
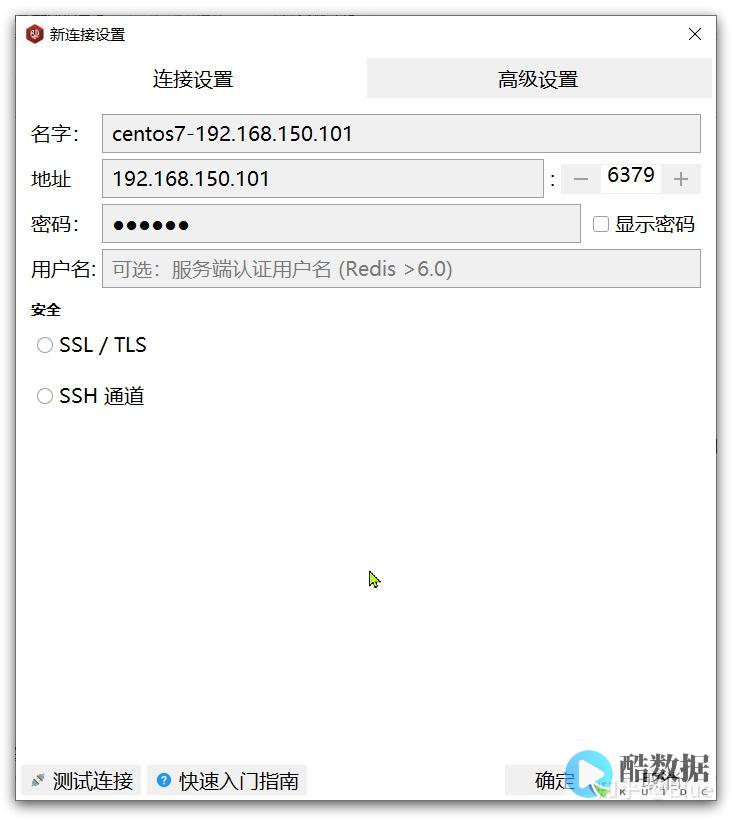
精准掌控:用Redis缓存提高性能
在当今互联网时代,性能是应用程序设计过程中不可或缺的重要因素。面对越来越多的用户和数据访问,如何提高应用程序的性能成为了每个开发者面临的挑战。为了解决这个问题,Redis缓存应运而生。Redis是一款开源的高性能键值对数据库,自带数据结构和丰富的功能。
下面我们将从Redis缓存的基本原理、在Web应用中的实践和实际应用效果三个方面来讲述如何用Redis提高应用性能。
一、Redis缓存的基本原理
Redis缓存主要是通过将常用的数据存储在内存中,减少对数据库的查询次数来提高应用程序的性能。如图所示,在Web应用访问时,Redis作为一个中间件,负责将热点数据通过一组键值对的方式存储在内存中,当应用程序需要查询数据时,能够快速响应数据请求。因为Redis数据存储在内存中,相对于关系型数据库的磁盘存储,所以可以极大地提高数据访问速度。
二、在Web应用中的实践
在Web应用中,我们可以使用Redis缓存来提高数据的读写速度和并发处理能力。下面是一个简单的例子,通过使用Redis缓存,我们实现了一个用户登录模块。当用户输入账户和密码,系统先检查缓存中是否有用户信息,如果有则直接返回缓存中的数据,否则查询数据库并存入缓存中。
import redis
# 连接Redis数据库
r = redis.Redis(host=’localhost’, port=6379, db=0)
def check_user(username, password):
# 从缓存中获取用户信息
user_info = r.get(username)
if not user_info:
# 查询数据库
user_info = query_database(username, password)
# 将用户信息写入缓存
r.set(username, user_info)
return user_info
三、实际应用效果在实际应用中,Redis缓存能够带来显著的性能提升。以一个在线商城Web应用为例,我们通过为商品信息添加Redis缓存,可以明显地提升Web应用的响应速度和用户体验。我们要求用户进入首页时能够快速展示商品列表,于是我们引入了Redis缓存来优化数据读写速度。在Web应用中,将商品数据存入Redis缓存中,当用户需要查询商品信息时,先在缓存中进行查询,如果缓存中没有该商品信息,再从数据库中查询。在用户访问量较大的情况下,Redis缓存可以减少数据库查询次数,提高数据访问速度,同时也减轻了数据库的访问压力。```python# 获取商品详细信息def get_product_info(product_id):# 从缓存中获取商品信息product_info = r.get('product_info_'+str(product_id))if not product_info:# 查询数据库product_info = query_database(product_id)# 将商品信息写入缓存,有效时间为1小时r.set('product_info_'+str(product_id), product_info, ex=3600)return product_info

总结
Redis缓存在Web应用中的使用能够提高应用程序的性能和用户体验。在实际开发中,我们可以通过将常用的数据存储在Redis缓存中,减少对数据库的查询次数来提高应用程序的性能。
需要注意的是,缓存技术并不能解决所有问题。在应用缓存时,需要考虑合理使用缓存策略、缓存容量和缓存生命周期等,避免缓存数据过期或缓存数据不一致等问题。当我们合理使用Redis缓存时,能够让应用程序快速响应用户请求,提高用户体验,实现精准掌控。
香港服务器首选树叶云,2H2G首月10元开通。树叶云(shuyeidc.com)提供简单好用,价格厚道的香港/美国云 服务器 和独立服务器。IDC+ISP+ICP资质。ARIN和APNIC会员。成熟技术团队15年行业经验。
memcached可以持久化吗
memcached 是缓存系统,通过名字就可以看出来,官网也明确说了(Free & open Source, high-performance, distributed memory object caching system),之所以是缓存系统,就说明它不会作为可靠的数据存储,所以并不支持持久化。 另一个是redis,他是一个存储系统,官网也说了。 只不过redis是在内存中存储的,所以速度快,因为是存储系统,所以可以作为一个可靠的数据存储系统。 支持持久化。
酷睿I3 I5 I7 处理器的超线程什么意思呢
CPU生产商为了提高CPU的性能,通常做法是提高CPU的时钟频率和增加缓存容量。不过目前CPU的频率越来越快,如果再通过提升CPU频率和增加缓存的方法来提高性能,往往会受到制造工艺上的限制以及成本过高的制约。尽管提高CPU的时钟频率和增加缓存容量后的确可以改善性能,但这样的CPU性能提高在技术上存在较大的难度。 实际上在应用中基于很多原因,CPU的执行单元都没有被充分使用。 如果CPU不能正常读取数据(总线/内存的瓶颈),其执行单元利用率会明显下降。 另外就是目前大多数执行线程缺乏ILP(Instruction-Level Parallelism,多种指令同时执行)支持。 这些都造成了目前CPU的性能没有得到全部的发挥。 因此,Intel则采用另一个思路去提高CPU的性能,让CPU可以同时执行多重线程,就能够让CPU发挥更大效率,即所谓“超线程(Hyper-Threading,简称“HT”)”技术。 超线程技术就是利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了CPU的闲置时间,提高的CPU的运行效率。
采用超线程及时可在同一时间里,应用程序可以使用芯片的不同部分。 虽然单线程芯片每秒钟能够处理成千上万条指令,但是在任一时刻只能够对一条指令进行操作。 而超线程技术可以使芯片同时进行多线程处理,使芯片性能得到提升。
超线程技术是在一颗CPU同时执行多个程序而共同分享一颗CPU内的资源,理论上要像两颗CPU一样在同一时间执行两个线程,P4处理器需要多加入一个Logical CPU Pointer(逻辑处理单元)。 因此新一代的P4 HT的die的面积比以往的P4增大了5%。 而其余部分如ALU(整数运算单元)、FPU(浮点运算单元)、L2 Cache(二级缓存)则保持不变,这些部分是被分享的。
虽然采用超线程技术能同时执行两个线程,但它并不象两个真正的CPU那样,每各CPU都具有独立的资源。 当两个线程都同时需要某一个资源时,其中一个要暂时停止,并让出资源,直到这些资源闲置后才能继续。 因此超线程的性能并不等于两颗CPU的性能。
英特尔P4 超线程有两个运行模式,Single Task Mode(单任务模式)及Multi Task Mode(多任务模式),当程序不支持Multi-Processing(多处理器作业)时,系统会停止其中一个逻辑CPU的运行,把资源集中于单个逻辑CPU中,让单线程程序不会因其中一个逻辑CPU闲置而减低性能,但由于被停止运行的逻辑CPU还是会等待工作,占用一定的资源,因此Hyper-Threading CPU运行Single Task Mode程序模式时,有可能达不到不带超线程功能的CPU性能,但性能差距不会太大。 也就是说,当运行单线程运用软件时,超线程技术甚至会降低系统性能,尤其在多线程操作系统运行单线程软件时容易出现此问题。
需要注意的是,含有超线程技术的CPU需要芯片组、软件支持,才能比较理想的发挥该项技术的优势。 目前支持超线程技术的芯片组包括如:英特尔i845GE、PE及矽统iSR658 RDRAM、SiS645DX、SiS651可直接支持超线程;英特尔i845E、i850E通过升级BIOS后可支持;威盛P4X400、P4X400A可支持,但未获得正式授权。 操作系统如:Microsoft Windows XP、Microsoft Windows 2003,Linux kernel 2.4.x以后的版本也支持超线程技术。
如何理解而value对于Redis来说是一个字节数组,Redis并不知道value中存储的是什么
Redis不仅仅是一个简单的key-value内存数据库,Redis官网对自身的定义是“数据结构服务器”。
通过用心设计各种数据结构类型的数据存储,可以实现部分的数据查询功能。
因为在Redis的设计中,key是一切,对于Redis是可见的,而value对于Redis来说就是一个字节数组,Redis并不知道你的value中存储的是什么,所以要想实现比如‘select * from users where =shanghai’这样的查询,在Redis是没办法通过value进行比较得出结果的。
但是可以通过不同的数据结构类型来做到这一点。
比如如下的数据定义users:1 {name:Jack,age:28,location:shanghai}users:2 {name:Frank,age:30,location:beijing}users:location:shanghai [1]其中users:1 users:2 分别定义了两个用户信息,通过Redis中的hash数据结构,而users:location:shanghai 记录了所有上海的用户id,通过集合数据结构实现。
这样通过两次简单的Redis命令调用就可以实现我们上面的查询。
Jedis jedis = ();Set











发表评论