
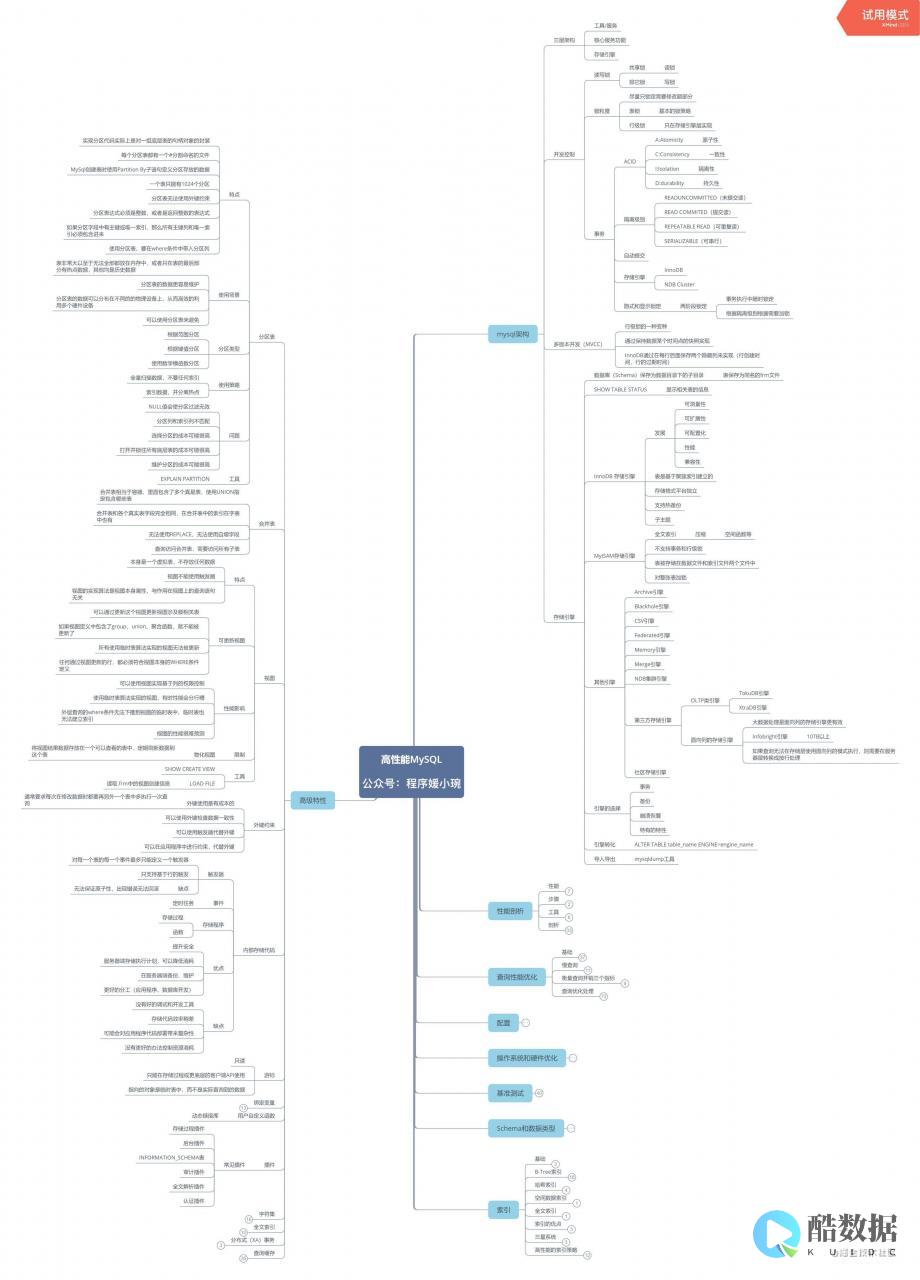
如果要在MySQL查询结果集中得到记录行号,应该如何实现呢?下面就为您介绍一个MySQL查询结果集中得到记录行号的方法,希望对您能有所启迪。
在计算某特定记录在查询结果中的位置用到。
如果需要在查询语句返回的列中包含一列表示该条记录在整个MySQL查询结果集中的行号, ISO SQL:2003 标准提出的方法是提供 ROW_NUMBER() / RANK() 函数。 Oracle 中可以使用标准方法(8i版本以上),也可以使用非标准的 ROWNUM ; MS SQL Server 则在 2005 版本中提供了 ROW_NUMBER() 函数;但在 MySQL 中似乎还没有这样的系统自带功能。虽然 LIMIT 可以很方便的对返回的结果集数量和位置进行过滤,但过滤出来的记录的行号却没办法被 SELECT 到。据说 MySQL 是早就想增加这个功能了,但我是还没找到。
解决方法是通过预定义用户变量来实现:
这样查询出来的结果集中 ROWNUM 就保存了行编号信息。这个行编号信息的某种用途在于当你需要根据需要对数据按照某种规则排序并取出排序之后的某一行数据,并且希望知道这行数据在之前排序中的位置时就用得着了。比如:
当然你也可以通过创建临时表的方法把查询结果写到某个拥有 auto_increment 字段的临时表中再做查询,但考虑到临时表在 MySQL master / slave 模式下可能产生的问题,用这样临时用户定义变量的方式来计算查询结果集每一行对应的行号还是更为简洁 — 除非你愿意在 PHP 或其他语言脚本中对返回的整个结果集再作处理。
【编辑推荐】
MySQL随机查询的实现方法
MySQL查询分页的优化
用变量实现MySQL查询行号
MySQL查询结果按某值排序
MySQL查询中的非空问题
sql统计个数问题
就是分组统计,使用GROUP BY就可以得到。select 缴费类型, sum(金额) as 总金额FROM 表group by 缴费类型
关于SQL Server 中两个查询结果相减的问题(仓库货物收、发,求现存数量)。
一张表里边,同一地区、同一货物只是有收、发两条记录么?是否可能有这样的情况:2011-3-2 天河区收 B -3-4 天河区收 B-3-6 天河区发 B 70建议将“收”改为1,“发”改为-1,这样直接用数量与之相乘,在使用Sum()即可












发表评论