
深度解读基于Ceph对象存储的混合云机制
2018-04-08 08:25:15毫无疑问,乘着云计算发展的东风,Ceph已经是当今最火热的软件定义存储开源项目。如下图所示,它在同一底层平台之上可以对外提供三种存储接口,分别是文件存储、对象存储以及块存储,本文主要关注的是对象存储即radosgw。
1.背景
毫无疑问,乘着云计算发展的东风,Ceph已经是当今最火热的软件定义存储开源项目。如下图所示,它在同一底层平台之上可以对外提供三种存储接口,分别是文件存储、对象存储以及块存储,本文主要关注的是对象存储即radosgw。
基于Ceph可方便快捷地搭建安全性好、可用性高、扩展性好的私有化存储平台。私有化存储平台虽然以其安全性的优势受到越来越多的关注,但私有化存储平台也存在诸多弊端。 例如在如下场景中,某跨国公司需要在国外访问本地的业务数据,我们该如何支持这种远距离的数据访问需求呢。如果仅仅是在私有化环境下,无非以下两种解决方案:
在国外自建数据中心,不断将本地的数据异步复制到远程数据中心,这种解决方案的缺点是成本太高
在这种场景下,单纯的私有云存储平台并不能很好的解决的上面的问题。但是,通过采用混合云解决方案却能较好地满足上述需求。对于前文所述远距离数据访问的场景,我们完全能借助公有云在远程的数据中心节点作为存储点,将本地数据中心的数据异步复制到公有云,再通过终端直接访问公有云中的数据,这种方式在综合成本和快捷性方面具备较大优势,适合这种远距离的数据访问需求。
2.发展现状:RGW Cloud Sync发展历程
基于Ceph对象存储的混合云机制是对Ceph生态的良好补充, 基于此,社区将在Mimic这个版本上发布RGW Cloud Sync特性,初步支持将RGW中的数据导出到支持s3协议的公有云对象存储平台,比如我们测试中使用的腾讯云COS,同Mulsite中的其他插件一样,RGW Cloud Sync这个特性也是做成了一个全新的同步插件(目前称之为aws sync module),能兼容支持S3协议。RGW Cloud Sync特性的整体发展历程如下:
对于Ceph社区即将在M版本发布的这个公有云同步特性,进行了实际落地测试使用,并根据其中存在的问题进行了反馈及开发。在实际测试过程中,我们搭建了如下所示的运行环境:
其中,Cloud Zone内部包含一个公有云同步插件,它被配置为只读zone,用以将Rgw Zone中写入的数据跨地域同步至腾讯云公有云对象存储平台COS之上。顺利实现将数据从RGW中同步备份至公有云平台,并且支持自由定制来实现将数据导入至不同云端路径,同时我们还完善了同步状态显示功能,能较快监测到同步过程中发生的错误以及当前落后的数据等。
3.核心机制
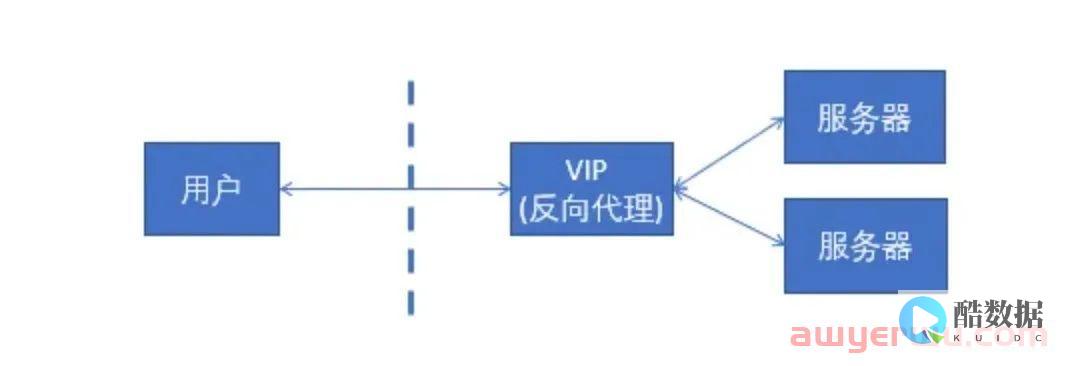
RGW Cloud Sync这个特性本质上是基于Multisite之上的一个全新的同步插件(aws sync module)。首先来看Multisite的一些核心机制。Multisite是RGW中数据远程备份的一种解决方案,本质上来说它是一种基于日志的异步复制策略,下图为一个Multisite的示意图。
Multisite中主要有以下基本概念:
下面来看Multisite中的一些工作机制,分别是Data Sync、Async Framework、Sync Plugin这三部分。其中Data Sync部分主要分析Multisite中的数据同步流程,Async Framework部分会介绍Multisite中的协程框架,Sync Plugin部分会介绍Multisite中的一些同步插件。
Data Sync用以将一个Zonegroup内的数据进行备份,一个Zone内写入的数据会最终同步到Zonegroup内所有Zone上,一个完整的Data Sync流程包含如下三步:
下面以一个bucket中数据的增量同步来阐述Data Sync的工作机制。了解RGW的人都应该知道,一个bucket实例至少包含一个bucket shard,Data Sync是以bucket shard为单位来同步的,每个bucket shard有一个datalog shard 及bilog shard与之对应。
在建立完对应关系及进行完全量同步之后,本地Zone会记录Sourcezone每个datalog 分片对应的sync_marker。此后local zone会定期将sync_marker与远程datalog的max_marker比对,若仍有数据未同步,则通过rgw消费datalog entry,datalog entry中记录了对应的bucket shard,消费bucket shard对应的bilog则可进行数据同步。如下面这个图所示,远程的datalog是以 gw_data_chang_log_entry这样一种格式来存储日志的,我们可发现,每条datalog entry中包含rgw_data_change这样一个域,而rgw_data_change中包括的key这个域则是bucket shard的名字,之后就可以找到与之对应的bilog shard,从而消费bilog来进行增量同步。而全量同步其实就是没有开始这个sync_marker,直接从头开始消费datalog来进行数据同步。
Async Framework
RGW中使用的异步执行框架是基于boost::asio::coRoutine这个库来开发的,它是一个stackless coroutine,和常见的协程技术不同,Async Framework没有使用ucontext技术来保存当前堆栈信息来支持协程,而是使用宏的技巧来达到类似效果,它通过 reenter/yield/fork 几个伪关键字(宏)来实现协程。 RGWCoroutine是RGW中定义的关于协程的抽象类,它本身也是boost::asio::coroutine 的子类,它是用于描述一个任务流的,包含一个待实现的隐式状态机。RGWCoroutine可以call其他RGWCoroutine,也可以spawn一个并行的RGWCoroutine。
RGWCoroutine 类会包含一个 RGWCoroutinesStack成员,使用call调用其他RGWCoroutine的时候会将其对应的任务流都存储在堆栈上,直到所有任务流完成之后控制权才会回到调用者处。然而,spawn一个新的RGWCoroutine时候会生成一个新的任务栈来存储任务流,它不会阻塞当前正在执行的任务流。当一个协程需要执行一个异步IO操作的时候,它会标记自身为阻塞状态,而这个IO事件会在任务管理器处注册,一旦IO完成后任务管理器会解锁当前堆栈,从而恢复这个协程的控制。下图为一个简单的协程使用例子,实现了一个有预定周期的请求处理器。
Sync Plugin
前文所述的数据同步过程是将数据从一个ceph zone同步到另一ceph zone,我们完全可以将过程抽象出来,使数据同步变得更加通用,方便添加不同的sync module来实现将数据迁移到不同的目的地。因为上层消费datalog的逻辑都是一致的,只有***一步上层数据到目的地这步是不一样的,因此我们只需实现数据同步和删除的相关接口就可实现不同的同步插件,每个插件在RGW中都被称为一个sync module,目前Ceph中有以下四个sync module:
RGW Cloud Sync
Streaming process
前文讲到Suse公司贡献了RGW Cloud Sync的初始版本,如下图所示,它的一个同步流程逻辑上来说主要分为三步,***通过aws sync module通过http Connection将远程的object拉取过来装载至内存中,之后将这个object put到云端,之后云端会返回一个put result。

对于小文件来说,这个流程是没问题的,但是如果这个object比较大的情况,全部load到内存中就有问题了,因此Red Hat在此基础之上支持了Streaming process。本质上是使用了一个新的协程,这里称之为pipe CR,它采用类似管道的机制,同时保持两个http connection,一个用于拉取远程object,一个用于上传object,且这两个过程是并行的,这样可以有效防止内存爆炸,具体如下图所示。
Multipart upload
Multipart upload是在Streaming process基础之上用以支持大文件的分片上传。它的整体流程如下:
Json config
公有云存储环境相对来说比较复杂,需要更加复杂的配置来支持aws sync module的使用,因此Red Hat在这个插件上支持了json config。
相对其他插件来说主要增加了三个配置项,分别是host_style, acl_mapping,target_path,其中host_style是配置域名的使用格式,acl_mapping 是配置acl信息的同步方式,target_path是配置元数据在目的处的存放点。如下图所示为一个实际使用的配置,它表示配置了aws zone,采用path-style这种域名格式,target_path是rgw加其所在zonegroup的名字并加上它的user_id,之后是它的bucket名字,最终这个object在云端的路径就是target_path加上object名字。
关于RGW Cloud Sync方面的后续工作主要有以下四项:
SQL server 2000 和 2005有什么区别?
数据库管理10个最重要的特点特点 描述数据库镜像通过新数据库镜像方法,将记录档案传送性能进行延伸。 您将可以使用数据库镜像,通过将自动失效转移建立到一个待用服务器上,增强您SQL服务器系统的可用性。 在线恢复使用SQL2005版服务器,数据库管理人员将可以在SQL服务器运行的情况下,执行恢复操作。 在线恢复改进了SQL服务器的可用性,因为只有正在被恢复的数据是无法使用的,而数据库的其他部分依然在线、可供使用。 在线检索操作在线检索选项可以在指数数据定义语言(DDL)执行期间,允许对基底表格、或集簇索引数据和任何有关的检索,进行同步修正。 例如,当一个集簇索引正在重建的时候,您可以对基底数据继续进行更新、并且对数据进行查询。 快速恢复新的、速度更快的恢复选项可以改进SQL服务器数据库的可用性。 管理人员将能够在事务日志向前滚动之后,重新连接到正在恢复的数据库。 安全性能的提高SQL Server 2005包括了一些在安全性能上的改进,例如数据库加密、设置安全默认值、增强密码政策、缜密的许可控制、以及一个增强型的安全模式。 新的SQL Server Management StudioSQL Server 2005引入了SQL Server Management Studio,这是一个新型的统一的管理工具组。 这个工具组将包括一些新的功能,以开发、配置SQL Server数据库,发现并修理其中的故障,同时这个工具组还对从前的功能进行了一些改进。 专门的管理员连接SQL Server 2005将引进一个专门的管理员连接,即使在一个服务器被锁住,或者因为其他原因不能使用的时候,管理员可以通过这个连接,接通这个正在运行的服务器。 这一功能将能让管理员,通过操作诊断功能、或Transact—SQL指令,找到并解决发现的问题。 快照隔离我们将在数据库层面上提供一个新的快照隔离(SI)标准。 通过快照隔离,使用者将能够使用与传统一致的视野观看数据库,存取最后执行的一行数据。 这一功能将为服务器提供更大的可升级性。 数据分割数据分割 将加强本地表检索分割,这使得大型表和索引可以得到高效的管理。 增强复制功能对于分布式数据库而言,SQL Server 2005提供了全面的方案修改(DDL)复制、下一代监控性能、从甲骨文(Oracle)到SQL Server的内置复制功能、对多个超文本传输协议(http)进行合并复制,以及就合并复制的可升级性和运行,进行了重大的改良。 另外,新的对等交易式复制性能,通过使用复制,改进了其对数据向外扩展的支持。 有关开发的10个最重要的特点特点 描述 框架主机使用SQL Server 2005,开发人员通过使用相似的语言,例如微软的Visual C# 和微软的Visual Basic,将能够创立数据库对象。 开发人员还将能够建立两个新的对象——用户定义的类和集合。 XML 技术在使用本地网络和互联网的情况下,在不同应用软件之间散步数据的时候,可扩展标记语言(XML)是一个重要的标准。 SQL Server 2005将会自身支持存储和查询可扩展标记语言文件。 2.0 版本从对SQL类的新的支持,到多活动结果集(MARS),SQL Server 2005中的将推动数据集的存取和操纵,实现更大的可升级性和灵活性。 增强的安全性SQL Server 2005中的新安全模式将用户和对象分开,提供fine-grain access存取、并允许对数据存取进行更大的控制。 另外,所有系统表格将作为视图得到实施,对数据库系统对象进行了更大程度的控制。 Transact-SQL 的增强性能SQL Server 2005为开发可升级的数据库应用软件,提供了新的语言功能。 这些增强的性能包括处理错误、递归查询功能、关系运算符PIVOT, APPLY, ROW_NUMBER和其他数据列排行功能,等等。 SQL 服务中介SQL服务中介将为大型、营业范围内的应用软件,提供一个分布式的、异步应用框架。 通告服务通告服务使得业务可以建立丰富的通知应用软件,向任何设备,提供个人化的和及时的信息,例如股市警报、新闻订阅、包裹递送警报、航空公司票价等。 在SQL Server 2005中,通告服务和其他技术更加紧密地融合在了一起,这些技术包括分析服务、SQL Server Management Studio。 Web服务使用SQL Server 2005,开发人员将能够在数据库层开发Web服务,将SQL Server当作一个超文本传输协议(HTTP)侦听器,并且为网络服务中心应用软件提供一个新型的数据存取功能。 报表服务利用SQL Server 2005, 报表服务可以提供报表控制,可以通过Visual Studio 2005发行。 全文搜索功能的增强SQL SERVER 2005将支持丰富的全文应用软件。 服务器的编目功能将得到增强,对编目的对象提供更大的灵活性。 查询性能和可升级性将大幅得到改进,同时新的管理工具将为有关全文功能的运行,提供更深入的了解。 有关商业智能特征的10个最重要的特点特点 描述分析服务SQL SERVER 2005的分析服务迈入了实时分析的领域。 从对可升级性性能的增强、到与微软Office软件的深度融合,SQL SERVER 2005将帮助您,将商业智能扩展到您业务的每一个层次。 数据传输服务(DTS)DTS数据传输服务是一套绘图工具和可编程的对象,您可以用这些工具和对象,对从截然不同来源而来的数据进行摘录、传输和加载(ETL),同时将其转送到单独或多个目的地。 SQL SERVER 2005将引进一个完整的、数据传输服务的、重新设计方案,这一方案为用户提供了一个全面的摘录、传输和加载平台。 数据挖掘我们将引进四个新的数据挖掘运算法,改进的工具和精灵,它们会使数据挖掘,对于任何规模的企业来说,都变得简单起来。 报表服务在SQL SERVER 2005中,报表服务将为在线分析处理(OLAP)环境提供自我服务、创建最终用户特别报告、增强查询方面的开发水平,并为丰富和便于维护企业汇报环境,就允许升级方面,提供增进的性能。 集群支持通过支持容错技术移转丛集、增强对多重执行个体的支持、以及支持备份和恢复分析服务对象和数据,分析服务改进了其可用性。 主要运行指标主要运行指标(KPIs)为企业提供了新的功能,使其可以定义图表化的、和可定制化的商业衡量标准,以帮助公司制定和跟踪主要的业务基准。 可伸缩性和性能并行分割处理,创建远程关系在线分析处理(ROLAP)或混合在线分析处理(HOLAP)分割,分布式分割单元,持续计算,和预制缓存等特性,极大地提升了SQL Server 2005中分析服务的可伸缩性和性能。 单击单元当在一个数据仓库中创建一个单元时,单元向导将包括一个可以单击单元检测和建议的操作。 预制缓存预制缓存将MOLAP等级查询运行与实时数据分析合并到一起,排除了维护在线分析处理存储的需要。 显而易见,预制缓存将数据的一个更新备份进行同步操作,并对其进行维护,而这些数据是专门为高速查询而组织的、它们将最终用户从超载的相关数据库分离了出来。 与Microsoft Office System集成在报表服务中,由报表服务器提供的报表能够在Microsoft SharePoint门户服务器和Microsoft Office System应用软件的环境中运行,Office System应用软件其中包括Microsoft Word和Microsoft Excel。 您可以使用SharePoint功能,订阅报表、建立新版本的报表,以及分发报表。 您还能够在Word或Excel软件中打开报表,观看超文本连接标示语言(HTML)版本的报表。
虚拟化技术是什么?是否可以通过虚拟化技术来实现软件应用与底层硬件相隔离?
虚拟化技术。 通过虚拟化技术可实现软件应用与底层硬件相隔离,它包括将单个资源划分成多个虚拟资源的裂分模式,也包括将多个资源整合成一个虚拟资源的聚合模式。 根据不同的对象,虚拟化技术可分成存储虚拟化、计算虚拟化和网络虚拟化等,其中计算虚拟化又可分为系统级虚拟化、应用级虚拟化和桌面级虚拟化。
Map接口,Hashmap和HashTable的相同点和不同点分别是什么?
Hashtable和HashMap的区别是Dictionary的子类,HashMap是Map接口的一个实现类;中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。 即是说,在多线程应用程序中,不用专门的操作就安全地可以使用Hashtable了;而对于HashMap,则需要额外的同步机制。 但HashMap的同步问题可通过Collections的一个静态方法得到解决:Map (Map m)这个方法返回一个同步的Map,这个Map封装了底层的HashMap的所有方法,使得底层的HashMap即使是在多线程的环境中也是安全的。 3.在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。 当get()方法返回null值时,即可以表示HashMap中没有该键,也可以表示该键所对应的值为null。 因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键,而应该用conTainsKey()方法来判断。 Map├Hashtable├HashMap└WeakHashMapMap接口请注意,Map没有继承Collection接口,Map提供key到value的映射。 一个Map中不能包含相同的key,每个key只能映射一个value。 Map接口提供3种集合的视图,Map的内容可以被当作一组key集合,一组value集合,或者一组key-value映射。 Hashtable类Hashtable继承Map接口,实现一个key-value映射的哈希表。 任何非空(non-null)的对象都可作为key或者value。 添加数据使用put(key, value),取出数据使用get(key),这两个基本操作的时间开销为常数。 Hashtable通过initial capacity和load factor两个参数调整性能。 通常缺省的load factor0.75较好地实现了时间和空间的均衡。 增大load factor可以节省空间但相应的查找时间将增大,这会影响像get和put这样的操作。 使用Hashtable的简单示例如下,将1,2,3放到Hashtable中,他们的key分别是”one”,”two”,”three”:Hashtable numbers = new Hashtable();(“one”, new Integer(1));(“two”, new Integer(2));(“three”, new Integer(3));要取出一个数,比如2,用相应的key:Integer n = (Integer)(“two”);(“two = ” + n);由于作为key的对象将通过计算其散列函数来确定与之对应的value的位置,因此任何作为key的对象都必须实现hashCode和equals方法。 hashCode和equals方法继承自根类Object,如果你用自定义的类当作key的话,要相当小心,按照散列函数的定义,如果两个对象相同,即(obj2)=true,则它们的hashCode必须相同,但如果两个对象不同,则它们的hashCode不一定不同,如果两个不同对象的hashCode相同,这种现象称为冲突,冲突会导致操作哈希表的时间开销增大,所以尽量定义好的hashCode()方法,能加快哈希表的操作。 如果相同的对象有不同的hashCode,对哈希表的操作会出现意想不到的结果(期待的get方法返回null),要避免这种问题,只需要牢记一条:要同时复写equals方法和hashCode方法,而不要只写其中一个。 Hashtable是同步的。 HashMap类HashMap和Hashtable类似,不同之处在于HashMap是非同步的,并且允许null,即null value和nullkey。 ,但是将HashMap视为Collection时(values()方法可返回Collection),其迭代子操作时间开销和HashMap的容量成比例。 因此,如果迭代操作的性能相当重要的话,不要将HashMap的初始化容量设得过高,或者load factor过低。 WeakHashMap类WeakHashMap是一种改进的HashMap,它对key实行“弱引用”,如果一个key不再被外部所引用,那么该key可以被GC回收。










发表评论