最新 一文搞懂Hadoop生态系统
01Hadoop概述Hadoop体系也是一个计算框架,在这个框架下,可以使用一种简单的编程模式,通过多台计算机构成的集群,分布式处理大数据集,Hadoop是可扩展的,它可以方便地从单一服务器扩展到数千台服务器,每台服务器进行本地计算和存储,除了依赖于硬件交付的高可用性,软件库本身也提供数据保护,并可以在应用层做失败处理,从而在计算机集...。

01Hadoop概述Hadoop体系也是一个计算框架,在这个框架下,可以使用一种简单的编程模式,通过多台计算机构成的集群,分布式处理大数据集,Hadoop是可扩展的,它可以方便地从单一服务器扩展到数千台服务器,每台服务器进行本地计算和存储,除了依赖于硬件交付的高可用性,软件库本身也提供数据保护,并可以在应用层做失败处理,从而在计算机集...。

概述hbase是一个构建在hdfs上的分布式列存储系统;hbase是基于googlebigtable模型开发的,典型的key,value系统;hbase是apachehadoop生态系统中的重要一员,主要用于海量结构化数据存储;从逻辑上讲,hbase将数据按照表、行和列进行存储,与hadoop一样,hbase目标主要依靠横向扩展,通过...。

ClouderaLinux是一个基于ApacheHadoop的数据管理和分析平台,由Hadoop的创始人和早期贡献者于2008年创立,它提供了企业级的解决方案,帮助企业更好地利用Hadoop生态系统进行大数据处理,1、ClouderaLinux简介ClouderaLinux是由Cloudera公司开发的一种企业级Linux发行版,专为...。

在现代大数据分析的时代,数据提取和处理是至关重要的一步,其中,如何从Oracle数据库中提取数据并将其转移到其他基于Hadoop的分布式计算系统中已成为数据工程师必备的技能之一,为了更好地满足这一需求,SQOOP成为了一款备受欢迎的数据提取工具,什么是SQOOPSQOOP是一款开源软件,是ApacheHadoop生态系统中的重要组成部...。

随着数码化时代的到来,人们对数据存储和分析的需求越来越高,而Hadoop生态系统,HadoopDistributedFileSystem,提供了一个可扩展且能够处理海量数据的方法,它不仅支持常见的数据格式,如文本和XML,还能支持任何格式的数据,包括关系型数据库,MySQL是一种非常流行的关系型数据库,使用广泛,但是对于需要在HDFS...。

Cloudera大数据培训提供了全面且结构化的课程,涵盖从基础知识到高级应用的各个层面,为学员提供了深入理解和应用大数据技术的宝贵机会,...。

大数据流处理,Flume、Kafka和NiFi对比2019,07,0512,16,26在构建大数据流水线时,我们需要考虑处理数据的数量,种类和速度,这些数据通常出现在Hadoop生态系统的入口,在构建大数据流水线时,我们需要考虑处理数据的数量,种类和速度,这些数据通常出现在Hadoop生态系统的入口,在决定采用哪种工具来满足我们的要求...。
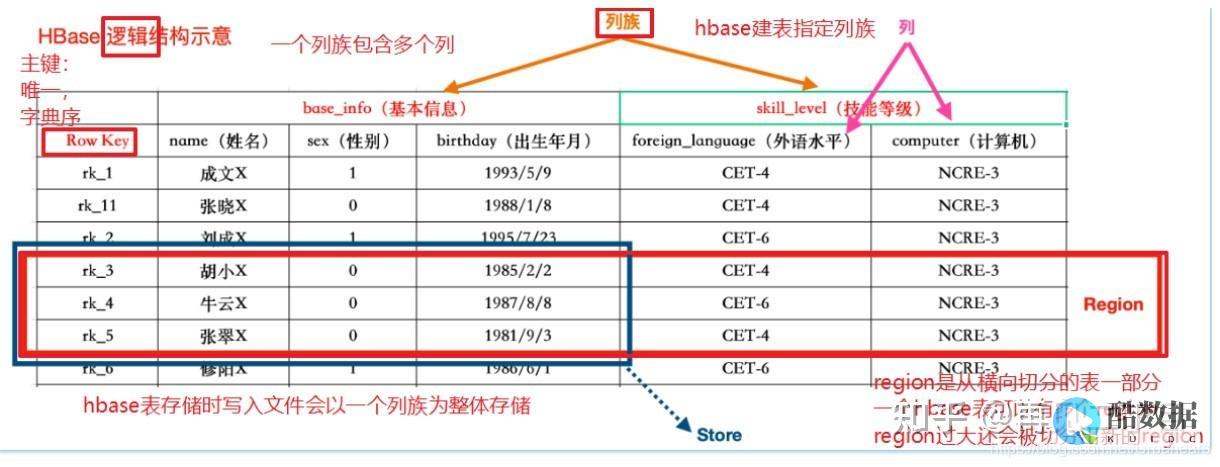
HBase是一个分布式的、可扩展的、基于列的数据库系统。在Hadoop生态系统中,它属于NoSQL数据库的一类,类似于Google的Bigtable。HBase是基于Hadoop的HDFS存储系统构建的,具有高可用、高可靠性和高可扩展性等特点。HBase数据库架构HBase数据库使用的是基于键值对的数据库结构,它的基本单元是一个表格。...