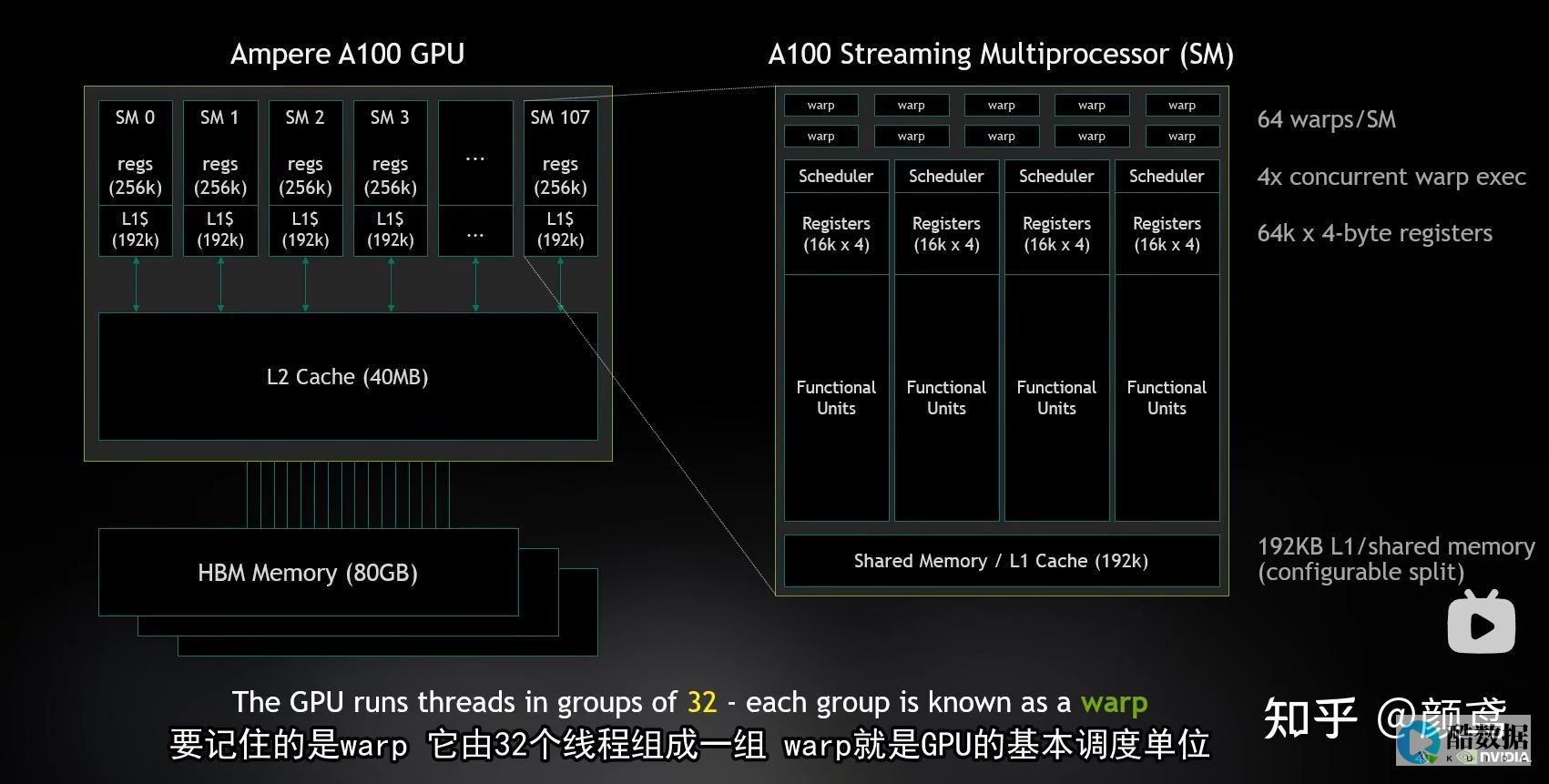

随着数据量的爆炸式增长和机器学习算法的复杂化,GPU服务器成为处理大规模数据和训练深度学习模型的理想选择。下面将详细介绍如何通过优化策略实现在GPU服务器上的高效数据挖掘和机器学习。
1.算法选择与优化
选择合适的算法是实现高效数据挖掘和机器学习的第一步。在GPU上,能够并行化处理的算法尤为重要,如随机森林、支持向量机和深度神经网络等。优化算法通常包括以下几个方面:
2.数据处理流程优化
数据处理在数据挖掘和机器学习中占据重要地位,特别是对大规模数据的预处理和特征工程。以下是优化数据处理流程的关键策略:
3.硬件配置与性能调优
选择适当的GPU服务器和优化硬件配置是保证高效数据挖掘和机器学习的关键因素:
结语
通过上述优化策略,可以显著提高在GPU服务器上进行数据挖掘和机器学习的效率和性能。选择合适的算法并进行并行化优化、优化数据处理流程、以及调整硬件配置和系统设置,将有助于充分利用GPU并行计算能力,加速模型训练和数据分析过程,从而在竞争激烈的数据科学领域取得更好的成果。
好主机测评广告位招租-300元/3月如何让Hadoop结合R语言做大数据分析
R语言和Hadoop让我们体会到了,两种技术在各自领域的强大。 很多开发人员在计算机的角度,都会提出下面2个问题。 问题1: Hadoop的家族如此之强大,为什么还要结合R语言?问题2: Mahout同样可以做数据挖掘和机器学习,和R语言的区别是什么?下面我尝试着做一个解答:问题1: Hadoop的家族如此之强大,为什么还要结合R语言?a. Hadoop家族的强大之处,在于对大数据的处理,让原来的不可能(TB,PB数据量计算),成为了可能。 b. R语言的强大之处,在于统计分析,在没有Hadoop之前,我们对于大数据的处理,要取样本,假设检验,做回归,长久以来R语言都是统计学家专属的工具。 c. 从a和b两点,我们可以看出,hadoop重点是全量数据分析,而R语言重点是样本数据分析。 两种技术放在一起,刚好是最长补短!d. 模拟场景:对1PB的新闻网站访问日志做分析,预测未来流量变化d1:用R语言,通过分析少量数据,对业务目标建回归建模,并定义指标d2:用Hadoop从海量日志数据中,提取指标数据d3:用R语言模型,对指标数据进行测试和调优d4:用Hadoop分步式算法,重写R语言的模型,部署上线这个场景中,R和Hadoop分别都起着非常重要的作用。 以计算机开发人员的思路,所有有事情都用Hadoop去做,没有数据建模和证明,”预测的结果”一定是有问题的。 以统计人员的思路,所有的事情都用R去做,以抽样方式,得到的“预测的结果”也一定是有问题的。 所以让二者结合,是产界业的必然的导向,也是产界业和学术界的交集,同时也为交叉学科的人才提供了无限广阔的想象空间。 问题2: Mahout同样可以做数据挖掘和机器学习,和R语言的区别是什么?a. Mahout是基于Hadoop的数据挖掘和机器学习的算法框架,Mahout的重点同样是解决大数据的计算的问题。 b. Mahout目前已支持的算法包括,协同过滤,推荐算法,聚类算法,分类算法,LDA, 朴素bayes,随机森林。 上面的算法中,大部分都是距离的算法,可以通过矩阵分解后,充分利用MapReduce的并行计算框架,高效地完成计算任务。 c. Mahout的空白点,还有很多的数据挖掘算法,很难实现MapReduce并行化。 Mahout的现有模型,都是通用模型,直接用到的项目中,计算结果只会比随机结果好一点点。 Mahout二次开发,要求有深厚的JAVA和Hadoop的技术基础,最好兼有 “线性代数”,“概率统计”,“算法导论” 等的基础知识。 所以想玩转Mahout真的不是一件容易的事情。 d. R语言同样提供了Mahout支持的约大多数算法(除专有算法),并且还支持大量的Mahout不支持的算法,算法的增长速度比mahout快N倍。 并且开发简单,参数配置灵活,对小型数据集运算速度非常快。 虽然,Mahout同样可以做数据挖掘和机器学习,但是和R语言的擅长领域并不重合。 集百家之长,在适合的领域选择合适的技术,才能真正地“保质保量”做软件。 如何让Hadoop结合R语言?从上一节我们看到,Hadoop和R语言是可以互补的,但所介绍的场景都是Hadoop和R语言的分别处理各自的数据。 一旦市场有需求,自然会有商家填补这个空白。 1). RHadoopRHadoop是一款Hadoop和R语言的结合的产品,由RevolutionAnalytics公司开发,并将代码开源到github社区上面。 RHadoop包含三个R包 (rmr,rhdfs,rhbase),分别是对应Hadoop系统架构中的,MapReduce, HDFS, HBase 三个部分。 2). RHiveRHive是一款通过R语言直接访问Hive的工具包,是由NexR一个韩国公司研发的。 3). 重写Mahout用R语言重写Mahout的实现也是一种结合的思路,我也做过相关的尝试。 4)调用R上面说的都是R如何调用Hadoop,当然我们也可以反相操作,打通JAVA和R的连接通道,让Hadoop调用R的函数。 但是,这部分还没有商家做出成形的产品。 5. R和Hadoop在实际中的案例R和Hadoop的结合,技术门槛还是有点高的。 对于一个人来说,不仅要掌握Linux, Java, Hadoop, R的技术,还要具备 软件开发,算法,概率统计,线性代数,数据可视化,行业背景 的一些基本素质。 在公司部署这套环境,同样需要多个部门,多种人才的的配合。 Hadoop运维,Hadoop算法研发,R语言建模,R语言MapReduce化,软件开发,测试等等。 所以,这样的案例并不太多。
机器学习在数据挖掘中的应用
数据挖掘 本身就是一个很宽泛的概念。 它包含的内涵和外延都很宽泛。 机器学习,是数据挖掘中的一个很小的部分。 建议你还是确定,你在数据挖掘流程中的位置,学习对应的内容。 逐渐成长!
hadoop开发和数据挖掘选哪个好
1、SparkVSHadoop有哪些异同点?Hadoop:分布式批处理计算,强调批处理,常用于数据挖掘、分析Spark:是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速,Spark是一种与Hadoop相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使Spark在某些工作负载方面表现得更加优越,换句话说,Spark启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。 Spark是在Scala语言中实现的,它将Scala用作其应用程序框架。 与Hadoop不同,Spark和Scala能够紧密集成,其中的Scala可以像操作本地集合对象一样轻松地操作分布式数据集。 尽管创建Spark是为了支持分布式数据集上的迭代作业,但是实际上它是对Hadoop的补充,可以在Hadoop文件系统中并行运行。 通过名为Mesos的第三方集群框架可以支持此行为。 Spark由加州大学伯克利分校AMP实验室(Algorithms,Machines,andPeopleLab)开发,可用来构建大型的、低延迟的数据分析应用程序。 虽然Spark与Hadoop有相似之处,但它提供了具有有用差异的一个新的集群计算框架。 首先,Spark是为集群计算中的特定类型的工作负载而设计,即那些在并行操作之间重用工作数据集(比如机器学习算法)的工作负载。 为了优化这些类型的工作负载,Spark引进了内存集群计算的概念,可在内存集群计算中将数据集缓存在内存中,以缩短访问延迟.在大数据处理方面相信大家对hadoop已经耳熟能详,基于GoogleMap/Reduce来实现的Hadoop为开发者提供了map、reduce原语,使并行批处理程序变得非常地简单和优美。 Spark提供的数据集操作类型有很多种,不像Hadoop只提供了Map和Reduce两种操作。 比如map,filter,flatMap,sample,groupByKEY,reduceByKey,union,join,cogroup,mapValues,sort,partionBy等多种操作类型,他们把这些操作称为Transformations。 同时还提供Count,collect,reduce,lookup,save等多种actions。 这些多种多样的数据集操作类型,给上层应用者提供了方便。 各个处理节点之间的通信模型不再像Hadoop那样就是唯一的DataShuffle一种模式。 用户可以命名,物化,控制中间结果的分区等。 可以说编程模型比Hadoop更灵活.2、Spark在容错性方面是否比其他工具更有优越性?从Spark的论文《ResilientDistributedDatasets:AFault-TolerantAbstractionforIn-MemoryClusterComputing》中没看出容错性做的有多好。 倒是提到了分布式数据集计算,做checkpoint的两种方式,一个是checkpointdata,一个是loggingtheupdates。 貌似Spark采用了后者。 但是文中后来又提到,虽然后者看似节省存储空间。 但是由于数据处理模型是类似DAG的操作过程,由于图中的某个节点出错,由于lineagechains的依赖复杂性,可能会引起全部计算节点的重新计算,这样成本也不低。 他们后来说,是存数据,还是存更新日志,做checkpoint还是由用户说了算吧。 相当于什么都没说,又把这个皮球踢给了用户。 所以我看就是由用户根据业务类型,衡量是存储数据IO和磁盘空间的代价和重新计算的代价,选择代价较小的一种策略。 取代给中间结果进行持久化或建立检查点,Spark会记住产生某些数据集的操作序列。 因此,当一个节点出现故障时,Spark会根据存储信息重新构造数据集。 他们认为这样也不错,因为其他节点将会帮助重建。 3、Spark对于数据处理能力和效率有哪些特色?Spark提供了高的性能和大数据处理能力,使得用户可以快速得到反馈体验更好。 另一类应用是做数据挖掘,因为Spark充分利用内存进行缓存,利用DAG消除不必要的步骤,所以比较合适做迭代式的运算。 而有相当一部分机器学习算法是通过多次迭代收敛的算法,所以适合用Spark来实现。 我们把一些常用的算法并行化用Spark实现,可以从R语言中方便地调用,降低了用户进行数据挖掘的学习成本。 Spark配有一个流数据处理模型,与Twitter的Storm框架相比,Spark采用了一种有趣而且独特的法。 Storm基本上是像是放入独立事务的管道,在其中事务会得到分布式的处理。 相反,Spark采用一个模型收集事务,然后在短时间内(我们假设是5秒)以批处理的方式处理事件。 所收集的数据成为他们自己的RDD,然后使用Spark应用程序中常用的一组进行处理。 作者声称这种模式是在缓慢节点和故障情况下会更加稳健,而且5秒的时间间隔通常对于大多数应用已经足够快了。 这种方法也很好地统一了流式处理与非流式处理部分。 总结这几天在看Hadoop权威指南、hbase权威指南、hive权威指南、大规模分布式存储系统、zoopkeeper、大数据互联网大规模数据挖掘与分布式处理等书同时补充,能静下心来好好的完整的看完一本书,是相当不错的。












发表评论