
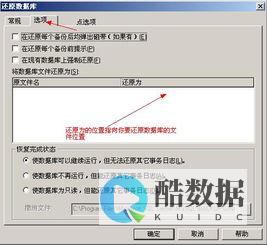
MySQL查询结果条数编号的方法并不复杂,下面就以实例的形式为您介绍MySQL查询结果条数编号实现过程,我们先来了解一下MySQL查询结果条数编号的语句写法:
实例:
MySQL查询缓存变量的相关解释
MySQL命令行乱码问题的解决
复杂SQL语句
语句(假设你的系统取日期月份的函数MONTH): SELECT MONTH(注册日期),COUNT(*) FROM 表 GROUP BY 1 产生的结果是: 1 23 2 10 3 45 如果你计算每个月度(、、……)的注册人数,应该使用下面的语句(假设你的系统取日期年度的函数是YEAR): SELECT YEAR(注册日期)+ +MONTH(注册日期),COUNT(*) FROM 表 GROUP BY 1 假如你的系统连接字符串不是使用+,那换为相应的字符或者函数,比如INFORMIX是使用YEAR(注册日期)||MONTH(注册日期),比如MYSQL是使用CONCATE函数 补充: SELECT语句的教材专门有聚合函数那一章,你仔细看看吧。 在SELECT语句里面,GROUP子句配合SUM,AVG,MAX,MIN等函数完成分类统计功能,执行我的两个语句,查看输出的结果,你就知道GROUP的含义,下面取一个最简单的例子: “SELECT COUNT(*) FROM 表”这个SQL语句返回的结果只有一个,就是数据库中的总记录条数,如果我们想统计不同用户名的分组进行汇总的记录条数,就应该在SELECT后增加一个字段,同事GROUP BY这个字段,完整的语句是: SELECT 用户名,COUNT(*) FROM 表 GROUP BY 用户名 这个语句也可以这样写: SELECT 用户名,COUNT(*) FROM 表 GROUP BY 1 这时候GROUP BY后面的整数表示按照相应序号的SELECT列分组,这里的1表示第一个的选择结果“用户名”。 如果我们想按用户分组查记录数,但是只现实有重复的记录,那么用GROUP BY的一个HAVING修饰,完整语句如下: SELECT 用户名,COUNT(*) FROM 表 GROUP BY 用户名 HAVING COUNT(*)>1
MySQL的SELECT查询结果的显示?
把SELECT * FROM USERS;最后的;改成\GG要大写.
SQL中EXISTS怎么用

EXISTS用于检查子查询是否至少会返回一行e4b893e5b19e031数据,该子查询实际上并不返回任何数据,而是返回值True或FalseEXISTS 指定一个子查询,检测 行 的存在。 语法: EXISTS subquery参数: subquery 是一个受限的 SELECT 语句 (不允许有 COMputE 子句和 INTO 关键字)。 结果类型: Boolean 如果子查询包含行,则返回 TRUE ,否则返回 FLASE 。 例表A:TableIn例表B:TableEx(一). 在子查询中使用 NULL 仍然返回结果集select * from TableIn where exists(select null)等同于: select * from TableIn(二). 比较使用 EXISTS 和 IN 的查询。 注意两个查询返回相同的结果。 select * from TableIn where exists(select BID from TableEx where BNAME=)select * from TableIn where ANAME in(select BNAME from TableEx)(三). 比较使用 EXISTS 和 = ANY 的查询。 注意两个查询返回相同的结果。 select * from TableIn where exists(select BID from TableEx where BNAME=)select * from TableIn where ANAME=ANY(select BNAME from TableEx)NOT EXISTS 的作用与 EXISTS 正好相反。 如果子查询没有返回行,则满足了 NOT EXISTS 中的 WHERE 子句。 结论:EXISTS(包括 NOT EXISTS )子句的返回值是一个BOOL值。 EXISTS内部有一个子查询语句(SELECT ... FROM...), 我将其称为EXIST的内查询语句。 其内查询语句返回一个结果集。 EXISTS子句根据其内查询语句的结果集空或者非空,返回一个布尔值。











发表评论