

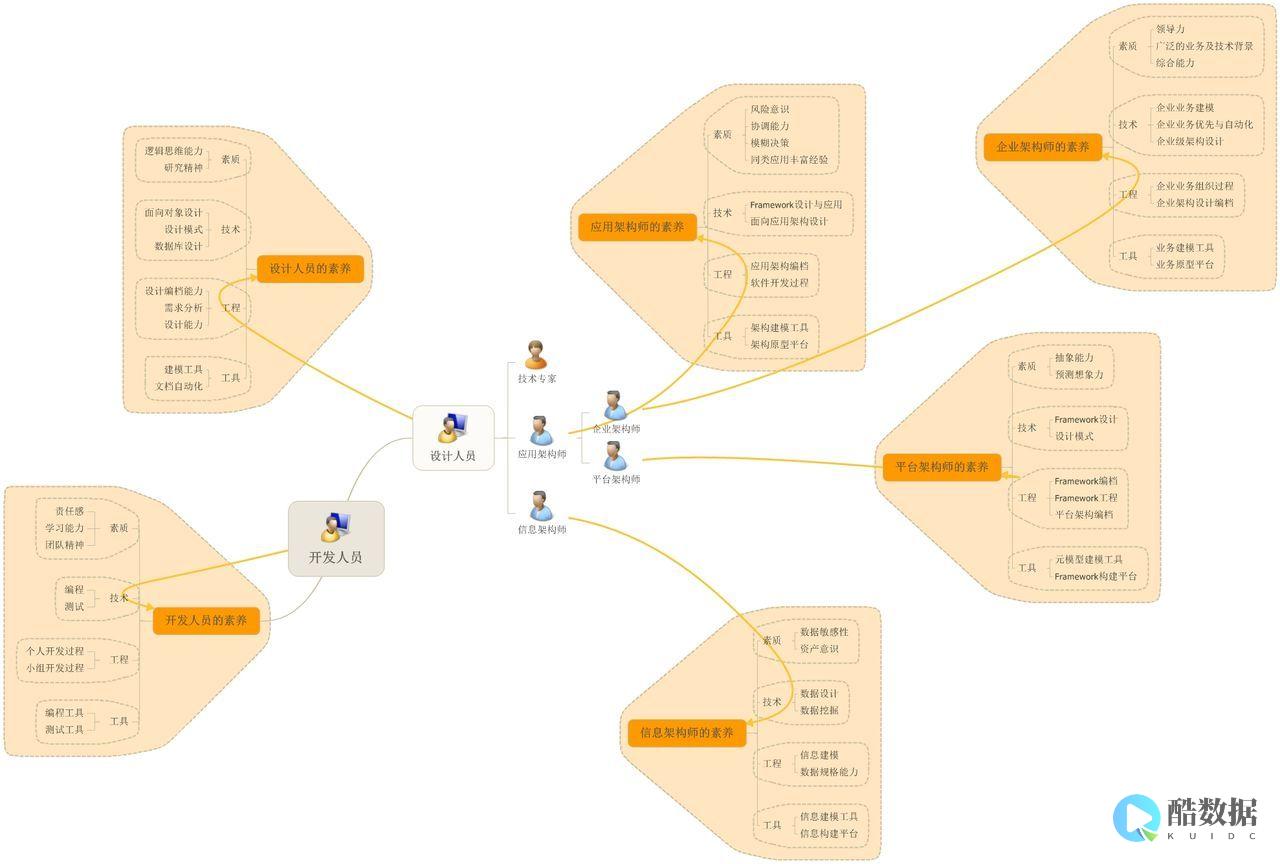
一、缘起
在我工作的多家公司,有众多的领域,如房产,电商,广告等领域。尽管业务相差很大,但都涉及到爬虫领域。开发爬虫项目多了后,自然而然的会面对一个问题——
这就是是我们今天要讨论的话题。
二、项目需求
立项之初,我们从使用的脚度试着提几个需求。
1. 分布式抓取
由于抓取量可能非常庞大,一台机器不足以处理百万以上的抓取任务,因此分布式爬虫应用是首当其冲要面对并解决的问题。
2. 模块化,轻量
我们将爬虫应用分成“应用层,服务层,业务处理层,调度层” 四个脚色。
3. 可管理,可监控
管理监控是一个体系,即配置可管理化,运行实时监控化。在系统正常运行时,可以变更爬虫的配置,一旦实时监控爬虫出现异常,可实时修正配置进行干预。所有的一切,均可以通过UI界面进行操作。
4. 通用性,可扩展。
爬虫业务往往多变,不同领域的爬取需求不尽相同。举例说,房源抓取包含图片抓取,小区信息抓取,房源去重等模块。新闻抓取包括内容抓取,正文提取,信息摘要等相关。
因此,系统需要能够支持业务扩展需求,可以支持不同的业务使用同一套框架进行应用开发。
三 模块分解
针对业务需求,我们将系统分解成多个应用模块。
1. 应用层
应用层是针对管理员,系统维护人员使用。主要分成两个模块,系统配置模块和运营管理模块。
系统运营人员可以根据运营模块得到实时的反馈,使用系统配置模块进行配置修正,在线测试正确后将配置生效,再实时监控新的配置产生的效果。
2. 服务层
服务层是整个系统传输的中枢,相当于整个分布式集中的系统总线和数据总线。服务层提供一个http/thrift接口,读取数据库,输出配置信息。
3. 业务处理层
业务处理层是整个爬虫系统的核心,可分成多台应用 服务器 进行处理。业务处理层主要包含解决两件事情。
(1) 如何获取url
对于爬虫来说,如何获取url至关重要。我们将这一过程定义为发现系统。对于发现系统而言,目标为如何发现待抓取网站的详细url列表,尽可能的发现更全。
a 假设场景 A
我们逛一个电商网站:打开首页-打开分类页-可能会有多层分类页-逐层点击-直至最小的分类页面。
打开这个分类页会发现该分类页下的所有分页页面,一页一页往下翻,就能够获得该分类页的所有商品。
b 假设场景 B
我们逛一个汽车网站:打开首页-找到品牌页-接着找到车系-最后找到车款页面。
通过以上场景分析可以得到一个结论,人能非常智能的找到所有待抓取的详细页面,即电商的商品,汽车的车款页面。那么,是否可以通过配置方式来模拟这一过程呢?
请看下图:
备注如下:
*root_info:
定义发现模块的入口页面,如同人打开汽车站的网页,后续的发现都是起始于这些入口页。
这里给出的实例是,某汽车网的品牌列表页,根据“模板化”套用变量的配置,共有100个入口页。
依次遍历这100个入口页,分别会执行steps中定义的步骤。机器模拟人的方式进行查看浏览。
每个step中,会使用”link_module”定义的类进行逻辑进行处理。
此处,即”last_step”为true中发现的url,即为发现系统最终需要获取的url列表。发现系统总结,通过配置的方式,结合人类的浏览习惯,通过若干步迭代,最终获取网站的详细页url列表。
由于每一步的抽取链接规则,以及步数据都是人为定义,因此,可以适配绝大部分网站的发现系统。当然,越复杂的网站发现配置可能更多一些、更为繁杂,但万变不离其宗。
2. 得到url后,如何处理
前提当然是每个业务的处理各不相同,有抽取页面属性功能、有正文提取、有图片获取,甚至有和当前系统对接等。
由于业务处理不一致,很自然想到的是通过配置方式,定义职责链系统,如同著名框架Netty中的Pipeline设计。在处理过程中,定义一个Context上下文处理类,并且,所有的中间结果都暂缓在这个Context中。
描述比较空洞,还是结合实际案例来看。
备注如下:
得到一个url后,读取配置,当url和”site”匹配时,适用当前”site”规则。
* pipeline定义职责链的处理过程
此处的定义为“抓取模块,Javascript处理模块,通用解析模块”。对应的处理如下:
先执行抓取模块,得到html。紧接着执行Javascript处理模块,输入为html,解析html,此处可能是评论,也可能是价格,总之处理的是动态加载项目,紧接着处理“通用解析模块”
* “parser_rules”定义的是解析模块
最终输出的是kv,在java中是map,python中是dict。即从上一步的html中,找到每一荐的”sizzle”,执行”prefix”,”suffix”即前后缀移除(过滤如同“价格:xxx元,前缀为“价格:”,后缀为元)。
对了,sizzle也是一个开源技术,据说以前鼎鼎有名的Jquery也是”sizzle”引擎。Java中可以使用Jsoup解析处理。
怎么知道需要取的”sizzle”内容是什么呢?具体可以结合firebug插件,选中即可得。选中后,结合应用层的管理工具,即可进行测试。
* “isrequire”
可以看到,配置项中有“isrequire”,表示这项内容是否必须。如果必须,且在实际处理中获取不到,那么在抓取的过程中,就会记录一个错误, 错误原因自然是“$key is null”。此外,每一个module都可能出错,一旦出错,就没有必要往后去执行。
因此,在抓取过程中,业务处理层从服务层获得一批url(默认100个)后,在处理这一百个url结束后,会向服层report,report内容为:
| 当前任务处理机器,于什么时间处理100个页面。不同网站成功多少、失败多少、什么模块失败多少,解析模块什么字段失败多少。 |
所有这些信息,均是实时统计,并在运营监控系统中以图表形示绘制出来,必要时可以发出报警,交由维护人员实时干预。
Q: 提一个问题,新增一个anotherauto.com网站怎么办?
A: 其实也很简单,再增加一个配置呗。业务定义pipeline,如果有解析需求,填写对应的解析项即可。
以上两个系统,发现系统和处理系统,在我们实际生产中,是通过以下步骤贯穿。
待抓取的列表根据业务的优先级,分普通队列及优先级队列,通过任务调度系统进行统一管理和配置。
4. 调度层
 四、系统架构设计
四、系统架构设计
五、图例
戳这里,看该作者更多好文
大数据分析培训哪个机构好?
在众多大数据分析培训机构中,推荐上海尚学堂,下面介绍上海尚学堂大数据分析培训机构中脱颖而出的优势:
1、上海尚学堂2006年2月16日成立,14年风雨兼程,尚学堂早已桃李满天下,数十万参与培训的学员如今已然奋战在IT行业第一线。 现旗下业务覆盖:JAVA开发技术培训、让人人享有高品质教育高级架构师培训、大数据云计算培训、人工智能python培训、Web前端培训。 现有校区遍布全国,上海、北京。
2、上海尚学堂在成都、 太原等拥有14个校区。 公司以助力学员跨入IT领域,为IT人才提供就业服务为宗旨,打造高端复合型人才。 师资实战团队高达240人,学员遍布全球海内外,受益千万学员。 至今就业合作企业数量已达1000+,让人人享有高品质教育同时,为中国的IT人才全力护航。 推出线上视频,下载量累积破2.3亿次。
3、毕设实战项目,真正实现1+1>10的目标效果。 我们将继续以“专注、创新、共享、育人”为核心,在IT领域披荆斩棘, 让人人享有高品质教育同时,让人人享有高品质教育为中国的IT人才全力护航。 每年有数百万名学员受益于千锋教育组织的技术研讨会、技术培训课、网络公开课及免费教学视频。
4、教学大纲紧跟企业需求,并推出软考、Adobe认证、PMP认证、红帽RHCE认证课程,拥有全国一体化就业保障服务,成为学员信赖的IT职业教育品牌。 让人人享有高品质教育同时,为中国的IT人才全力护航。 PHP全栈+服务器集群培训、网络安全培训、互联网营销培训,采用全程面授高品质、高体验培养模式,教学大纲紧跟企业需求。
5、并推出软考、Adobe认证、PMP认证、红帽RHCE认证课程,教学大纲紧跟企业需求,并推出软考、Adobe认证、PMP认证、红帽RHCE认证课程,让人人享有高品质教育同时,为中国的IT人才全力护航。 拥有全国一体化就业保障服务,成为学员信赖的IT职业教育品牌。 拥有全国一体化就业保障服务,成为学员信赖的IT职业教育品牌。
大数据专业的发展前景怎么样?
前景很不错。 一方面国家大力支持大数据行业的发展,已经上升为国际战略的今天,大数据人才正在拥有更多的发展机会。 另一方面许多的领域都是缺乏这方面的人才,腾讯阿里等互联网大厂都是高薪招聘相关人才。
大数据的择业岗位有:
1、大数据开发方向; 所涉及的职业岗位为:大数据工程师、大数据维护工程师、大数据研发工程师、大数据架构师等;
2、数据挖掘、数据分析和机器学习方向; 所涉及的职业岗位为:大数据分析师、大数据高级工程师、大数据分析师专家、大数据挖掘师、大数据算法师等;
3、大数据运维和云计算方向;对应岗位:大数据运维工程师。
大数据学习内容主要有:
①JavaSE核心技术;
②Hadoop平台核心技术、Hive开发、HBase开发;
③Spark相关技术、scala基本编程;
④掌握Python基本使用、核心库的使用、Python爬虫、简单数据分析;理解Python机器学习;
⑤大数据项目开发实战,大数据系统管理优化等。
想要系统学习,你可以考察对比一下开设有IT专业的热门学校,好的学校拥有根据当下企业需求自主研发课程的能,南京北大青鸟、中博软件学院、南京课工场等都是不错的选择,建议实地考察对比一下。
祝你学有所成,望采纳。
大数据开发和大数据分析哪个待遇好?
大数据专业工资多少薪资待遇好不好大数据工作月薪多少作为IT类职业中的“大熊猫”,大数据工程师的收入待遇可以说达到了同类的顶级。 国内IT、通讯、行业招聘中,有10%都是和大数据相关的,且比例还在上升。
大数据工资标准是怎样的大数据应届生工资大数据专业应届生的工资水平一般在8K-10K之间,如果说学历高,比如硕士,或者学得好,可能能拿到13K,基本就没有比这个再高的了。
最低工资10K-15K,最高工资无法确定。
大数据和数据分析哪个好数据建模分析师的就业潜力巨大,可以从事互联网或者经融行业的工作,大数据分析师只能从事互联网的工作,数据建模分析师的就业前景更好。
两个岗位完全不同。 数据分析师是用数据的。 数据工程师是把数据汇聚起来的。 不过非要说好的话,数据分析师是比较好的。 数据工程师对演算法有相当好的理解。 因此,数据工程师理应能运行基本数据模型。
Hadoop大数据开发方向市场需求旺盛,大数据培训的主体,目前IT培训机构的重点。 对应岗位:大数据开发工程师、爬虫工程师、数据分析师等。
大数据分析好。 数据分析是数据价值化的主要手段,所以从这个角度来看,学习数据分析似乎有更好的就业前景,而大数据运维都需要考网络方面的,比较难。 大数据分析是指对规模巨大的数据进行采集、存储、管理和分析。
大数据开发和大数据分析学哪个比较好?1、大数据开发是目前一个就业的热门方向,一方面是大数据开发的场景众多,另一方面是难度并不高,能够接纳的从业人数也非常多。 大数据开发是在大数据平台基础之上的开发,充分利用大数据平台提供的功能来满足企业的实际需求。
2、数据分析师的工作性质和开发工程师的就不一样,虽然他接到的项目和工程师差不多的,但是在实战中,更加关注的是数据分析师的随机应变的能力。
3、大数据不是职位,学完大数据认证后你可以从事大数据挖掘专家,高级行业分析师,大数据业务架构师,大数据架构师,大数据算法工程师,大数据开发工程师,大数据运维工程师。 不管是国内还是国外,大数据相关的人才都是供不应求的局面。
大数据开发和数据分析哪个前景更好哪个薪资高
1、Hadoop大数据开发方向市场需求旺盛,大数据培训的主体,目前IT培训机构的重点。 对应岗位:大数据开发工程师、爬虫工程师、数据分析师等。
2、在美国,大数据工程师平均每年薪酬高达15万美元。 大数据开发工程师在一线城市和大数据发展城市的薪资是比较高的。
3、看个人具体情况。 大数据开发和大数据分析两个行业都还不错,编程能力弱一些,但是对业务的理解能力还可以的话,其可以选择数据分析。
4、大数据开发是目前一个就业的热门方向,一方面是大数据开发的场景众多,另一方面是难度并不高,能够接纳的从业人数也非常多。 大数据开发是在大数据平台基础之上的开发,充分利用大数据平台提供的功能来满足企业的实际需求。
5、两个岗位完全不同。 数据分析师是用数据的。 数据工程师是把数据汇聚起来的。 不过非要说好的话,数据分析师是比较好的。 数据工程师对演算法有相当好的理解。 因此,数据工程师理应能运行基本数据模型。












发表评论