
搜狗开源框架发布纯自研C++ Kafka客户端
2020-12-28 14:36:03一个fetch消息的任务由一组任务组成,其中包括获取Kafka Broker的Meta任务、一系列的消费者组相关的任务、获取offset的任务和真正的拉取消息的任务。
搜狗于今年7月发布了C++异步调度 服务器 引擎——Workflow,除了计算通信融为一体的高性能特点以外,还集成了多种常用的网络协议,包括:Http、Redis、MySQL,所有协议都是纯自研自解析,无需依赖第三方库,而具体协议所对应的资源复用和线程调度等都由Workflow以统一的方式去进行管理,目前获得了越来越多开发者的青睐和肯定。而最近,Workflow又支持并发布了一项复杂的通用网络协议:Kafka,使得所有使用Workflow及其生态项目的开发者都可以通过统一而简便的方式与Kafka交互,这也是业内唯一一款使用C++语言实现的Kafka客户端,值引得开源社区开发者们的关注。
一、开发背景
在Workflow发布Kafka客户端之前,业内用得比较多的是librdkafka,但这个纯C的kafka客户端有许多不足,以下是我们原先使用时遇到的部分问题:
1、线程资源和网络资源消耗比较多
2、接口设计比较复杂臃肿,使用成本比较高
3、Kafka版本兼容性不是很好
4、消耗资源高,但是性能却不高
5、broker主从切换低版本出现服务hang住情况,高版本偶发丢数据问题
6、异步同步偶发出现丢数据情况
针对这些问题,更好的替代方案是Workflow的Kafka客户端:
由于实现在Workflow的基础上,作为Kafka客户端即具有超高性能、超大吞吐和极省的资源占用等特点,且和其他协议的接口一样,此Kafka客户端还具有接口清晰,代码可读性强等优点,不仅节省机器成本还节省人力维护成本,非常值得一试。
二、新一代高性能C++ Kafka客户端
Workflow的Kafka客户端使用接口非常简洁,首先需要创建一个client对象:
其他使用方式与框架内的其他任务无异,使用Workflow的同学可以瞬间上手:
为什么Workflow的Kafka客户端能有以上的优点呢?主要得益于以下三方面的细节:
一. 内部基于Workflow的任务流实现。Workflow的核心设计理念是将任务抽象成”任务流”的概念,这样一个任意复杂的任务可以拆分成若干个并行任务流和串行任务流,它们之间通过串联、并联等方式组成一个或者多个串并联图,然后由Workflow内部的引擎高效异步地执行。

以Kafka协议的fetch消息为例,下图是执行过程中任务流的串并联图:
一个fetch消息的任务由一组任务组成,其中包括获取Kafka Broker的Meta任务、一系列的消费者组相关的任务、获取offset的任务和真正的拉取消息的任务。前面的多个任务由于有依赖关系,所以组成串联任务;而最终拉取消息的任务和Broker的个数有关,因此可以将它转换成一个broker数目相同的并行任务。这样做一方面可以使得逻辑很清晰,同时也可以保证执行的高效性。
二. 连接复用。传统的网络通信往往是在程序初始化的时候,创建大规模连接池来提高网络吞吐,这么做的一个弊端是系统资源占用过多,会导致降低程序的鲁棒性。而目前这个Kafka客户端由于内部是基于Workflow框架,Workflow对连接的管理做了很多优化,可以在保证高效高吞吐的同时,将资源控制在一个合理的范围内。
三.内存管理。为了方便用户的使用,内部的所有对象都基于计数实现,通过工厂方法创建任务后,在回调函数中实现处理逻辑即可。内存的分配和释放都是框架自动完成,全程无需手动操作任务级别的内存,非常方便;同时它的逻辑又是完备自洽的,保证了高效可靠。
三 、插件式发布,与Workflow完美融合
基于Workflow精巧的层次结构,Kafka协议是以插件式发布的,即无需安装Kafka的用户不会把Kafka相关代码编译进去,由此可以看出Workflow本身的架构解耦和模块对称性都做得非常优秀。
而Kafka的协议由于需要多次交互,Workflow复合任务又天生支持内部交互的隐藏,使得整体使用上对用户非常简洁透明。基于二级工厂模式也可以把许多全局信息统一管理到内存中,也是工程上结合的一大亮点。
可以说,Kafka协议与Workflow的融合相当完美,且目前在搜狗已经大规模使用,经得住工业级检索系统大规模请求的实际考验,欢迎业内需要的开发同学积极尝试并与我们热心的开发小组进行技术交流。
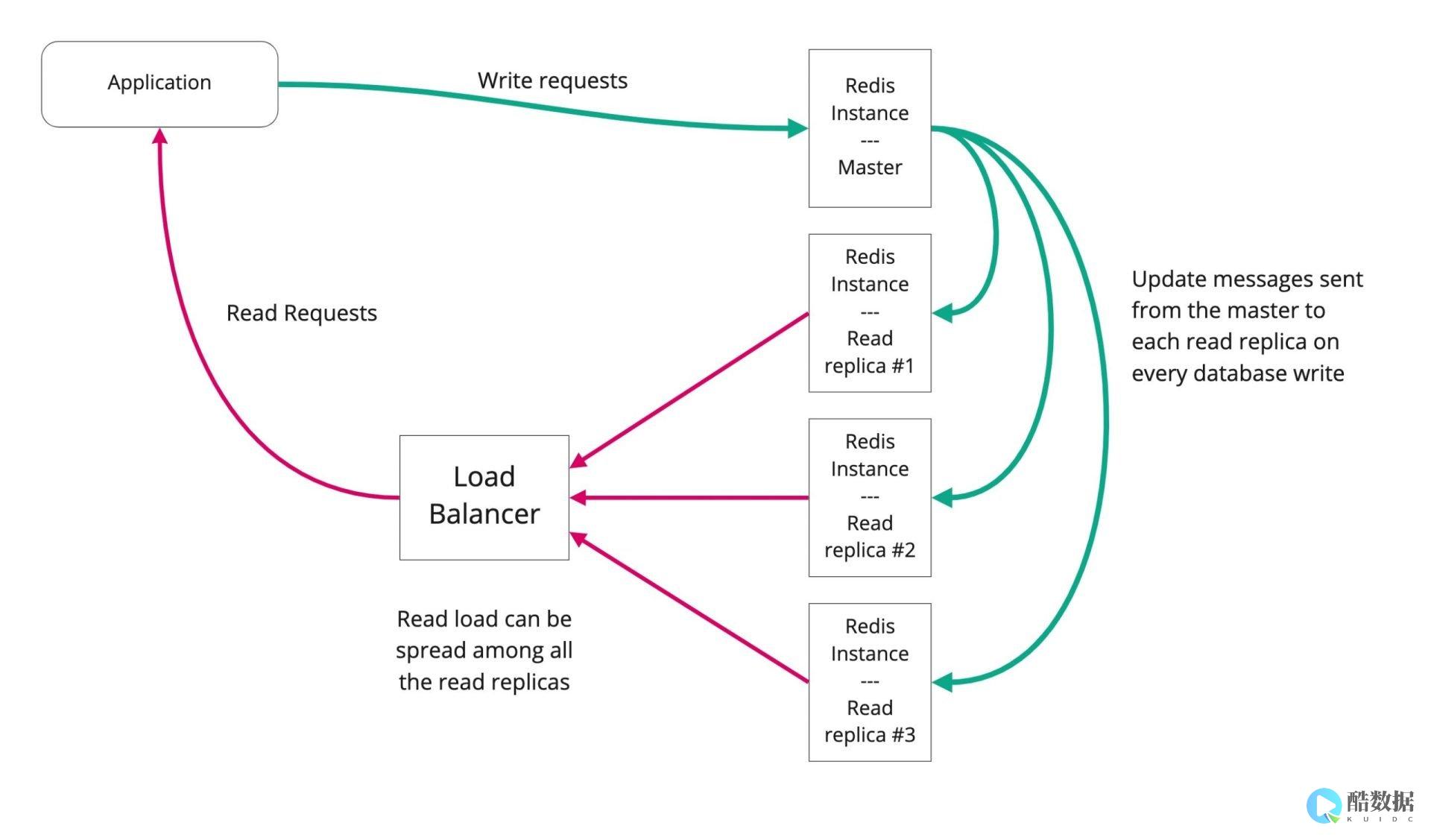
在大数据中心需要什么样的技术?
大数据是对海量数据进行存储、计算、统计、分析处理的一系列处理手段,处理的数据量通常是TB级,甚至是PB或EB级的数据,这是传统数据手段所无法完成的,其涉及的技术有分布式计算、高并发处理、高可用处理、集群、实时性计算等,汇集了当前IT领域热门流行的IT技术。 1. Java编程技术Java编程技术是大数据学习的基础,Java是一种强类型的语言,拥有极高的跨平台能力,可以编写桌面应用程序、Web应用程序、分布式系统和嵌入式系统应用程序等,是大数据工程师最喜欢的编程工具,因此,想学好大数据,掌握Java基础是必不可少的。 2. Linux命令对于大数据开发通常是在Linux环境下进行的,相比Linux操作系统,Windows操作系统是封闭的操作系统,开源的大数据软件很受限制,因此,想从事大数据开发相关工作,还需掌握Linux基础操作命令。 3. HadoopHadoop是大数据开发的重要框架,其核心是HDFS和MapReduce,HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算,因此,需要重点掌握,除此之外,还需要掌握Hadoop集群、Hadoop集群管理、YARN以及Hadoop高级管理等相关技术与操作!4. HiveHive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将sql语句转换为MapReduce任务运行,十分适合数据仓库的统计分析。 对于Hive需掌握其安装、应用及高级操作等。 5. Avro与ProtobufAvro与Protobuf均是数据序列化系统,可以提供丰富的数据结构类型,十分适合做数据存储,还可进行不同语言之间相互通信的数据交换格式,学习大数据,需掌握其具体用法。 6. ZooKeeperZooKeeper是Hadoop和Habase的重要组件,是一个分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组件服务等,在大数据开发中要掌握ZooKeeper的常用命令及功能的实现方法。 7. HBaseHBase是一个分布式的、面向列的开源数据库,他不同于一般的关系数据库,更适合于非结构化数据存储的数据库,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,大数据开发需掌握HBase基础知识、应用、架构以及高级用法等。 是用Java编写的基于JDBC API操作HBase的开源SQL引擎,其具有动态列、散列加载、查询服务器、追踪、事务、用户自定义函数、二级索引、命名空间映射、数据收集、行时间戳列、分页查询、跳跃查询、视图以及多租户的特性,大数据开发需掌握其原理和使用方法。 是一个key-value存储系统,其出现很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用,它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便,大数据开发需掌握Redis的安装、配置及相关使用方法。 是一款高可用、高可靠、分布式的海量日志采集、聚合和传输系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接收方(可定制)的能力。 大数据开发需掌握其安装、配置以及相关使用方法。 框架是由Spring、SpringMVC、MyBatis三个开源框架整合而成,常作为数据源较简单的web项目的框架。 大数据开发需分别掌握Spring、SpringMVC、MyBatis三种框架的同时,再使用SSM进行整合操作。 是一种高吞吐量的分布式发布订阅消息系统,其在大数据开发应用上的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。 大数据开发需掌握Kafka架构原理及各组件的作用和是用方法及相关功能的实现!是一门多范式的编程语言,大数据开发重要框架Spark是采用Scala语言设计的,想要学好Spark框架,拥有Scala基础是必不可少的,因此,大数据开发需掌握Scala编程基础知识!是专为大规模数据处理而设计的快速通用的计算引擎,其提供了一个全面、统一的框架用于管理各种不同性质的数据集和数据源的大数据处理的需求,大数据开发需掌握Spark基础、SparkJob、Spark RDD、sparkjob部署与资源分配、SparkshuffleSpark内存管理、Spark广播变量、SparkSQL SparkStreaming以及 Spark ML等相关知识。 是一个批量工作流任务调度器,可用于在一个工作流内以一个特定的顺序运行一组工作和流程,可以利用Azkaban来完成大数据的任务调度,大数据开发需掌握Azkaban的相关配置及语法规则。
大数据技术包括哪些
大数据技术包括数据收集、数据存取、基础架构、数据处理、统计分析、数据挖掘、模型预测、结果呈现。
1、数据收集:在大数据的生命周期中,数据采集处于第一个环节。 根据MapReduce产生数据的应用系统分类,大数据的采集主要有4种来源:管理信息系统、Web信息系统、物理信息系统、科学实验系统。
2、数据存取:大数据的存去采用不同的技术路线,大致可以分为3类。 第1类主要面对的是大规模的结构化数据。 第2类主要面对的是半结构化和非结构化数据。 第3类面对的是结构化和非结构化混合的大数据,
3、基础架构:云存储、分布式文件存储等。
4、数据处理:对于采集到的不同的数据集,可能存在不同的结构和模式,如文件、XML 树、关系表等,表现为数据的异构性。 对多个异构的数据集,需要做进一步集成处理或整合处理,将来自不同数据集的数据收集、整理、清洗、转换后,生成到一个新的数据集,为后续查询和分析处理提供统一的数据视图。
5、统计分析:假设检验、显著性检验、差异分析、相关分析、T检验、方差分析、卡方分析、偏相关分析、距离分析、回归分析、简单回归分析、多元回归分析、逐步回归、回归预测与残差分析、岭回归、logistic回归分析、曲线估计、因子分析、聚类分析、主成分分析、因子分析、快速聚类法与聚类法、判别分析、对应分析、多元对应分析(最优尺度分析)、Bootstrap技术等等。
6、数据挖掘:目前,还需要改进已有数据挖掘和机器学习技术;开发数据网络挖掘、特异群组挖掘、图挖掘等新型数据挖掘技术;突破基于对象的数据连接、相似性连接等大数据融合技术;突破用户兴趣分析、网络行为分析、情感语义分析等面向领域的大数据挖掘技术。
7、模型预测:预测模型、机器学习、建模仿真。
8、结果呈现:云计算、标签云、关系图等。
大数据工程师需要掌握哪些技术?
1. Java编程技术Java编程技术是大数据学习的基础,Java是一种强类型语言,拥有极高的跨平台能力,可以编写桌面应用程序、Web应用程序、分布式系统和嵌入式系统应用程序等,是大数据工程师最喜欢的编程工具。 命令对于大数据开发通常是在Linux环境下进行的,相比Linux操作系统,Windows操作系统是封闭的操作系统,开源的大数据软件很受限制。 3. HadoopHadoop是大数据开发的重要框架,其核心是HDFS和MapReduce,HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算,因此,需要重点掌握,除此之外,还需要掌握Hadoop集群、Hadoop集群管理、YARN以及Hadoop高级管理等相关技术与操作!4. HiveHive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行,十分适合数据仓库的统计分析。 对于Hive需掌握其安装、应用及高级操作等。 5. Avro与ProtobufAvro与Protobuf均是数据序列化系统,可以提供丰富的数据结构类型,十分适合做数据存储,还可进行不同语言之间相互通信的数据交换格式,学习大数据,需掌握其具体用法。 是Hadoop和Hbase的重要组件,是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组件服务等,在大数据开发中要掌握ZooKeeper的常用命令及功能的实现方法。 7. HBaseHBase是一个分布式的、面向列的开源数据库,它不同于一般的关系数据库,更适合于非结构化数据存储的数据库,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,大数据开发需掌握HBase基础知识、应用、架构以及高级用法等。 是用Java编写的基于JDBC API操作HBase的开源SQL引擎,其具有动态列、散列加载、查询服务器、追踪、事务、用户自定义函数、二级索引、命名空间映射、数据收集、行时间戳列、分页查询、跳跃查询、视图以及多租户的特性,大数据开发需掌握其原理和使用方法。 9. RedisRedis是一个key-value存储系统,其出现很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用,它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便,大数据开发需掌握Redis的安装、配置及相关使用方法。 10. FlumeFlume是一款高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。 大数据开发需掌握其安装、配置以及相关使用方法。 11. SSMSSM框架是由Spring、SpringMVC、MyBatis三个开源框架整合而成,常作为数据源较简单的web项目的框架。 大数据开发需分别掌握Spring、SpringMVC、MyBatis三种框架的同时,再使用SSM进行整合操作。 是一种高吞吐量的分布式发布订阅消息系统,其在大数据开发应用上的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。 大数据开发需掌握Kafka架构原理及各组件的作用和使用方法及相关功能的实现!是一门多范式的编程语言,大数据开发重要框架Spark是采用Scala语言设计的,想要学好Spark框架,拥有Scala基础是必不可少的,因此,大数据开发需掌握Scala编程基础知识!是专为大规模数据处理而设计的快速通用的计算引擎,其提供了一个全面、统一的框架用于管理各种不同性质的数据集和数据源的大数据处理的需求,大数据开发需掌握Spark基础、SparkJob、Spark RDD、spark job部署与资源分配、Spark shuffle、Spark内存管理、Spark广播变量、Spark SQL、Spark Streaming以及Spark ML等相关知识。 是一个批量工作流任务调度器,可用于在一个工作流内以一个特定的顺序运行一组工作和流程,可以利用Azkaban来完成大数据的任务调度,大数据开发需掌握Azkaban的相关配置及语法规则。 与数据分析Python是面向对象的编程语言,拥有丰富的库,使用简单,应用广泛,在大数据领域也有所应用,主要可用于数据采集、数据分析以及数据可视化等,因此,大数据开发需学习一定的Python知识。











发表评论