
由知名数据库供应商提出的redis集群正在改变着企业的业务发展和管理模式。Redis集群采用多台 服务器 组成的分布式结构,能够更有效地处理海量数据,并能够支持多用户并发访问,比单台Redis更加强大、稳定和可靠。
单台Redis尽管也拥有较高的性能,但在处理与业务发展相关的大量数据和多用户并发访问时,Redis使用单台服务器就无法应付。Redis集群技术能够有效解决这个问题,使Redis的性能和可用性得到显著提升,从而支持种类繁多的业务发展需求。
Redis集群单数台可以将Redis搭建良好的可扩展性和高性能,从而有效解决突破旧限的难题。 Redis集群单数台可以有效地缩小数据库搭建的空间及时间消耗,从而支持更多的数据分析,进而有效提升企业业务发展。
在搭建Redis集群时,关键在于适当设置服务器结构及容量,从而最大限度地充分利用Redis集群的优势。为此,最好将Redis集群的设计和搭建交给Redis专家服务商,实现较大的性能提升。
要照亮业务发展之路,建议企业将Redis完全转移到整体的Redis集群系统,以解决业务发展中大量数据处理和多用户并发访问的瓶颈,使Redis得到最大程度实现功能、性能和可靠性的提升,以实现业务发展和发挥最大价值。
以下是部分Redis集群代码:
# 集群节点初始化> redis-cli --cluster create \`:6379`,`:6379`,`:6379`\--cluster-replicas 1# 验证集群状态> redis-cli --cluster check `:6379`# 设置集群节点的配置> redis-cli --cluster nodes `:6379` set-config-epochset-config-flag# 配置集群的 slots 分配> redis-cli --cluster add-slots `` `` `:6379`
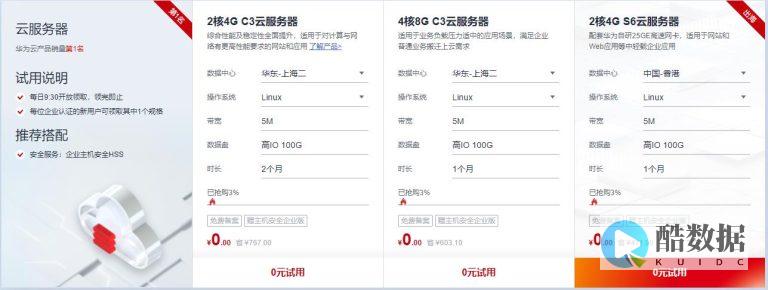
香港服务器首选树叶云,2H2G首月10元开通。树叶云(shuyeidc.com)提供简单好用,价格厚道的香港/美国云服务器和独立服务器。IDC+ISP+ICP资质。ARIN和APNIC会员。成熟技术团队15年行业经验。
Redis和Memcache的区别分析
1、 Redis和Memcache都是将数据存放在内存中,都是内存数据库。 不过memcache还可用于缓存其他东西,例如图片、视频等等。 2、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。 3、虚拟内存--Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘4、过期策略--memcache在set时就指定,例如set key1 0 0 8,即永不过期。 Redis可以通过例如expire 设定,例如expire name 105、分布式--设定memcache集群,利用magent做一主多从;redis可以做一主多从。 都可以一主一从6、存储数据安全--memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化)7、灾难恢复--memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复8、Redis支持数据的备份,即master-slave模式的数据备份。
跟老男孩学linux运维 web集群 基于什么系统
运维需要用到的东西很杂,从硬件设备到软件维护。 硬件设备 比如服务器的安装 网络的部署布局 ,最好能够了解防火墙,路由器,交换机的设置。 linux系统的深入了解。 最好能够深入到内核和代码层面部署在linux服务器上的应用的了解和维护,比如tomcat apache weblogic nagios cacti等。 包括开发人员编写的软件,都需要去进行维护和调优建议,最好了解js和java语言。 服务器的各种使用情况的监控,如磁盘,cpu,mem,io等。 架构设计的了解,以及自动化运维的脚本编写。 比如搭建集群或负载模式的架构等,实现服务器的多机热备高可用。 脚本编写,以减少人力操作来提高执行效率和准确性,一般需要shell,python,perl一类的语言基础,也包括awk,except等小语种使用。 数据库的维护熟悉主流的数据库操作,主要是添删改查的操作。 oracle,mysql,芒果db,DB2,memcache,redis等

如何入门 Python 爬虫
“入门”是良好的动机,但是可能作用缓慢。 如果你手里或者脑子里有一个项目,那么实践起来你会被目标驱动,而不会像学习模块一样慢慢学习。 另外如果说知识体系里的每一个知识点是图里的点,依赖关系是边的话,那么这个图一定不是一个有向无环图。 因为学习A的经验可以帮助你学习B。 因此,你不需要学习怎么样“入门”,因为这样的“入门”点根本不存在!你需要学习的是怎么样做一个比较大的东西,在这个过程中,你会很快地学会需要学会的东西的。 当然,你可以争论说需要先懂python,不然怎么学会python做爬虫呢?但是事实上,你完全可以在做这个爬虫的过程中学习python :D看到前面很多答案都讲的“术”——用什么软件怎么爬,那我就讲讲“道”和“术”吧——爬虫怎么工作以及怎么在python实现。 先长话短说summarize一下:你需要学习基本的爬虫工作原理基本的http抓取工具,scrapyBloom Filter: Bloom Filters by Example如果需要大规模网页抓取,你需要学习分布式爬虫的概念。 其实没那么玄乎,你只要学会怎样维护一个所有集群机器能够有效分享的分布式队列就好。 最简单的实现是python-rq:和Scrapy的结合:darkrho/scrapy-redis · GitHub后续处理,网页析取(grangier/python-goose · GitHub),存储(Mongodb)










发表评论