
在数据库管理系统中,排序是一项非常重要的功能之一。通过排序,我们可以方便地将数据按照某种规则排列,使得数据更加有序,更加易于分析和处理。而排序规则则是实现排序功能的基础,因此了解排序规则的定义和特点对于深入理解数据库管理系统的工作原理和进行数据处理工作都有很大的意义。
一、排序规则的定义
排序规则是从数据库管理系统的角度出发,对于数据排序所要遵循的一套规范。一般来说,排序规则可以定义字段的排序方式(升序或降序)、处理空值的方式(放在开头或结尾)、处理字母大小写的方式等方面。不同的数据库管理系统对于排序规则的定义略有不同,但基本的概念和原则都是相似的。
以 SQL Server 为例,其定义排序规则主要是通过指定排序规则名称来实现的。常用的排序规则名称有 SQL_Latin1_General_CP1_CI_AS、Chinese_PRC_CI_AS 等。其中,CP1 表示 Code Page 1,CI 表示 Case Insensitive(不区分大小写),AS 表示 Ascending(升序)。
二、排序规则的分类
排序规则一般可以按照不同的标准进行分类。这里我们可以将其按照字母大小写、语言区域、字符集等维度进行划分。
1、按照字母大小写分类
在排序时,是否区分字母大小写是一个重要的问题。一般来说,如果需要区分字母大小写,那么在排序规则名称中会出现 CS(Case Sensitive)这一关键字;反之,则会出现 CI(Case Insensitive)这一关键字。
例如,SQL_Latin1_General_CP1_CS_AS 和 SQL_Latin1_General_CP1_CI_AS 就是按照字母大小写区分和不区分的排序规则。
2、按照语言区域分类
不同的语言使用的字符和排序方式也不同,因此实际操作中也需要根据不同的语言区域定义不同的排序规则。例如,中文、英文、法文等使用的字符不同,因此需要根据具体情况进行定义。
例如,Chinese_PRC_CI_AS 就是一种按照中文区域定义的排序规则。
3、按照字符集分类
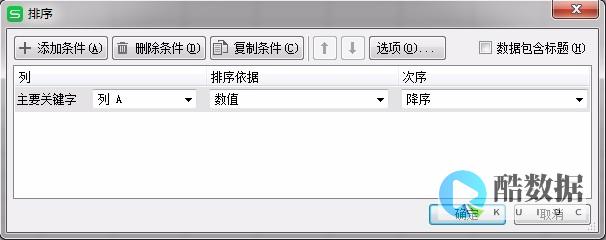
字符集是指一组字符的编码方式,也是影响排序规则的重要因素之一。不同的字符集对于排序方式有不同的影响,因此在定义排序规则时也需要考虑字符集的因素。
例如,SQL_Latin1_General_CP1_CI_AS 就是一种按照 Latin1 字符集定义的排序规则。
三、排序规则的应用场景
1、文本排序
在实际的操作中,我们常常需要对于文本进行排序。例如,对于一份成绩单,按照学生姓名或成绩进行排序。在这种情况下,排序规则的定义就是至关重要的。通常情况下,我们会采用不区分大小写的排序方式,以保证排序的准确性与稳定性。
另外,一些专业领域中的缩写词则需要采用特殊的排序规则。例如,在计算机领域中,有一些专业的术语缩写,如果采用正常的排序方式,可能会导致排序出现问题,因此我们需要根据具体情况定义排序规则。
2、数值排序
数值排序是对于数值数据进行排序的过程。一般来说,数值排序需要按照数值大小进行排序,因此在定义排序规则时也需要注意数据类型的影响。一些数据库管理系统并不支持对于不同数据类型进行混合排序,因此在实际使用中需要格外留意。
四、
排序规则是数据库管理系统中非常重要的一项功能,通过定义排序规则,我们可以方便地对于数据进行排序处理,并实现数据的更好的利用。在实际使用中,需要根据不同需求选择不同的排序规则,并注重排序规则的具体定义和影响因素,以达到更好的排序效果。
相关问题拓展阅读:
什么是数据库里的排序规则?
排序规则?
就是排序的依据喽
最常见的是大小的升序和降序排序
oracle数据库中文怎么排序规则
ORACLE数据库中文排序规则
oracle9i之前,中文是按照二进制编码进行排序的。
在oracle9i中新增了按照拼音、部首、笔画排序功能。设置NLS_SORT值
SCHINESE_RADICAL_M 按照部首(之一顺序)、判毕磨笔划(第二顺序)排序
SCHINESE_STROKE_M 按照笔划(之一顺序)、部数改首(第二顺序)排序
SCHINESE_PINYIN_M 按照拼音排序,系统的默认排序方式掘斗为拼音排序
alter session set nls_sort=’schinese_pinyin_m’;
select * from dept order by nlssort(name,’NLS_SORT=SCHINESE_PINYIN_M’);
系统的默认排序方式为拼音排序
关于排序规则 数据库的介绍到此就结束了,不知道你从中找到你需要的信息了吗 ?如果你还想了解更多这方面的信息,记得收藏关注本站。
香港服务器首选树叶云,2H2G首月10元开通。树叶云(www.IDC.Net)提供简单好用,价格厚道的香港/美国云 服务器 和独立服务器。IDC+ISP+ICP资质。ARIN和APNIC会员。成熟技术团队15年行业经验。
怎么学习SQL数据库的语句?
一、 简单查询简单的Transact-SQL查询只包括选择列表、FROM子句和WHERE子句。 它们分别说明所查询列、查询的表或视图、以及搜索条件等。 例如,下面的语句查询testtable表中姓名为“张三”的nickname字段和email字段。 SELECT nickname,emailFROM testtableWHERE(一) 选择列表选择列表(select_list)指出所查询列,它可以是一组列名列表、星号、表达式、变量(包括局部变量和全局变量)等构成。 1、选择所有列例如,下面语句显示testtable表中所有列的数据:SELECT *FROM testtable2、选择部分列并指定它们的显示次序查询结果集合中数据的排列顺序与选择列表中所指定的列名排列顺序相同。 例如:SELECT nickname,emailFROM testtable3、更改列标题在选择列表中,可重新指定列标题。 定义格式为:列标题=列名列名 列标题如果指定的列标题不是标准的标识符格式时,应使用引号定界符,例如,下列语句使用汉字显示列标题:SELECT 昵称=nickname,电子邮件=emailFROM testtable4、删除重复行SELECT语句中使用ALL或DISTINCT选项来显示表中符合条件的所有行或删除其中重复的数据行,默认为ALL。 使用DISTINCT选项时,对于所有重复的数据行在SELECT返回的结果集合中只保留一行。 5、限制返回的行数使用TOP n [PERCENT]选项限制返回的数据行数,TOP n说明返回n行,而TOP n PERCENT时,说明n是表示一百分数,指定返回的行数等于总行数的百分之几。 例如:SELECT TOP 2 *FROM testtable SELECT TOP 20 PERCENT * FROM testtable(二)FROM子句FROM子句指定SELECT语句查询及与查询相关的表或视图。 在FROM子句中最多可指定256个表或视图,它们之间用逗号分隔。 在FROM子句同时指定多个表或视图时,如果选择列表中存在同名列,这时应使用对象名限定这些列所属的表或视图。 例如在usertable和citytable表中同时存在cityid列,在查询两个表中的cityid时应使用下面语句格式加以限定:SELECT username, usertable,citytableWHERE =在FROM子句中可用以下两种格式为表或视图指定别名:表名 as 别名表名 别名(二) FROM子句FROM子句指定SELECT语句查询及与查询相关的表或视图。 在FROM子句中最多可指定256个表或视图,它们之间用逗号分隔。 在FROM子句同时指定多个表或视图时,如果选择列表中存在同名列,这时应使用对象名限定这些列所属的表或视图。 例如在usertable和citytable表中同时存在cityid列,在查询两个表中的cityid时应使用下面语句格式加以限定:SELECT username, usertable,citytableWHERE =在FROM子句中可用以下两种格式为表或视图指定别名:表名 as 别名表名 别名例如上面语句可用表的别名格式表示为:SELECT username, usertable a,citytable bWHERE =不仅能从表或视图中检索数据,它还能够从其它查询语句所返回的结果集合中查询数据。 例如:SELECT _fname+_lnameFROM authors a,titleauthor ta(SELECT title_id,titleFROM titlesWHERE ytd_sales>) AS tWHERE _id=_idAND _id=_id此例中,将SELECT返回的结果集合给予一别名t,然后再从中检索数据。 (三) 使用WHERE子句设置查询条件WHERE子句设置查询条件,过滤掉不需要的数据行。 例如下面语句查询年龄大于20的数据:SELECT *FROM usertableWHERE age>20WHERE子句可包括各种条件运算符:比较运算符(大小比较):>、>=、=、<、<=、<>、!>、!<范围运算符(表达式值是否在指定的范围):BETWEEN…AND…NOT BETWEEN…AND…列表运算符(判断表达式是否为列表中的指定项):IN (项1,项2……)NOT IN (项1,项2……)模式匹配符(判断值是否与指定的字符通配格式相符):LIKE、NOT LIKE空值判断符(判断表达式是否为空):IS NULL、NOT IS NULL逻辑运算符(用于多条件的逻辑连接):NOT、AND、OR1、范围运算符例:age BETWEEN 10 AND 30相当于age>=10 AND age<=302、列表运算符例:country IN (Germany,China)3、模式匹配符例:常用于模糊查找,它判断列值是否与指定的字符串格式相匹配。 可用于char、varchar、text、ntext、datetime和smalldatetime等类型查询。 可使用以下通配字符:百分号%:可匹配任意类型和长度的字符,如果是中文,请使用两个百分号即%%。 下划线_:匹配单个任意字符,它常用来限制表达式的字符长度。 方括号[]:指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个。 [^]:其取值也[] 相同,但它要求所匹配对象为指定字符以外的任一个字符。 例如:限制以Publishing结尾,使用LIKE %Publishing限制以A开头:LIKE [A]%限制以A开头外:LIKE [^A]%4、空值判断符例WHERE age IS NULL5、逻辑运算符:优先级为NOT、AND、OR(四)查询结果排序使用ORDER BY子句对查询返回的结果按一列或多列排序。 ORDER BY子句的语法格式为:ORDER BY {column_name [ASC|DESC]} [,…n]其中ASC表示升序,为默认值,DESC为降序。 ORDER BY不能按ntext、text和image数据类型进行排序。 例如:SELECT *FROM usertableORDER BY age desc,userid ASC另外,可以根据表达式进行排序。 正文] 买电脑,打800-858-0410 国内最低价,还有优惠 上一页 1 2 3二、 联合查询UNION运算符可以将两个或两个以上上SELECT语句的查询结果集合合并成一个结果集合显示,即执行联合查询。 UNION的语法格式为:select_statementUNION [ALL] selectstatement[UNION [ALL] selectstatement][…n]其中selectstatement为待联合的SELECT查询语句。 ALL选项表示将所有行合并到结果集合中。 不指定该项时,被联合查询结果集合中的重复行将只保留一行。 联合查询时,查询结果的列标题为第一个查询语句的列标题。 因此,要定义列标题必须在第一个查询语句中定义。 要对联合查询结果排序时,也必须使用第一查询语句中的列名、列标题或者列序号。 在使用UNION 运算符时,应保证每个联合查询语句的选择列表中有相同数量的表达式,并且每个查询选择表达式应具有相同的数据类型,或是可以自动将它们转换为相同的数据类型。 在自动转换时,对于数值类型,系统将低精度的数据类型转换为高精度的数据类型。 在包括多个查询的UNION语句中,其执行顺序是自左至右,使用括号可以改变这一执行顺序。 例如:查询1 UNION (查询2 UNION 查询3)三、连接查询通过连接运算符可以实现多个表查询。 连接是关系数据库模型的主要特点,也是它区别于其它类型数据库管理系统的一个标志。 在关系数据库管理系统中,表建立时各数据之间的关系不必确定,常把一个实体的所有信息存放在一个表中。 当检索数据时,通过连接操作查询出存放在多个表中的不同实体的信息。 连接操作给用户带来很大的灵活性,他们可以在任何时候增加新的数据类型。 为不同实体创建新的表,尔后通过连接进行查询。 连接可以在SELECT 语句的FROM子句或WHERE子句中建立,似是而非在FROM子句中指出连接时有助于将连接操作与WHERE子句中的搜索条件区分开来。 所以,在Transact-SQL中推荐使用这种方法。 SQL-92标准所定义的FROM子句的连接语法格式为:FROM join_table join_type join_table[ON (join_condition)]其中join_table指出参与连接操作的表名,连接可以对同一个表操作,也可以对多表操作,对同一个表操作的连接又称做自连接。 join_type 指出连接类型,可分为三种:内连接、外连接和交叉连接。 内连接(INNER JOIN)使用比较运算符进行表间某(些)列数据的比较操作,并列出这些表中与连接条件相匹配的数据行。 根据所使用的比较方式不同,内连接又分为等值连接、自然连接和不等连接三种。 外连接分为左外连接(left OUTER JOIN或LEFT JOIN)、右外连接(RIGHT OUTER JOIN或RIGHT JOIN)和全外连接(FULL OUTER JOIN或FULL JOIN)三种。 与内连接不同的是,外连接不只列出与连接条件相匹配的行,而是列出左表(左外连接时)、右表(右外连接时)或两个表(全外连接时)中所有符合搜索条件的数据行。 交叉连接(CROSS JOIN)没有WHERE 子句,它返回连接表中所有数据行的笛卡尔积,其结果集合中的数据行数等于第一个表中符合查询条件的数据行数乘以第二个表中符合查询条件的数据行数。 连接操作中的ON (join_condition) 子句指出连接条件,它由被连接表中的列和比较运算符、逻辑运算符等构成。 无论哪种连接都不能对text、ntext和image数据类型列进行直接连接,但可以对这三种列进行间接连接。 例如:SELECT _id,_id,_infoFROM pub_info AS p1 INNER JOIN pub_info AS p2ON DATALENGTH(_info)=DATALENGTH(_info)(一)内连接内连接查询操作列出与连接条件匹配的数据行,它使用比较运算符比较被连接列的列值。 内连接分三种:1、等值连接:在连接条件中使用等于号(=)运算符比较被连接列的列值,其查询结果中列出被连接表中的所有列,包括其中的重复列。 2、不等连接: 在连接条件使用除等于运算符以外的其它比较运算符比较被连接的列的列值。 这些运算符包括>、>=、<=、<、!>、!<和><>。 3、自然连接:在连接条件中使用等于(=)运算符比较被连接列的列值,但它使用选择列表指出查询结果集合中所包括的列,并删除连接表中的重复列。 例,下面使用等值连接列出authors和publishers表中位于同一城市的作者和出版社:SELECT *FROM authors AS a INNER JOIN publishers AS pON =又如使用自然连接,在选择列表中删除authors 和publishers 表中重复列(city和state):SELECT a.*,_id,_name, authors AS a INNER JOIN publishers AS pON =(二)外连接内连接时,返回查询结果集合中的仅是符合查询条件( WHERE 搜索条件或 HAVING 条件)和连接条件的行。 而采用外连接时,它返回到查询结果集合中的不仅包含符合连接条件的行,而且还包括左表(左外连接时)、右表(右外连接时)或两个边接表(全外连接)中的所有数据行。 如下面使用左外连接将论坛内容和作者信息连接起来: SELECT a.*,b.* FROM luntan LEFT JOIN usertable as bON =下面使用全外连接将city表中的所有作者以及user表中的所有作者,以及他们所在的城市:SELECT a.*,b.*FROM city as a FULL OUTER JOIN user as bON =(三)交叉连接交叉连接不带WHERE 子句,它返回被连接的两个表所有数据行的笛卡尔积,返回到结果集合中的数据行数等于第一个表中符合查询条件的数据行数乘以第二个表中符合查询条件的数据行数。 例,titles表中有6类图书,而publishers表中有8家出版社,则下列交叉连接检索到的记录数将等于6*8=48行。 SELECT type,pub_nameFROM titles CROSS JOIN publishersORDER BY type
sql 中排序先按某字段升序,后按某字段降序。
order by 后面的是从第一个开始的 order by position,money desc,top desc 的意思是 position升序排列,position相等时候 按money降序排,position,money都相等时候,按top降序排

mysql数据库性能测试
我理解的是你希望了解mysql性能测试的方法:其实常用的一般:选取最适用的字段属性MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。
因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可能小。
例如,在定义邮政编码这个字段时,如果将其设置为CHAR(255),显然给数据库增加了不必要的空间,甚至使用VARCHAR这种类型也是多余的,因为CHAR(6)就可以很好的完成任务了。
同样的,如果可以的话,我们应该使用MEDIUMINT而不是BIGIN来定义整型字段。
另外一个提高效率的方法是在可能的情况下,应该尽量把字段设置为NOT NULL,这样在将来执行查询的时候,数据库不用去比较NULL值。
对于某些文本字段,例如“省份”或者“性别”,我们可以将它们定义为ENUM类型。
因为在MySQL中,ENUM类型被当作数值型数据来处理,而数值型数据被处理起来的速度要比文本类型快得多。
这样,我们又可以提高数据库的性能。
2、使用连接(JOIN)来代替子查询(Sub-Queries)MySQL从4.1开始支持SQL的子查询。
这个技术可以使用SELECT语句来创建一个单列的查询结果,然后把这个结果作为过滤条件用在另一个查询中。
例如,我们要将客户基本信息表中没有任何订单的客户删除掉,就可以利用子查询先从销售信息表中将所有发出订单的客户ID取出来,然后将结果传递给主查询,如下所示:DELETE FROM customerinfo WHERE CustomerID NOT in (SELECT CustomerID FROM salesinfo )使用子查询可以一次性的完成很多逻辑上需要多个步骤才能完成的SQL操作,同时也可以避免事务或者表锁死,并且写起来也很容易。
但是,有些情况下,子查询可以被更有效率的连接(JOIN).. 替代。
例如,假设我们要将所有没有订单记录的用户取出来,可以用下面这个查询完成:SELECT * FROM customerinfo WHERE CustomerID NOT in (SELECT CustomerID FROM salesinfo )如果使用连接(JOIN).. 来完成这个查询工作,速度将会快很多。
尤其是当salesinfo表中对CustomerID建有索引的话,性能将会更好,查询如下:SELECT * FROM customerinfo LEFT JOIN salesinfoON =salesinfo. CustomerID WHERE IS NULL连接(JOIN).. 之所以更有效率一些,是因为 MySQL不需要在内存中创建临时表来完成这个逻辑上的需要两个步骤的查询工作。
3、使用联合(UNION)来代替手动创建的临时表MySQL 从 4.0 的版本开始支持 UNION 查询,它可以把需要使用临时表的两条或更多的 SELECT 查询合并的一个查询中。
在客户端的查询会话结束的时候,临时表会被自动删除,从而保证数据库整齐、高效。
使用 UNION 来创建查询的时候,我们只需要用 UNION作为关键字把多个 SELECT 语句连接起来就可以了,要注意的是所有 SELECT 语句中的字段数目要想同。
下面的例子就演示了一个使用 UNION的查询。
SELECT Name, Phone FROM client UNION SELECT Name, BirthDate FROM authorUNIONSELECT Name, Supplier FROM product4、事务尽管我们可以使用子查询(Sub-Queries)、连接(JOIN)和联合(UNION)来创建各种各样的查询,但不是所有的数据库操作都可以只用一条或少数几条SQL语句就可以完成的。
更多的时候是需要用到一系列的语句来完成某种工作。
但是在这种情况下,当这个语句块中的某一条语句运行出错的时候,整个语句块的操作就会变得不确定起来。
设想一下,要把某个数据同时插入两个相关联的表中,可能会出现这样的情况:第一个表中成功更新后,数据库突然出现意外状况,造成第二个表中的操作没有完成,这样,就会造成数据的不完整,甚至会破坏数据库中的数据。
要避免这种情况,就应该使用事务,它的作用是:要么语句块中每条语句都操作成功,要么都失败。
换句话说,就是可以保持数据库中数据的一致性和完整性。
事物以BEGIN 关键字开始,COMMIT关键字结束。
在这之间的一条SQL操作失败,那么,ROLLBACK命令就可以把数据库恢复到BEGIN开始之前的状态。
BEGIN;INSERT INTO salesinfo SET CustomerID=14;UPDATE inventory SET Quantity=11WHERE item=book;COMMIT;事务的另一个重要作用是当多个用户同时使用相同的数据源时,它可以利用锁定数据库的方法来为用户提供一种安全的访问方式,这样可以保证用户的操作不被其它的用户所干扰。
5、锁定表尽管事务是维护数据库完整性的一个非常好的方法,但却因为它的独占性,有时会影响数据库的性能,尤其是在很大的应用系统中。
由于在事务执行的过程中,数据库将会被锁定,因此其它的用户请求只能暂时等待直到该事务结束。
如果一个数据库系统只有少数几个用户来使用,事务造成的影响不会成为一个太大的问题;但假设有成千上万的用户同时访问一个数据库系统,例如访问一个电子商务网站,就会产生比较严重的响应延迟。
其实,有些情况下我们可以通过锁定表的方法来获得更好的性能。
下面的例子就用锁定表的方法来完成前面一个例子中事务的功能。
LOCK TABLE inventory WRITESELECT Quantity FROM inventoryWHEREItem=book; inventory SET Quantity=11WHEREItem=book;UNLOCK TABLES这里,我们用一个 SELECT 语句取出初始数据,通过一些计算,用 UPDATE 语句将新值更新到表中。
包含有 WRITE 关键字的 LOCK TABLE 语句可以保证在 UNLOCK TABLES 命令被执行之前,不会有其它的访问来对 inventory 进行插入、更新或者删除的操作。
6、使用外键锁定表的方法可以维护数据的完整性,但是它却不能保证数据的关联性。
这个时候我们就可以使用外键。
例如,外键可以保证每一条销售记录都指向某一个存在的客户。
在这里,外键可以把customerinfo 表中的CustomerID映射到salesinfo表中CustomerID,任何一条没有合法CustomerID的记录都不会被更新或插入到salesinfo中。
CREATE TABLE customerinfo( CustomerID INT NOT NULL , PRIMARY KEY ( CustomerID )) TYPE = INNODB;CREATE TABLE salesinfo( SalesID INT NOT NULL, CustomerID INT NOT NULL, PRIMARY KEY(CustomerID, SalesID), FOREIGN KEY (CustomerID) REFERENCES customerinfo (CustomerID) ON DELETECASCADE) TYPE = INNODB;注意例子中的参数“ON DELETE CASCADE”。
该参数保证当 customerinfo 表中的一条客户记录被删除的时候,salesinfo 表中所有与该客户相关的记录也会被自动删除。
如果要在 MySQL 中使用外键,一定要记住在创建表的时候将表的类型定义为事务安全表 InnoDB类型。
该类型不是 MySQL 表的默认类型。
定义的方法是在 CREATE TABLE 语句中加上 TYPE=INNODB。
如例中所示。
7、使用索引索引是提高数据库性能的常用方法,它可以令数据库服务器以比没有索引快得多的速度检索特定的行,尤其是在查询语句当中包含有MAX(), MIN()和ORDERBY这些命令的时候,性能提高更为明显。
那该对哪些字段建立索引呢?一般说来,索引应建立在那些将用于JOIN, WHERE判断和ORDER BY排序的字段上。
尽量不要对数据库中某个含有大量重复的值的字段建立索引。
对于一个ENUM类型的字段来说,出现大量重复值是很有可能的情况,例如customerinfo中的“province”.. 字段,在这样的字段上建立索引将不会有什么帮助;相反,还有可能降低数据库的性能。
我们在创建表的时候可以同时创建合适的索引,也可以使用ALTER TABLE或CREATE INDEX在以后创建索引。
此外,MySQL从版本3.23.23开始支持全文索引和搜索。
全文索引在MySQL 中是一个FULLTEXT类型索引,但仅能用于MyISAM 类型的表。
对于一个大的数据库,将数据装载到一个没有FULLTEXT索引的表中,然后再使用ALTER TABLE或CREATE INDEX创建索引,将是非常快的。
但如果将数据装载到一个已经有FULLTEXT索引的表中,执行过程将会非常慢。
8、优化的查询语句绝大多数情况下,使用索引可以提高查询的速度,但如果SQL语句使用不恰当的话,索引将无法发挥它应有的作用。
下面是应该注意的几个方面。
首先,最好是在相同类型的字段间进行比较的操作。
在MySQL 3.23版之前,这甚至是一个必须的条件。
例如不能将一个建有索引的INT字段和BIGINT字段进行比较;但是作为特殊的情况,在CHAR类型的字段和VARCHAR类型字段的字段大小相同的时候,可以将它们进行比较。
其次,在建有索引的字段上尽量不要使用函数进行操作。
例如,在一个DATE类型的字段上使用YEAE()函数时,将会使索引不能发挥应有的作用。
所以,下面的两个查询虽然返回的结果一样,但后者要比前者快得多。
SELECT * FROM order WHERE YEAR(OrderDate)<2001;SELECT * FROM order WHERE OrderDate<2001-01-01;同样的情形也会发生在对数值型字段进行计算的时候:SELECT * FROM inventory WHERE Amount/7<24;SELECT * FROM inventory WHERE Amount<24*7;上面的两个查询也是返回相同的结果,但后面的查询将比前面的一个快很多。
第三,在搜索字符型字段时,我们有时会使用 LIKE 关键字和通配符,这种做法虽然简单,但却也是以牺牲系统性能为代价的。
例如下面的查询将会比较表中的每一条记录。
SELECT * FROM booksWHERE name like MySQL%但是如果换用下面的查询,返回的结果一样,但速度就要快上很多:SELECT * FROM booksWHERE name>=MySQLand name












发表评论