

用Redis瞬间生成文件
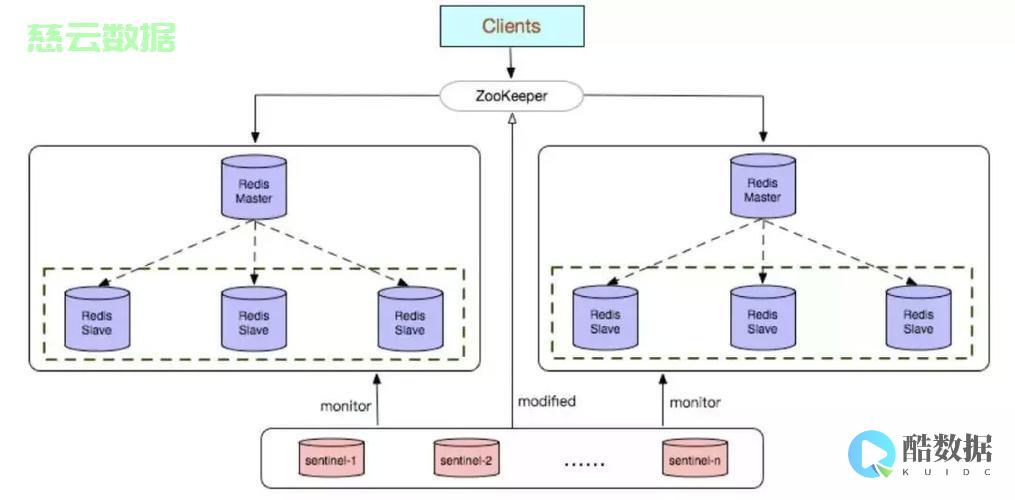
Redis是一款高性能的key-value存储
 服务器
,具有快速、内存占用低、支持多种数据结构等优点,在实际的开发中有着广泛的应用。本文将介绍如何使用Redis瞬间生成文件的方法。
服务器
,具有快速、内存占用低、支持多种数据结构等优点,在实际的开发中有着广泛的应用。本文将介绍如何使用Redis瞬间生成文件的方法。
在实际开发中,有时需要快速地生成一个文件,例如随机生成一个文本文件用于测试,或者将一些数据以文件的形式进行存储等等。这时我们可以使用Redis来完成。
Redis支持多种数据类型,其中的字符串(string)类型能够存储任意类型的数据,最大长度是512MB。这意味着,我们可以将文件的内容以二进制串的形式存储在Redis字符串类型的数据中。
例如,我们可以在Redis中使用以下代码将一个名为“test.txt”的文件存储进去:
# 连接到Redisimport redisr = redis.Redis(host='localhost', port=6379)# 读取文件内容with open('test.txt', 'rb') as f:Content = f.read()# 将文件保存到Redisr.set('test.txt', content)
上述代码中,我们首先用Python的redis模块连接到了本地的Redis服务器。然后,使用Python的内置函数open()读取了一个名为“test.txt”的文件,并将其二进制内容存储到了变量content中。我们使用了Redis的set()方法将文件内容存储到了名为“test.txt”的Redis字符串中。
现在,我们已经将文件存储在了Redis中。如果需要将文件取出来,只需使用get()方法即可:
# 从Redis中读取文件data = r.get('test.txt')# 将文件写入本地磁盘with open('test.txt', 'wb') as f:f.write(data)
在上面的代码中,我们使用了Redis的get()方法将名为“test.txt”的字符串数据取出。由于我们在存储时将其以二进制的形式存储,因此在读取时也需要以二进制的形式进行读取。
上述代码将从Redis中读取到的二进制数据写入了一个名为“test.txt”的文件中。这样,我们就将存储在Redis中的文件成功取出来了。
通过上述代码,我们可以看到Redis具有很强的灵活性和高效性,可以用来处理许多实际问题。在实际开发中,如果需要快速地生成文件,可以使用Redis来处理,以提高开发效率。
香港服务器首选树叶云,2H2G首月10元开通。树叶云(www.IDC.Net)提供简单好用,价格厚道的香港/美国云服务器和独立服务器。IDC+ISP+ICP资质。ARIN和APNIC会员。成熟技术团队15年行业经验。
linux和win有什么区别?
windows文件系统包括fat16,fat32,ntfs,ntfs5.0,winfs等,fat系统最简单,由文件分配表来确定文件在盘上的实际存贮位置。 ntfs要复杂的多,除了保存文件之外,还支持文件的权限,加密等附加特性。 winfs系统是未来windows的文件系统,这种系统更加复杂,是以数据库的形式保存文件的。 linux文件系统包括XFS文件系统,EFS文件系统,NFS文件系统,/proc文件系统,生成文件系统。 XFS文件系统是一种新的IRIX文件系统,它需要32M内存。 EFS文件系统是IRIX文件系统早期的版本,它已不再使用。 NFS文件系统是网络文件系统的缩写。 在IRIX系统中,NFS系统是可选的软件。 一个主机输出NFS文件系统,网络上的其它主机通过网络可以访问被输出的NFS文件系统。 /proc文件系统为监控程序提供接口,它又叫调试文件系统。 /proc文件系统安装在/proc目录下,链接到/debug目录。 /proc文件不消耗磁盘空间,所以使用df命令不会显示/proc文件系统,它们不能被删除或移动。 生成文件系统是使用mkfs_xfs、mkfs_efs命令将磁盘分区变成XFS或EFS文件系统。
数据写入redis并返回怎么处理
1、 快照的方式持久化到磁盘自动持久化规则配置save 900 1save 300 10save 60 上面的配置规则意思如下:# In the example below the behaviour will be to save:# after 900 sec (15 min) if at least 1 key changed# after 300 sec (5 min) if at least 10 keys changed# after 60 sec if at least keys changedredis也可以关闭自动持久化,注释掉这些save配置,或者save “”如果后台保存到磁盘发生错误,将停止写操作-writes-on-bgsave-error yes使用LZF压缩rdb文件,这会耗CPU, 但是可以减少磁盘占用 yes保存rdb和加载rdb文件的时候检验,可以防止错误,但是要付出约10%的性能,可以关闭他,提高性能。 rdbchecksum yes导出的rdb文件名dbfilename 设置工作目录, rdb文件会写到该目录, append only file也会存储在该目录下 ./Redis自动快照保存到磁盘或者调用bgsave,是后台进程完成的,其他客户端仍然和可以读写redis服务器,后台保存快照到磁盘会占用大量内存。 调用save保存内存中的数据到磁盘,将阻塞客户端请求,直到保存完毕。 调用shutdown命令,Redis服务器会先调用save,所有数据持久化到磁盘之后才会真正退出。 对于数据丢失的问题:如果服务器crash,从上一次快照之后的数据将全部丢失。 所以在设置保存规则的时候,要根据实际业务设置允许的范围。 如果对于数据敏感的业务,在程序中要使用恰当的日志,在服务器crash之后,通过日志恢复数据。 2、 Append-only file 的方式持久化另外一种方式为递增的方式,将会引起数据变化的操作, 持久化到文件中, 重启redis的时候,通过操作命令,恢复数据.每次执行写操作命令之后,都会将数据写到中。 # appendfsync alwaysappendfsync everysec# appendfsync no当配置为always的时候,每次中的数据写入到文件之后,才会返回给客户端,这样可以保证数据不丢,但是频繁的IO操作,会降低性能。 everysec每秒写一次,这可能会丢失一秒内的操作。 aof最大的问题就是随着时间append file会变的很大,所以我们需要bgrewriteaof命令重新整理文件,只保留最新的kv数据。
redis比mysql访问速度快吗
您好,我来为您解答:首先,我们知道,mysql是持久化存储,存放在磁盘里面,检索的话,会涉及到一定的IO,为了解决这个瓶颈,于是出现了缓存,比如现在用的最多的 memcached(简称mc)。 首先,用户访问mc,如果未命中,就去访问mysql,之后像内存和硬盘一样,把数据复制到mc一部分。 redis和mc都是缓存,并且都是驻留在内存中运行的,这大大提升了高数据量web访问的访问速度。 然而mc只是提供了简单的数据结构,比如 string存储;redis却提供了大量的数据结构,比如string、list、set、hashset、sorted set这些,这使得用户方便了好多,毕竟封装了一层实用的功能,同时实现了同样的效果,当然用redis而慢慢舍弃mc。 内存和硬盘的关系,硬盘放置主体数据用于持久化存储,而内存则是当前运行的那部分数据,CPU访问内存而不是磁盘,这大大提升了运行的速度,当然这是基于程序的局部化访问原理。 推理到redis+mysql,它是内存+磁盘关系的一个映射,mysql放在磁盘,redis放在内存,这样的话,web应用每次只访问redis,如果没有找到的数据,才去访问Mysql。 然而redis+mysql和内存+磁盘的用法最好是不同的。 转载,仅供参考。 如果我的回答没能帮助您,请继续追问。













发表评论